相信刚开始接触微服务架构的朋友,都听过这条设计原则:不要让多个服务共享同一个数据库。
这条规则几乎成了微服务的标配忠告,类似的话到处都是:“两个服务千万别共用一个数据源。”听上去确实挺有道理:每个微服务应该有自己独立的数据管理权限,这样一来,服务内部要是调整了数据结构,也不会牵一发而动全身,波及外部 API。
这里需要强调的是:共享数据源 ≠ 共享数据。
1. 为什么共享数据源不可取?
先来说说,为什么在微服务架构里,共用一个数据库几乎是大忌。
打个比方,有个叫 Orders 的服务,负责下单、查订单状态、改收货地址之类的操作,它拥有自己的 orders 表,是这块业务数据的唯一“权威源头”(source of truth)。如果别的服务,比如 Shipping、User、Notification,需要订单信息,应该乖乖通过 Orders 服务的 API 来拿,像是 GET /orders/{id} 查详情。
为啥要绕这么一圈?因为这样做,Orders 服务就能自由调整自己的数据库结构,比如加索引、改字段名、拆表做归档,完全不用担心影响别人。只要 API 不变,后面的服务根本不用知道底下发生了什么,整个系统就能稳稳运行,大家各干各的,互不添乱。
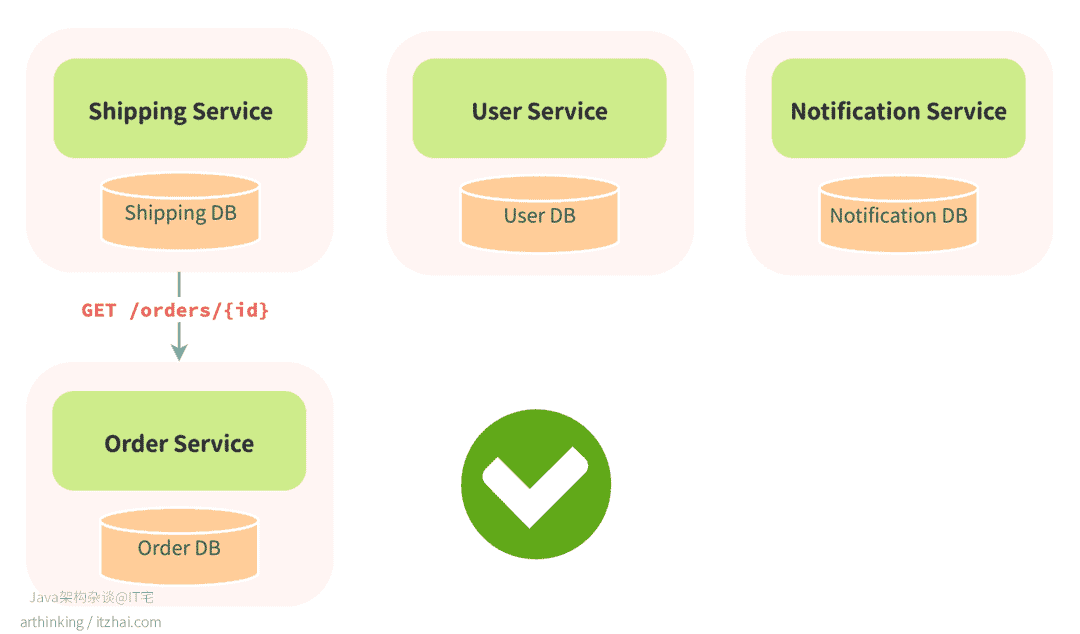
但问题就出在,一旦有服务图省事,绕过 API 直接连数据库查数据,这条“边界”就破了。哪怕只是读操作,只要多个服务开始依赖同一个表结构,那 Orders 服务以后改字段名、拆表之类的动作,就得先反复确认“有没有谁会被我影响到”。
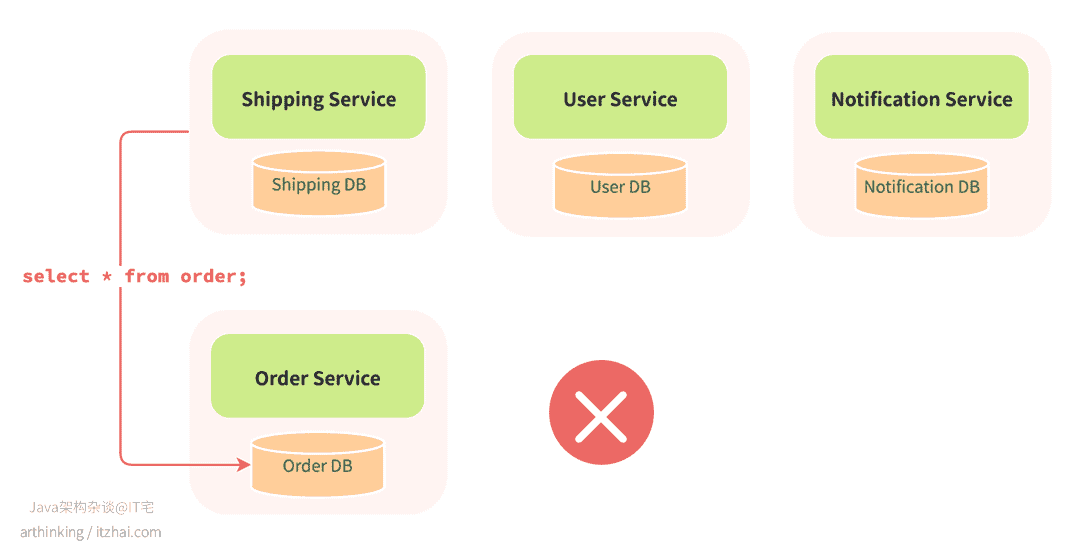
举个例子,虽然很少会去改数据库中的字段名,但是假设真的有些字段要调整,而系统里有个 Billing 服务,为了省事,直接连上了 Orders 的数据库算营收。结果某天我们把 orders.status 改成了 order_status,账务模块立马出问题,线上告警、数据错乱。
