

基于基础的数据类型,Redis扩展了一些高级功能,如下图所示:
| 数据类型 | 数据类型 |
|---|---|
| Bitmap | REDIS_STRING |
| HyperLogLog | REDIS_STRING |
| Bloom Filter | REDIS_STRING,Bitmap实现 |
| Geospatial | REDIS_ZSETZ |
作为一个注重系统化学习的博客 IT宅(itzhai.com),作为一个追求技术发展的公众号,Java架构杂谈怎么能少了这些高级特性的内容了,下面,arthinking我就详细展开来看看这些特性。
1、BitMap
Bitmap,位图算法,核心思想是用比特数组,将具体的数据映射到比特数组的某个位置,通过0和1记录其状态,0表示不存在,1表示存在。通过使用BitMap,可以将极大域的布尔信息存储到(相对)小的空间中,同时保持良好的性能。
由于一条数据只占用1个bit,所以在大数据的查询,去重等场景中,有比较高的空间利用率。
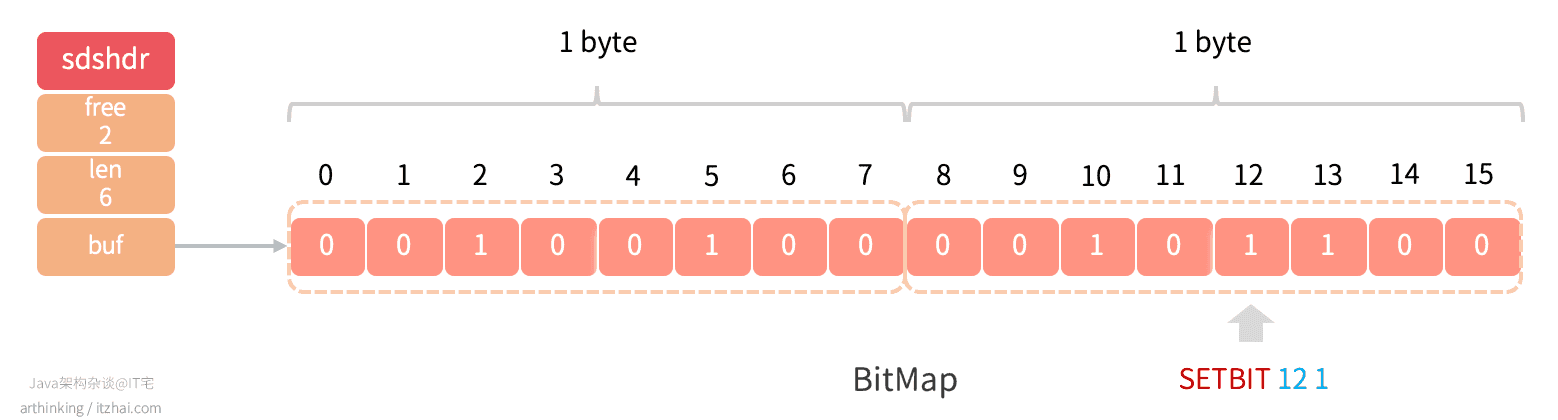
注意:BitMap数组的高低位顺序和字符字节的位顺序是相反的。
由于位图没有自己的数据结构,**BitMap底层使用的是REDIS_STRING进行存储的。**而STRING的存储上限是512M(2^32 -1),如下,最大上限为4294967295:
1 | 127.0.0.1:30001> setbit user_status 4294967295 1 |
如果要存储的值大于2^32 -1,那么就必须通过一个的数据切分算法,把数据存储到多个bitmap中了。
Redis中BitMap相关API
- SETBIT key offset value:设置偏移量offset的值,value只能为0或者1,O(1);
- GETBIT key offset:获取偏移量的值,O(1);
- BITCOUNT key start end:获取指定范围内值为1的个数,注意:start和end以字节为单位,而非bit,O(N);
- BITOP [operations] [result] [key1] [key2] [key…]:BitMap间的运算,O(N)
- operations:位移操作符
- AND 与运算 &
- OR 或运算 |
- XOR 异或 ^
- NOT 取反 ~
- result:计算的结果,存储在该key中
- key:参与运算的key
- 注意:如果操作的bitmap在不同的集群节点中,则会提示如下错误:
CROSSSLOT Keys in request don't hash to the same slot,可以使用HashTag把要对比的bitmap存储到同一个节点中;
- operations:位移操作符
- BITPOS [key] [value]:返回key中第一次出现指定value的位置
如下例子,两个bitmap AND操作结果:
1 | 127.0.0.1:30001> SETBIT {user_info}1 1001 1 |
性能与存储评估
关于BitMap的空间大小
BitMap空间大小是一个影响性能的主要因素,因为对其主要的各种操作复杂度是O(N),也就意味着,越大的BitMap,执行运算操作时间越久。
Redis的BitMap对空间的利用率是很低的,我们可以做个实验:
1 | 127.0.0.1:30002> SETBIT sign_status 100000001 1 |
可以看到,我们只是往BitMap里面设置了一位,就给BitMap分配了12501048的空间大小。
这是由于Redis的BitMap的空间分配策略导致的。由于底层是用的Redis字符串存储的,所以扩容机制跟字符串一致。执行SETBIT命令,当空间不足的时候,就会进行扩容,以确保可以在offset处保留一个bit。
所以我们一开始给100000001偏移量进行设置,就会立刻申请一个足够大的空间,这个申请过程中,会短时间阻塞命令的执行。
为了避免使用较大的BitMap,Redis文档建议将较大的BitMap拆分为多个较小的BitMap,处理慢速的BITOP建议在从节点上执行。提前拆分,这样可以了更好的应对未来潜在的数据增长。
关于BitMap的存储空间优化
从上面的分析可知,直接就设置很大的offset,会导致数据分布式很稀疏,产生很多连续的0。针对这种情况,我们可以采用RLE(行程编码,Run Length Encoding, 又称游程编码、行程长度编码、变动长度编码)编码对存储空间进行优化,不过Redis中是没有做相关存储优化的。
大致的思想是:表达同样的一串数字 000000,没有编码的时候是这样说的 :零零零零零零,编码之后可以这样说:6个零,是不是简单很多呢?
