在我接手的一些Java项目中,经常看到为复用而做的抽象类,把公共逻辑提取到这个类里,代码表面上是干净了,逻辑全提出来,看起来特别DRY,但一上手维护就觉得别扭得很。每当改之前得小心翼翼,生怕一个改动牵一发而动全身。
在Java代码中还看过这种抽象类:
1 | /** |
是不是现在大家都特别喜欢搞抽象了呢?

很多开发人员在写代码的时候,总爱拿所谓的“最佳实践”当圣经,要是不照着来,好像自己写的代码就是罪过一样。比如DRY原则吧,很多人就特别执着,恨不得代码里有一点重复都忍不了。可你有没有遇到过这种情况:代码写完了,抽也抽了,但怎么看都觉得怪怪的?
其实吧,这种感觉“怪怪的抽象类”,往往就是我们抽过头了。说得直白点,就是抽得不干脆、不彻底,甚至有点“强行抽象”的味道。
为什么总会掉进这个坑?可能是我们对DRY的理解太教条了,总想着“绝不能重复”,结果为了复用去搞了个奇奇怪怪的抽象层,最后反倒给自己挖了个坑。
今天我们就放松一点,重新聊聊DRY原则最初到底想干啥,然后再说说,有哪些情况你其实可以稍微“放自己一马”,没必要那么DRY。
1. 什么是 DRY 原则?
DRY 全称是 Don’t Repeat Yourself,也就是“别重复自己”。简单说,它就是提醒我们,别在代码里写重复的逻辑。重复越多,改起来越头疼。
DRY 的核心,其实不是省几行代码,而是为了让变化发生时,不用到处找重复逻辑来改。如果需求一变,复制粘贴的代码要一个个去改,不仅繁琐,而且容易改漏,但要是提取成了统一的函数,就改一处搞定,避免了很多问题。
正因为如此, DRY 才成了各种最佳实践里的常客。下面这张图形象地解释了 DRY 的思路:
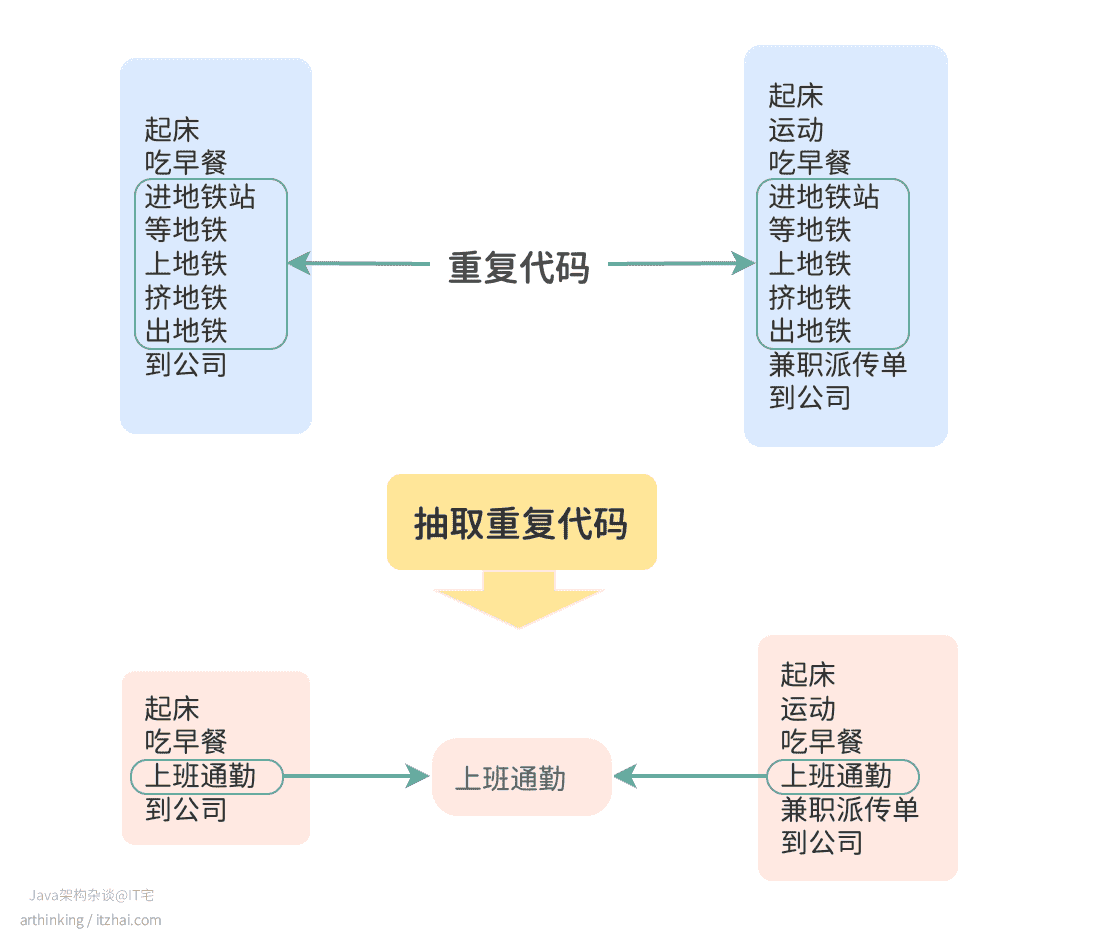
把重复的代码提取出来,方便集中管理。假设哪天需要改逻辑,只动一处,所有用到的地方自动跟着变,不用担心漏改。
但现实开发里就复杂多了。
有时候你抽得太早,或者抽得太随意,比如看起来“差不多”的两个逻辑,其实细节差了一点点,一旦合并起来,反而让代码变得更难维护。
DRY 本身没啥复杂的,它的出发点也挺朴素的。难就难在,你得判断哪些重复真值得抽,什么时候抽更合适,还有,抽完之后到底清晰了,还是更绕了?
这种判断没公式,得靠你慢慢磨。多做几个项目,多踩几次抽象过头的坑,慢慢你就有感觉了:哪些地方该忍住不动,哪些地方可以干脆抽出来。
所以这篇文章其实就想聊聊“抽象别太早”这个话题。毕竟大家都听过“过早优化是万恶之源”,那“过早抽象”是不是也差不多?
2. 抽象抽得太早了
你写功能的时候,有没有过这种经历?一边写一边想,“这功能我以后肯定还得扩展,不如现在就抽象个父类,以后扩展起来不就轻松多了?”
刚开始搞面向对象的时候,我也特别喜欢这么干。比如通知功能吧,当时就想:“通知不就那么几种嘛,邮件通知、系统告警、App私信啥的,总得有发送、撤回、写日志,干脆整一个统一的 Notification 基类,多优雅!”
于是我就兴致勃勃地写了如下结构的代码:
---
config:
themeVariables:
fontSize: 12px
fontFamily: Resource Han Rounded CN