记住:数据库是服务的私产,别人要数据,就得敲门,不是翻墙。
2. 为什么共享数据是可以接受的?
“别共用数据库”这条规矩是要严格遵守的。而微服务之间共享数据本身再正常不过了。
想想看,一个 Feed 服务要生成首页的信息流,怎么可能绕得开用户和内容的信息?它得知道这篇帖子是谁发的、发帖人叫什么、头像长啥样、内容摘要要显示什么——可这些数据,大多都不是 Feed 自己维护的,而是分别由 User 和 Content 服务管理。
所以说,服务之间传递数据是常态,关键是怎么传。不是翻人家的数据库表,而是通过它们公开的接口,或者订阅它们的事件来拿。就像邻里之间借东西,敲个门、打声招呼,总比翻墙进屋显得有礼貌得多。
通过接口来获取数据,有明确的边界和契约,好处也很直接:
- User 服务可以安心改自己的表结构,不用担心影响别人;
- Feed 服务只关心接口返回值,逻辑上不被耦死;
- 数据依赖清晰透明,出问题也好排查定位;
- 系统整体变得松耦合、易演化、可治理。
每个服务守好边界、开好“借口”,既保护了自己,也成全了别人。只有这样,业务一旦扩展起来,系统才能稳得住、扩得开,不至于变成那种“动一发而全身痛”的紧耦合灾难现场。
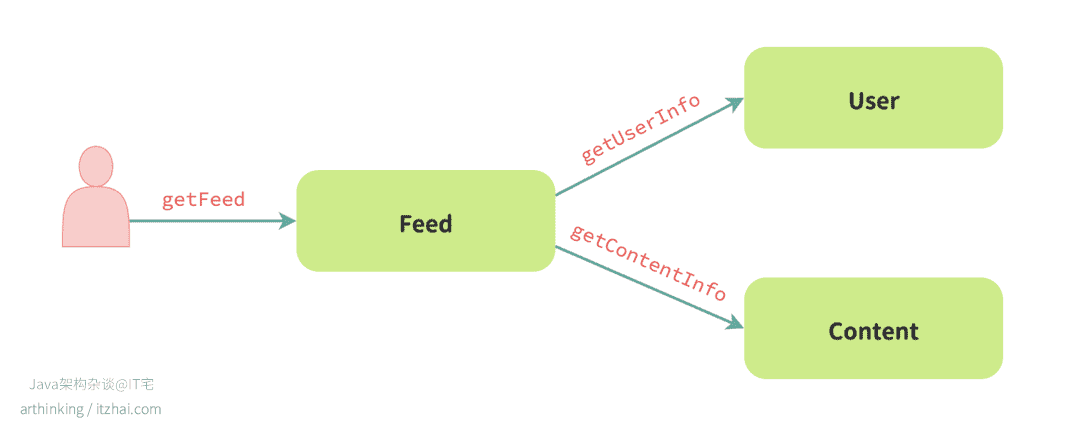
假设你在做一个内容平台,负责信息流的 Feed 服务。当客户端发起一个 getFeed 请求时,它得展示一堆帖子。可光有帖子 ID 和标题远远不够,还得附上作者昵称和头像、帖子的摘要预览,才能让信息流看起来像个样子。
于是,Feed 服务就会同步向 User 服务拉取作者信息,同时向 Content 服务获取帖子详情。
这种做法的好处一目了然:数据绝对新鲜,客户端拿到的是一个强一致性、结构完整 的内容视图。接口打通,一次搞定,前端不用东拼西凑,用户体验也顺滑得不行。
