这里还是使用搜狗的扩展词库
扩展词典添加搜狗词库:
http://pinyin.sogou.com/dict/cell.php?id=11640
词条
大小
392790个
13737KB
先直接用java.lang.Runtime类中的freeMemory(),totalMemory(),maxMemory ()这几个方法
进行计算。
先把这92790个放入到ext.dic文件中。
加上IKAnalyzer默认加载的这两个词典:
org/wltea/analyzer/dic/main2012.dic 275713个
org/wltea/analyzer/dic/quantifier.dic 316个
总格的词条是66W多。
执行如下代码:
public static void main(String[] args){
calculateMem();
}
public static void calculateMem(){
System.out.println(“初始化内存”);
System.out.println(“空闲内存:” + Runtime.getRuntime().freeMemory());
System.out.println(“已获取到的内存:” + Runtime.getRuntime().totalMemory());
System.out.println(“能够获得的最大内存:” +Runtime.getRuntime().maxMemory());
System.gc();
Dictionary.initial(DefaultConfig.getInstance());
long total = Runtime.getRuntime().totalMemory(); // 返回总的内存数
long size = Runtime.getRuntime().freeMemory(); // 返回当前的剩余内存数
System.out.println("Memory used: " + (total - size));
}
执行结果如下:
初始化内存
空闲内存:15965080
已获取到的内存:16252928
能够获得的最大内存:518979584
加载扩展词典:ext.dic
加载扩展停止词典:stopword.dic
Memory used: 95027120B
结果是90.62M
接下来使用Instrumentation的getObjectSize方法进行计算下:
public class CalculateDictionarySize {
public static void main(String[] args){
Dictionary.initial(DefaultConfig.getInstance());
System.out.print(SizeOfAgent.fullSizeOf(Dictionary.getSingleton()) + “B”);
}
}
编写MANIFEST.MF文件:
Manifest-Version: 1.0
Ant-Version: Apache Ant 1.6.1
Created-By: 1.5.0_06-b05 (Sun Microsystems Inc.)
Main-Class: com.itzhai.test.CalculateDictionarySize
Class-Path: lib/IKAnalyzer2012_u6.jar
Premain-Class: com.itzhai.test.SizeOfAgent
Boot-Class-Path:
Can-Redefine-Classes: false
包结构如下:
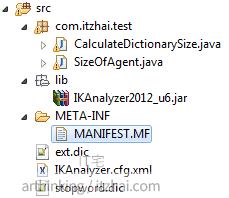
SizeOfAgent的写法参考这里:
http://www.itzhai.com/java-object-memory-calculate-method.html
打包成Jar文件之后,到命令行中执行:
java -javaagent:sizeOfAgent.jar com.itzhai.test.CalculateDictionarySize
结果如下:
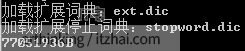
73.48M
也就是说66W多个字条占用了73.48M的内存。
IKAnalyzer的存储结构:
IKAnalyzer是以字典树的方式把字典载入内存中的:
词典管理类为Dictionary,有三种词典:主词典,停用词词典,量词词典,这三种词典都是对应为一个DictSegment对象的,而DictSegment对象时树形结构的,每一个子节点又可以是一个DictSegment对象。
节点的存储方式:以数组(DictSegment[])或者Map(Map<Character, DictSegment)存储的,按照如下规则选择存储方式
- 如果子节点数量小于等于ARRAY_LENGTH_LIMIT,则采用数组存储
- 如果子节点数量大于ARRAY_LENGTH_LIMIT,则采用Map存储。