---
classDiagram
class Notification {
+boolean send(String recipient)
+boolean cancel(String id)
+boolean log()
}
class EmailNotification {
// 直接继承所有方法
}
class InAppNotification {
+boolean send(String recipient)
// log() 方法可选,使用父类默认实现
}
class SystemAlert {
+boolean send(String recipient)
+boolean log()
// cancel() 方法不应调用
}
note for SystemAlert "cancel() 方法不支持
log() 日志记录方式不同,具体方法已自定义"
Notification <|-- EmailNotification
Notification <|-- InAppNotification
Notification <|-- SystemAlert
等后来真正的业务来了,才发现自己挖了个大坑。比如 SystemAlert 系统告警,居然也有了“撤回”这种诡异功能,写到用户审计日志功能又不一样了。后来业务越来越复杂,每个通知类型的功能差异越来越大,那些莫名其妙的继承关系反倒成了负担,每次开发都要绕过那些根本用不到的功能。
出现这个问题的核心在于:你以为自己已经找到了一个通用模式,但其实只是想象的通用。等到需求一个个落地,你会发现这些看上去差不多的场景,其实有很多细节差异。而这些差异一旦忽略,就很容易让抽象变成干扰。说白了,就是因为还没真正理解业务的前提下,就太早动手提炼结构了,最终导致为设计上的混乱埋下了种子。有时候也会遇到一些需求产品经理讲不清楚,说就暂时这么做的情况。如果这个时候你就开始做各种抽象业务设计,你迟早要为你的抽象代码买单。
现在很多软件设计都更推崇一个理念:先从具体做起,让抽象自己浮现出来。 这个理念推崇的不是一上来就想着搞一套通用结构,而是在多个真实案例里,慢慢看到共性,再去总结。这样提炼出来的抽象才有生命力,才不会经不起推敲。
语义过载
搞过领域驱动设计(DDD)的朋友应该听过一个关键词:通用语言(Ubiquitous Language)。意思就是在某个限界上下文(Bounded Context)里,团队内部的各种业务概念得统一,不管是建模还是沟通,都别各说各话,免得鸡同鸭讲。
但在现实开发里,这事儿就没有那么好实施了。我们经常会往一个类里塞了太多不相干的逻辑,看起来是一个模型,抱着复用的心态,试图用一个通用模型来 hold 住多个上下文的不同需求,但是其实模型后面却藏着好几套完全不同的业务语义。久而久之,这个模型就膨胀成了一个“谁都能用、但谁用都嫌弃”的四不像,shi山代码逐步开始成行。
举个更具体的栗子:你在做电商系统,里面有各种用户类型:买家、卖家、管理员,看起来都是用户,于是搞一个 User 类,把各种用户类型的逻辑全往里丢。最后这个类看起来功能超全,实际上变得又重又乱,Java类图如下:
---
config:
themeVariables:
fontSize: 12px
fontFamily: Resource Han Rounded CN
---
classDiagram
direction TB
class User {
String id
String name
String email
String passwordHash
Address shippingAddress
Address billingAddress
int permissionLevel // 仅用于后台管理面板
Date lastLogin // 安全审计相关
UserPreferences preferences // 前端界面相关
int loyaltyPoints // 仅在客户上下文中使用
}
class Address {
}
class UserPreferences {
}
User --> Address : shippingAddress
User --> Address : billingAddress
User --> UserPreferences
实际情况往往没那么理想:在客服那边,用户是工单的联系人;到支付系统里,用户只是个付款方;前端页面上,用户也许就只是个头像加昵称而已。
你要是把这些不同业务需求,全塞进一个“万能用户模型”里,看着是方便复用,实际就是把风马牛不相及的东西强拼在一块儿。久了之后,各个系统的边界就逐渐模糊了。
我们之前就遇到过,维护个字段的时候,突然发现改了一行代码,另一个团队的接口就收到影响了。这个“User”模型成了谁都不敢动的定时炸弹,谁改谁挨骂。
后来我们干脆不折腾了,用户模型就地拆开,每个模块自己定义自己的结构,别互相掺和。像下面这样:
---
config:
themeVariables:
fontSize: 12px
fontFamily: Resource Han Rounded CN
---
classDiagram
class Customer {
+String id
+String name
+String email
+int loyaltyPoints
+UserPreferences preferences
}
class AdminUser {
+String id
+String name
+String email
+int permissionLevel
+Date lastLogin
}
class PaymentIdentity {
+String id
+Address billingAddress
}
Customer --> UserPreferences : preferences
AdminUser --> Date : lastLogin
PaymentIdentity --> Address : billingAddress
这样一拆清爽多了,谁的逻辑归谁管,业务需求来了就自己搞定,不用提心吊胆会不会动到别的地方的 cheese。
其实这也就是 DDD 里说的“限界上下文”——每个业务域用自己的模型,各自为政,接口清楚、责任分明。最明显的好处就是,沟通也变得轻松,没人天天跑来问:“你们那个字段到底是干嘛的?”