说实话,对刚接触微服务架构的团队来说,这种同步请求链条非常“顺理成章”。你知道头像在哪,就去 User 服务拿;内容在哪,就找 Content 服务查。查完拼一拼,数据全了,返回给客户端,任务完成。
刚实施微服务的团队很容易这么干,而且干得无比坚定,几乎是“信仰式”地认为:用户看到的,必须是此时此刻的真相。中间缓存?副本同步?这些统统被我们视作风险,是“不得已”的技术妥协。只有实时查“唯一权威源”,才配叫工程质量。
所以在最初设计的时候,往往压根没讨论,直接拍板用同步调用。它逻辑清晰,接口分明,看上去也干净漂亮,真心觉得:这就是真正的微服务架构应有的样子。
3. 同步与强一致性无法扩展
同步调用、强一致性听起来确实很美好,谁不喜欢“张口一问,数据立马奉上”的理想状态?但真把整个架构都堆在这套逻辑上,往往就是在给自己埋雷。现实是,你既做不到每次都实时查源服务,也根本没这个必要。
回顾下前面那个 Feed 服务的例子?最初看起来确实很优雅:从 User 服务拿作者信息,从 Content 服务拉帖子详情,调用链清晰、数据一致,甚至和架构图上的连线一模一样,像是设计出来就能落地运行。
但别忘了,系统不是画图画出来的,是在业务压力下被堆、被拧、被拼出来的。
一旦业务扩展,新服务、新需求纷至沓来:广告服务要插广告位、推荐服务要查内容权重、风控要监测可疑账号……他们全都得接入用户信息、内容摘要等数据。这时候如果还死守“谁是权威源就必须去问谁要”的原则,后果就是:系统迅速变成一张错综复杂的同步调用蜘蛛网。
每个服务为了拼出一个响应结果,不得不连上三五个其他服务。一个看似简单的 getFeed 请求,背后可能触发五六次甚至更多的网络调用。只要其中一个服务稍有不稳,比如超时、降级、限流重试……链路就崩了。用户这边,看到的就是页面一直转圈,最后冒出一句“系统异常,请稍后再试”。
下面举个例子,看看系统是如何被拖垮的。
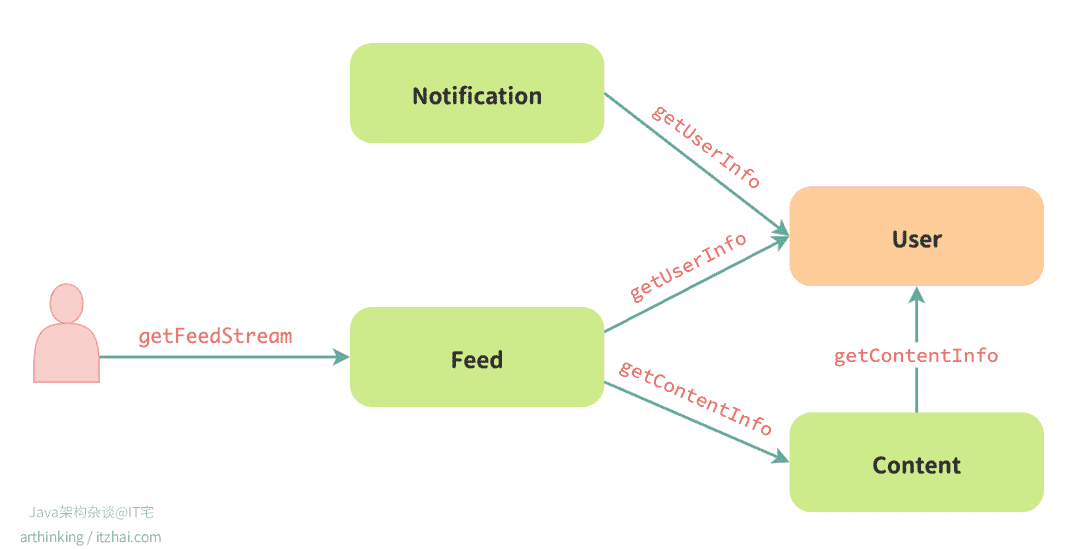
- 用户打开 App 首页,发起了 Feed 服务的
getFeedStream请求。 - Feed 服务先从 Content 服务拉回推荐帖子列表。
- 接着,为了展示作者昵称和头像,它又同步调用了 User 服务。
- 页面加载完成后,用户点了个赞,于是 Feed 服务发出
likeContent请求。 - 为了“提醒作者有人点赞”,系统又调用 Notification 服务发推送。
- 而 Notification 为了发送私信,还得再去找 User 服务,获取作者的接收设置、联系方式等信息。
听上去一切分工明确、数据权威、查得现场,简直像是“微服务的标准教科书实践”。但现实却是:User 服务成了整个链路的“生命中枢”。
不管是谁,只要想展示点跟用户有关的东西,就得去问它要:头像、昵称、邮箱、消息配置……几乎所有关于“人”的信息请求,全都压在了这一个服务身上。只要它稍微喘口气——头像加载不了、点赞卡住、通知延迟,轻则影响体验,重则直接报错崩溃。
为了撑住这个“高频冲击中心”,我们只好不断“打补丁”:加节点、建缓存、搞多活、做分离、冷热分层……每一项都真金白银地烧,系统负担越来越重。而且,这还不是一次搞定的事,一旦放松维护,它就随时可能变回性能瓶颈。
更要命的是——链条一长,延迟就像雪球一样越滚越大。一次简单的首页加载请求,背后可能走了 Feed → Content → User → Notification → User 这样一圈。每跳一次,都要等下游响应;每多一个环节,就多一个可能出错的点。
别忘了:请求链是会“吞掉”你的可用性的。就算每个服务单体 SLA 都有 99.9%,看上去还不错?可一旦串成链,比如 5 个服务连起来,整体 SLA 直接掉到 99.5%,一年大约就是 44 小时的不可用时间。
4. 昵称头像非得实时查?拆掉你的 User 中心读瓶颈
有朋友就会问了,微服务不就是把不同的职责放到恰当的服务中吗?需用用户数据,那就去用户服务取,看起来也没啥问题?
这个质疑很正常, “用户数据归用户服务管,其他服务有需要就来调,不就是微服务该有的样子吗?”