那个听起来啥都能装的“超级用户模型”?听着挺高级,用起来就知道,它根本不是在帮你复用,是在给你制造混乱。
软件过度耦合
大家都知道 DRY(Don’t Repeat Yourself)原则的初衷是好的,减少重复,让代码保持一致。但真落到实际开发里,有时候你会发现,抽象抽着抽着,反而把系统抽“死”了。
我们团队之前就踩过这种坑。为了统一邮箱处理逻辑,我们写了个 EmailAddress 类,长这样:
1 | public class EmailAddress { |
这么做初衷就是让邮箱统一转小写,所有模块都用这个类,包括注册、找回密码、发送通知,省得每个地方都写一遍邮箱校验。
然后某天,有人为了兼容一些特殊企业邮箱,把 create() 方法改了:
1 | public static EmailAddress create(String input) { |
问题就爆发了,下游业务很多地方是默认邮箱已经是小写的,比如做比较、做去重、做命中判断。现在不转小写了,逻辑就全乱套了。这种变化在上游看起来完全合法,单测也过了,但下游根本不知道出了啥问题,只能等线上用户出事了才发现。
也许有人会想,不是下游的代码写得不够健壮吗?如果需要小写格式的邮箱,自己转换不就好了吗?其实,我觉得问题更多是在于最初设计时,EmailAddress 已经默认是小写邮箱地址了,大家都这么理解。可是,它的“角色”变了,支持了大小写,结果其他地方对它的印象却还停留在修改前。提取邮箱逻辑本身没错,是不是错在最初把邮箱都是小写的提取到一个公共逻辑中?
当你将某段逻辑抽象出来并复用时,其实就为系统模块间创建了一种隐性的契约。一旦这些抽象发生变化,之前那些没有明确说明的假设,可能就会被打破。
那么,怎么才能正确的使用DRY原则呢?
3. DRY 使用指导原则
避免过早抽象
有时候我们一看到代码里有重复,就忍不住想:“这不行,得抽一下。”但是往往抽出来之后,坑可能就在后面。
前阵子我重构订单模块,发现大家都往一个 BaseOrderService 里塞逻辑,什么下单、配货、支付全往里堆。表面上看着是复用了,但动一个地方就怕影响别的子类,改起来特别别扭。
我干脆回归最简单的做法,先不搞抽象,直接写清楚一条业务链路再说:
1 | public class OrderService { |
你看这就很直观,配货和支付是两个独立模块,我通过构造方法把配货逻辑注进来,测试的时候想换掉也容易。要改需求也不痛,完全不用担心别的地方跟着出问题。
就像你家吸尘器坏了,换一个新的就行,总不会因为吸尘器挂了就把整间屋子装修一遍吧?
所以我现在基本不会一上来就搞什么“通用父类”。先把流程写清楚,跑通了,等有几个地方真的用到了同样逻辑,再考虑抽一层也不迟。你要是太早抽,抽来抽去反而把自己套死了。
优先抽象业务规则
有些重复是真的不能留,特别是那种关键业务规则。你不抽出来,早晚有人踩坑。