核心在于: “写的权威归属” ≠ “所有读流量都实时集中到权威服务”。后者在规模上就是一个典型的“中心化读瓶颈 / User God Service” 反模式。我们拆开看:什么时候它是“合理的抽象”,什么时候它会演化成“系统脆弱点”。
很多人一听“做副本”,脑子里立刻蹦出“数据不一致”“多源写”这些词,心里咯噔一下。其实,这事真没那么极端。用户服务确实得当“权威源”,但也不是啥都非得它说了算。关键是搞清楚:什么东西必须它管,什么东西能分出去。
4.1 哪些字段必须“集中写”?
有些东西必须保证唯一、准确、实时可控,这时候就要“只让用户服务说了算”。比如:
- 用户认证信息(ID、token、密码哈希)
- 合规字段(实名状态、KYC 等)
- 安全策略(登录状态、风控标签)
- 写事务(注册、资料更新、合规日志等)
这些字段必须有“唯一的入口”和“原子性的处理逻辑”。否则,写冲突、权限漏洞、合规事故就来了。
4.2 什么时候开始“不合理”?
问题往往出现在“所有字段都要实时从 User 拉”。尤其是头像、昵称这类展示字段,也要走同步链路的时候,就很容易出问题:
- 下游十几个服务都直接打到 User(扇出)
- QPS 一半被头像补齐撑起来
- 缓存撕裂、后端突刺、响应延迟拉垮整条链路
- 一改字段,N 个下游挂掉,风险策略改动如多米诺骨牌
到这一步,User 服务已经从“领域边界的守门员”,变成了最容易影响服务可用性的地方了。
4.3 实际上问题在哪?是“访问模式”错了
不是说集中写就错,而是 读写没分开。
- 像头像、昵称这种字段:读频高、写很少,10 分钟延迟用户都没感觉
- 像权限变更、风控策略:秒级生效才靠谱
为了满足个别“必须实时”的场景,把所有字段都绑上同步链,成本很高,收益很低。
4.4 那“副本”是不是破坏边界?
不是。只要你不搞“多源写”,副本反而能帮你隔离风险。
| 错的共享方式 | 正确的副本方式 |
|---|---|
| 下游服务跨库直查 | 上游用事件/API/CDC 推送 |
| 谁都能用、没人维护 | 有版本管理、有过期监控 |
| 全字段照抄 | 只拷贝热门、低敏、低变更字段 |
| 拼装字段、猜模型 | 投影成稳定只读结构 |
| 允许回写 | 明确禁止下游写回 |
这更像是 Materialized View(物化视图):写集中、读分发、结构稳定、逻辑只读。
4.5 判断标准:要不要实时查?
这里通过表格列了一些常用的场景,判断要不要实时查询:
| 字段类型 | 示例 | 要求实时查主源? | 推荐策略 |
|---|---|---|---|
| 安全控制 | 风控标签、封禁状态 | 必须 | 实时查询 + 秒级缓存 |
| 写后一致读 | 修改密码后展示 | 大多数需要 | 写库直查或延迟拉取 |
| 高频展示 | 昵称、头像、地区 | 不需要 | 副本滞后几分钟无感 |
| 聚合类 | 点赞数、关注数 | 不需要 | 弱一致副本 / 延迟刷新 |
| 偏好类 | 屏蔽分类、语言设置 | 可容忍滞后 | 增量补偿 / 周期拉取 |
4.6 服务一般演进路径:从 “直查权威表” 到 “事件驱动预合成”
一般来说,服务查询一般都会经过如下演进。
| 阶段 | 特征 | 问题 | 下一步 |
|---|---|---|---|
| V1 | 所有字段 GET /user | user 撑不住 | 加缓存或字段白名单 |
| V2 | Redis 缓存 | 命中差,缓存雪崩 | 引入事件驱动 |
| V3 | user_snapshot 表 | 缺监控 | 加滞后报警 + 补偿 |
| V4 | 多投影视图 | 多表维护复杂 | Schema 版本化 + Outbox |
| V5 | 读聚合层(BFF) | 查询链冗长 | 引入预合成视图 |
4.7 有哪些“真能落地”的做法?
一些在实际生产环境中反复验证、真正靠谱的方案:
- 副本读失败就回退主库:副本挂了别慌,自动切回主库兜底,保障核心流程不断。
- UPSERT 时加版本号防乱序:避免并发更新带来的数据覆盖问题,让写入逻辑更稳。
- 记录变更日志,支持事件重放:每次数据变更都留痕,后续可以做补偿、审计或重放。
- 监控滞后指标(如 snapshot 延迟):用秒级延迟监控数据是否“掉队”,早发现早处理。
- 主服务挂了就读过期副本(附提示):宁可用点旧数据,也别全系统停掉,用户能理解。
- 批量拉取 + 请求合并:减少请求次数、减轻后端压力,是高并发场景下的常规操作。
- 热点数据 Top K 缓存 + 分片刷新:先把最常用的内容“顶上去”,再分片更新,省资源又稳定。
- 限流 + 主服务读写线程池隔离:避免读写互相干扰,一旦某类请求爆炸,也不会带崩全系统。
4.8 不复制会怎样?
我们算一笔账。
假设:
- User P99 响应 40ms
- 下游链路串联调用 User 10 次(头像、状态、昵称…)
- SLA 每跳 99.9%,10 跳后整体 ≈ 99%
意味着什么?你系统的年度不可用时间,从 8 小时变成了 3 天多。
副本命中率一旦能做到 95%,延迟可以减少 20 倍,稳定性回升到 99.8%+。
用户服务本来只该专注在“该写就写、该控就控”上,结果所有人为了拿头像、昵称都来“顺手问一句”,问着问着,它就被拖成了“谁慢谁背锅”的性能瓶颈。真正的解法,不是打更多补丁,而是让低敏、低变更的展示类字段,有个靠谱的“只读副本”来接这类需求。
4.9 什么时候可以不急着改?
如果你现在这些指标都还在安全范围内,可以先观望:
| 指标 | 参考标准 |
|---|---|
| User QPS < 3k,1年内增长 < 3× | 安全余量足 |
| 平均调用链对 User 访问 ≤ 2 次 | 尚可 |
| User CPU < 40%,连接占用 < 60% | 可控 |
| 头像昵称缓存命中 ≥ 98% | 压力不大 |
| 最近事故归因 User 不在 Top3 | 不急着拆 |
一旦你踩线踩多了,那就该考虑副本化了。
5. 案例如何改进
说白了,我们需要的不是“实时一切”,而是“有弹性的更新策略”。
就像 Notification 服务,它确实要拿到用户最新的通知设置,否则一条不合时宜的推送就可能引起用户反感,甚至投诉。这类场景,要求的是真实、准确、时效——延迟越小越好。
但 Feed 服务那边,对时效性的要求就没那么高了。内容是“准静态”的,作者资料的更新频率也低得惊人。就算头像晚两个小时更新,绝大多数用户根本不会在意。更何况,哪怕头像错了,顶多是“认错人”,不会影响点赞、评论、分享这些核心功能。
换句话说,强一致性要用在刀刃上,别的地方只要“看起来对”就够用了。这就好比社交平台的点赞数——不是实时精确统计的,而是异步刷新的。用户看到的数字可能比真实值少一点点,但体验流畅了,系统压力小了,用户照样点得开心。
我们当时意识到这一点后,架构设计的心态也发生了转变:不是追求完美一致,而是按场景选策略。