比如我们之前的购物车模块,添加商品、更新商品数量两个接口,看起来都差不多,但都写了自己的“最多10件”限制。结果后来业务一改,只改了一个地方,另一个忘了改,线上就直接出锅了。
当时那两段逻辑,看着都差不多,但你细看,其实写法还真不一样:
1 | if (cart.totalItems() + quantity > 10) { |
和
1 | if (cart.totalItems() - cart.getQuantity(productId) + quantity > 10) { |
表面雷同,实则都是坑。后来我们直接把这个限制抽出来做了个 CartPolicy.validateCartLimit(...),统一掉,之后就没人再改漏了。
但话说回来,如果你看到的是一些什么“日志打印、对象映射”这种纯基础设施的重复,真没必要急着抽。写得越抽象,耦合越严重,还不如复制一份用得干脆。而且日志、映射、配置等基础设施,一般业界已有成熟方案,无需自己写抽象层。
DRY 原则不是用来束缚你的,而是帮你识别哪些“该抽”的规则值得维护。别一看到重复就条件反射地抽象——真正该抽的,是那些改错了就出事的代码。
共享代码保持精小
很多时候我们一看到一段逻辑可以复用,就会想着:“要不我把它提出来放到 shared/utils 里?”听起来很对,但其实也会有坑的。
共享代码不是放得越高越好,相反,越靠近上下文的共享,越安全、越靠谱。以前一个项目模块就有同事吃过这个亏:把一段金额格式化的逻辑封到了全局 FormatUtils 里,结果报表模块和结算模块都在用。有一天结算那边要加个人民币符号,刚改完上线,报表那边直接点不开了,说展示错乱。真的是“一个人放屁,全屋遭殃”。
所以后来换了个思路:逻辑要共享没问题,但范围要“管住”。像这种金额格式化的东西,就直接放进 reporting.utils.MoneyFormatter 里,报表专用,其他人别碰。这样将来报表独立出去做服务化部署时,根本不用担心依赖一堆不相干的工具类。
看看下面这张图,可以更清楚地看到局部共享的好处:
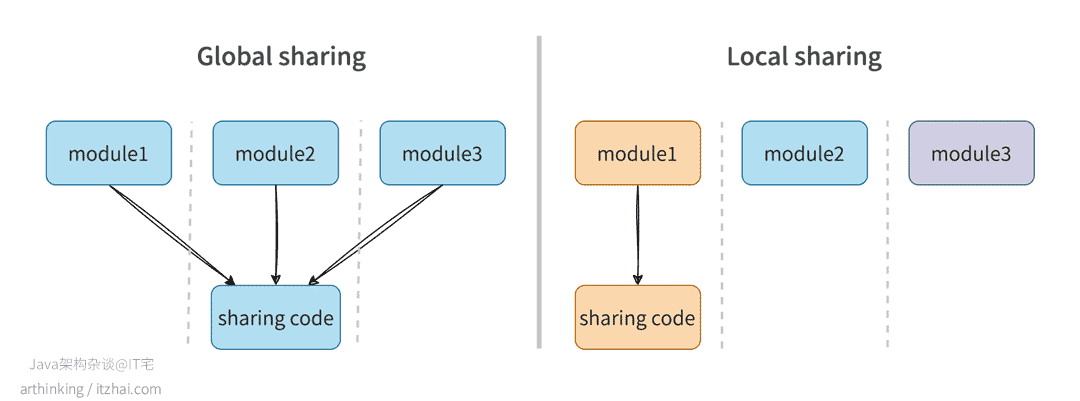
这样做不仅确保了代码的用途明确,还能为未来的模块拆分、迁移或独立部署留下空间。
别迷信 DRY 到处抽工具类,更别随便封装进 shared。封装不是“集市”,是“分区”。共用可以,但最好只在熟人之间共用。
做好契约测试(Contract Test)
在支付团队里,有一段小插曲说明了为什么契约测试这么重要。
他们一直在用同一个共享的 PriceCalculator 组件来算折扣:
1 | public BigDecimal applyDiscount(BigDecimal price, int discountPercentage) { |
某次结算规则改了,要“四舍五入到分”,组件组很快跟进,测试也一起改了,CI 全绿。直到下游服务上线才发现:他们原本用不带舍入的结果去判断满减阈值,一下子都错乱了。
这时候,支付团队才在自己项目加了一条“契约测试”——从使用者角度,硬编码验证旧行为:
1 |
|
把它放到自己的 CI 流程里,一旦组件核心行为变了(不管组件组怎么更新测试),这个用例就会立刻红灯报警。
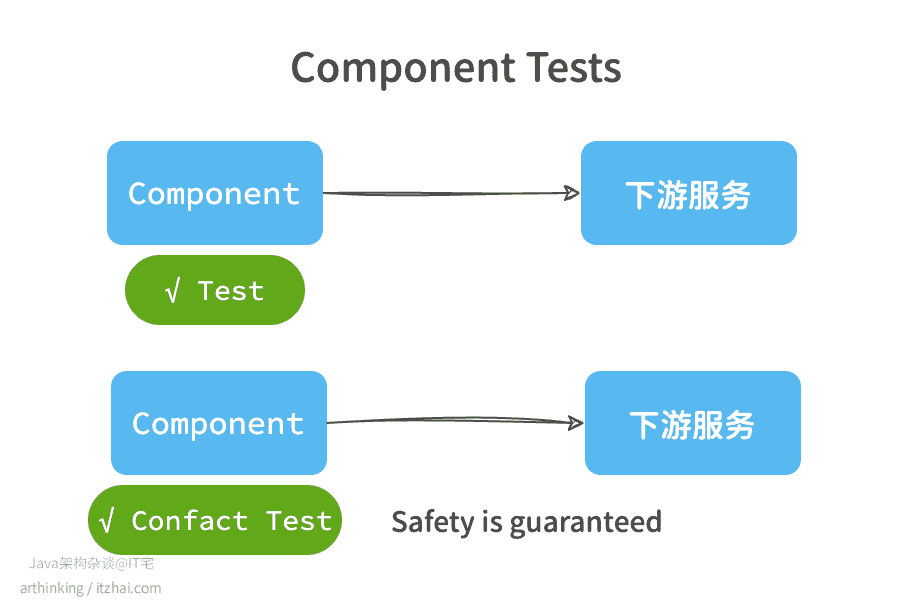
契约测试不是要取代单元测试,而是让使用方也帮着“把关”,确保每一次升级都不会悄悄破坏自己的业务逻辑。多服务共享组件时,这一步尤其不能省——要不然等到生产环境再发现,麻烦可就大了。
做好版本管理
有一次一个同事在项目中给好几个服务同时加了同一份业务逻辑,结果更新的时候才发现:有的服务还在跑旧代码,另一部分已经上线了新逻辑,数据完全对不上。排查花了不少时间。后来我就坚定地把“共享模块”也当成一个独立的小服务来看待。
比如我们公司做的 inventory-core,我会直接在各个项目里用 Maven 引入:
1 | <dependency> |
这样一来,想升级到 1.3.0,就得在每个服务里主动改一下版本号、跑个冒烟测试,确认没问题才发布。要是发现兼容性有风险,我还能迅速回滚到 1.2.3,根本不用担心某台机器“偷偷”跑了代码副本。
所以,不管你用 Maven、Gradle,或者随便打包成一个 Jar,我建议都把共享逻辑当成有自己生命周期的小模块来管理——就像你依赖的第三方 API 一样,要升级就得“敲门”、得评估,才能保证大家都在同一个频道上,避免“版本幽灵”乱入的麻烦。
4. 说在最后
DRY(Don’t Repeat Yourself,不要重复自己)是编程中的黄金法则,提倡我们减少代码的重复,提升可维护性。这个法则的出发点是好的,但是我们不要被这个原则“绑架”了,更不要在需求还没完全清晰的时候,就开始盲目地抽象,特别是在推崇OO编程思想的Java这类编程语言中,结果反而让代码变得复杂难懂,维护起来更是头疼。
你是不是也有过这种经历:为了避免重复逻辑,抽了个 BaseXXX 出来,结果发现后续加功能的时候越来越难改?
比如写个 BaseExporter,想着以后导出成 CSV、XML、PDF 都能继承它,各搞各的逻辑,看起来挺“面向对象”的。但后来导出逻辑一个比一个复杂,CSV 要分页、XML 要带命名空间、PDF 还要套模板,最后那个抽象父类成了空壳,还处处掣肘。加一个逻辑还得改接口,要不就是硬塞进子类,产生奇怪的代码。
所以抽象不是为了“省代码”,而是为了“统一不可变的规则”。比如那些明确的业务限制——商品数量最多10个、手机号必须唯一,这类规则值得抽。DRY 最大的误区是“看到重复就想抽”,而忽略了这些重复到底是不是“稳定的模式”。
有时候,你不是在复用,而是在用一堆看不懂的抽象,把自己绑进了逻辑迷宫。
如果你曾经经历过过度抽象带来的困扰,深知其中的痛苦,那就把这段经验告诉更多人吧。软件设计中并不是每个重复的地方都需要立即抽象,聪明的开发者知道在哪里适当地保持重复。
有同感吗?可以让身边的同事或朋友也看看,帮助更多开发者避免这些常见的误区!