- 实时推送?走同步查、加缓存、设降级。
- 首页展示?搞定副本同步,偶尔延迟一点也OK。
- 用户资料?用消息队列异步广播,再按需拉取。
这不是“偷懒”,而是一种更健康、更可扩展的思维方式。
通过引入“数据副本机制”:每个服务只保留自己所需的“子集数据”,定期同步源服务、保证足够新鲜。一来减轻了核心服务的查询压力,二来也让各个模块在面对下游波动时能更加独立、不容易连锁翻车。
这样,我们摆脱了“全链实时”的执念,迈向一个更可控、更弹性的系统架构。
不同服务对数据一致性的要求是不同的。
我们可以根据具体场景做权衡,采用不同的数据共享策略,从而构建一个更强健、更可扩展的分布式系统。
6. 引入最终一致性(Eventual Consistency)
其实服务完全可以在自己的数据库里,维护其他服务的数据副本。
当然,这种副本不是白来的。你既然决定把数据“拷贝”一份留在自己这边,就得承担起维护它的责任。比如订阅对方的事件(用 Kafka、RocketMQ 之类的中间件)、定期调用 API 拉增量数据,或者设置后台任务去同步更新。(当然,如果你只是要一个快照数据,压根不关心它最新的状态,那直接存下来就可以了。)
这套机制有个核心前提:**这些副本数据,不是实时的。**它们可能在某个时刻是“旧”的,甚至滞后一段时间才更新。但只要你设计得当,这些数据最终都会“跟上来”,我们把这种状态叫做:最终一致性(eventual consistency)。
它没法保证“此时此刻就是准确的”,但可以保证“在合理时间后,会变准确”。
继续虎回顾下前面的 Feed 服务。我们最早是每次展示帖子时,都实时从 User 服务拉作者头像和昵称。这样虽然数据新,但链路长,性能压力大。
我们可以做个调整:改成读本地副本。在 Feed 服务自己的数据库里建了一张 user_snapshot 表,缓存用户的基础信息。只要 User 服务那边有人改了昵称或头像,就会通过事件系统发出一个 UserProfileUpdated 事件,Feed 服务消费这个事件后,自动更新副本。
这改动带来的好处是立竿见影的:
- 首页加载再也不会因为 User 服务卡顿而崩了;
- 昵称头像就算延迟几分钟更新,用户也完全感知不到;
- 整个 Feed 系统的可用性、响应速度、扩展性,全都上了一个台阶。
说白了,我们做出了一个清晰的技术权衡:牺牲一点实时性,换来整个系统的稳定、解耦和可维护性。
回到我们前面提到的 Feed 场景:
同样的,让每个服务本地维护一份用户数据的副本,大幅减少对 User 服务的同步依赖,也终于摆脱了某个“请求一挂,全链瘫痪”的噩梦。
- Feed 服务:最直接的受益者。Feed 页展示的作者昵称、头像等基础信息,完全可以来自它自己维护的
user_snapshot表。没人会因为头像晚几分钟更新就崩溃。去掉对 User 服务的实时依赖后,页面加载又快又稳。 - Content 服务:帖子详情页也常要展示作者信息,比如“由 XXX 发布”。这些数据不必每次都去实时查询 User 服务。我们同样让 Content 服务维护了一份副本,只用于展示拼接。这类信息只要“不出错”,时效性就没那么重要。
- Notification 服务:虽然涉及推送、发信、App 通知等“不能出错”的场景,但也未必非得同步查数据。我们让它订阅
UserUpdated等事件来维护本地副本,大部分情况下都能拿到准确信息。即使偶尔有点延迟,也远比请求链挂掉来得可控。
当然,服务之间如何共享这些副本数据,其实是一个更大的系统设计话题。可以引入两条关键机制:
- 1. 事件驱动(Event-driven Architecture):当用户修改昵称、头像或邮箱时,User 服务发布一个
UserProfileUpdated事件,Feed、Content、Notification 等服务订阅这个事件并更新各自的副本。数据“自动同步”,完全不必走同步接口。 - 2. 数据物化(Data Materialization):也就是把用得到的数据预先准备好,放在本地表中随时查。Feed 页的作者信息、内容页的发布者字段、推送服务需要的邮箱地址,统统可以“提前拉好”,定时更新。这种方式不仅更稳,还显著提升系统韧性和可用性。
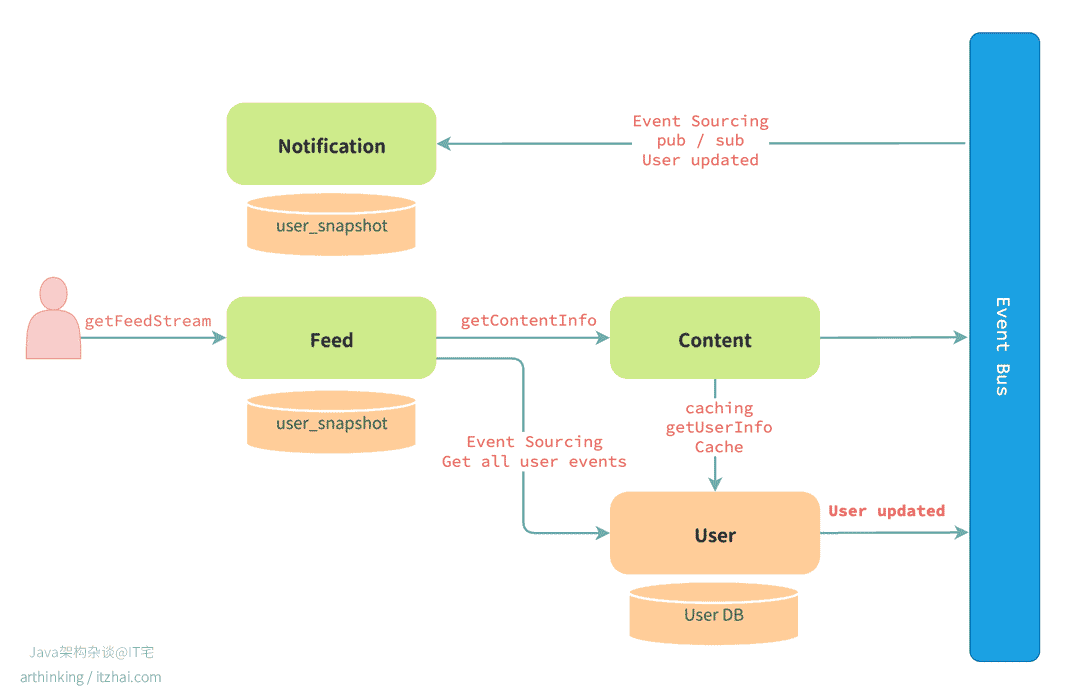
最后,我们架构如下:
- User 服务 作为数据的“唯一权威源”;
- Feed / Content / Notification 等服务 通过事件订阅异步更新;
- 每个服务维护自己的
user_snapshot,形成一个最终一致、弱依赖、高可用 的数据共享模型。
7. 结语
写这篇文章,是想提醒刚刚使用微服务的朋友,把“不要共享数据”这句话理解得太字面、太教条,这条规则的真正含义,其实是 别去共享“真实数据源”(source of truth)。
在别的服务里维护一份数据的副本,不仅合理,而且在很多场景下,是更稳、更灵活、更可扩展的做法。它体现的,正是 最终一致性(eventual consistency) 的核心精神:不是追求“每次都准”,而是追求“最终对得上”。
当然了不同的业务场景解决方案会有所不同,最终一致性也不是万能的,模式选用参考:不同场景该怎么选?
| 场景类型 | 是否推荐用副本 | 推荐理由 & 工程建议 |
|---|---|---|
| 跨服务拼接(如 Feed、内容聚合) | 推荐使用 | 使用 Outbox + 副本表,配合延迟控制,提升可用性与解耦能力。 |
| 写读强一致场景(比如金融、库存) | 不推荐 | 建议使用同步调用 + 幂等校验 + 本地事务,保障数据准确;同时结合熔断/降级机制应对异常。 |
| 跨服务长流程(例如支付、预定流程) | 推荐使用 | 采用 Saga 模式 + Outbox,有计划地设计补偿逻辑,并做好可观测性。 |
| 高频写入但数据价值不高的场景 | 不推荐 | 直接同步写入 + 配合 TTL 缓存更合适,用副本成本反而不划算。 |
如果你愿意说说你具体遇到什么场景,我可以帮你判断用哪个更合适。
感谢你读到这里!
如果你对微服务架构还有哪些疑问,或者对分布式系统中的冷门话题感兴趣,欢迎留言交流。