给如下的BitMap:
1 | 000000110000000000100001000000 |
可以优化存储为:
1 | 0,6,2,10,1,4,1,6 |
表示第一位是0,连续有6个0,接下来是2个1,10个0,1个1,4个0,1个1,6个0。这个例子只是大致的实现思路。
guava中的EWAHCompressedBitmap是一种压缩的BitMap的实现。EWAH是完全基于RLE进行压缩的,很好的解决了存储空间的浪费问题。
2、Bloom Filter
考虑一个这样的场景,我们在网站注册账号,输入用户名,需要立刻检测用户名是否已经注册过,如果已注册的用户数量巨大,有什么高效的方法验证用户名是否已经存在呢?
我们可能会有以下的解法:
- 线性查找,复杂度O(n)这是最低效的方式;
- 二分查找,复杂度O(log2n),比线性查找好很多,但是仍绕需要多个查找步骤;
- HashTable查找,快速,占用内存多。
而如果使用Boolean Filter,则可以做到既节省资源,执行效率又高。
布隆过滤器是一种节省空间的概率数据结构,用于测试元素是否为集合的成员,底层是使用BitMap进行存储的。
例如,检查用户名是否存在,其中集合是所有已注册用户名的列表。
它本质上是概率性的,这意味着可能会有一些误报:它可能表明给定的用户名已被使用,但实际上未被使用。
布隆过滤器的有趣特性
- 与HashTable不同,固定大小的布隆过滤器可以表示具有任意数量元素的集合;
- 添加元素永远不会失败。但是,随着元素的添加,误判率会越来越高。如果要降低误报结果的可能性,则必须使用更多数量的哈希函数和更大的位数组,这会增加延迟;
- 无法从过滤器中删除元素,因为如果我们通过清除k个散列函数生成的索引处的位来删除单个元素,则可能会导致其他几个元素的删除;
- 重点:判定不在的数据一定不存在,存在的数据不一定存在。
Bloom Filter如何工作
我们需要k个哈希函数来计算给定输入的哈希值,当我们要在过滤器中添加项目时,设置k个索引h1(x), h2(x), …hk(x)的位,其中使用哈希函数计算索引。
如下图,假设k为3,我们在Bloom Filter中标识"itzhai.com"存在,则需要分别通过三个哈希函数计算得到三个偏移量,分别给这三个偏移量中的值设置为1:
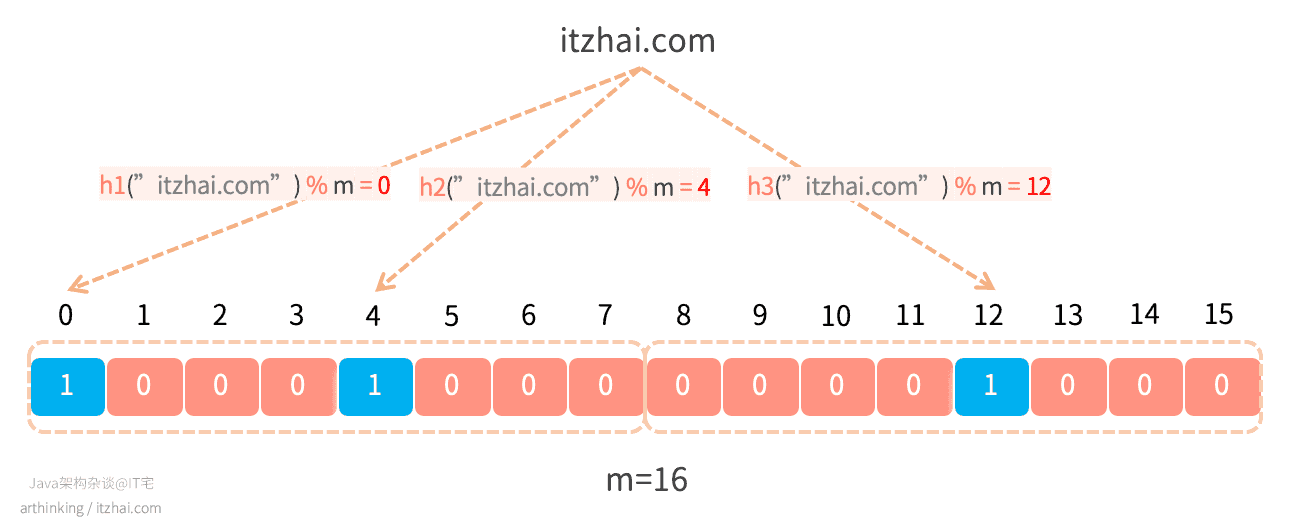
当我们需要检索判断"itzhai.com"是否存在的时候,则同样的使用者三个哈希函数计算得到三个偏移量,判断三个偏移量所处的位置的值是否都为1,如果为1,则表示"itzhai.com"是存在的。
Bloom Filter中的误判
假设我们继续往上面的Bloom Filter中记录一个新的元素“Java架构杂谈”,这个时候,我们发现h3函数计算出来的偏移量跟上一个元素相同,这个时候就产生了哈希冲突:
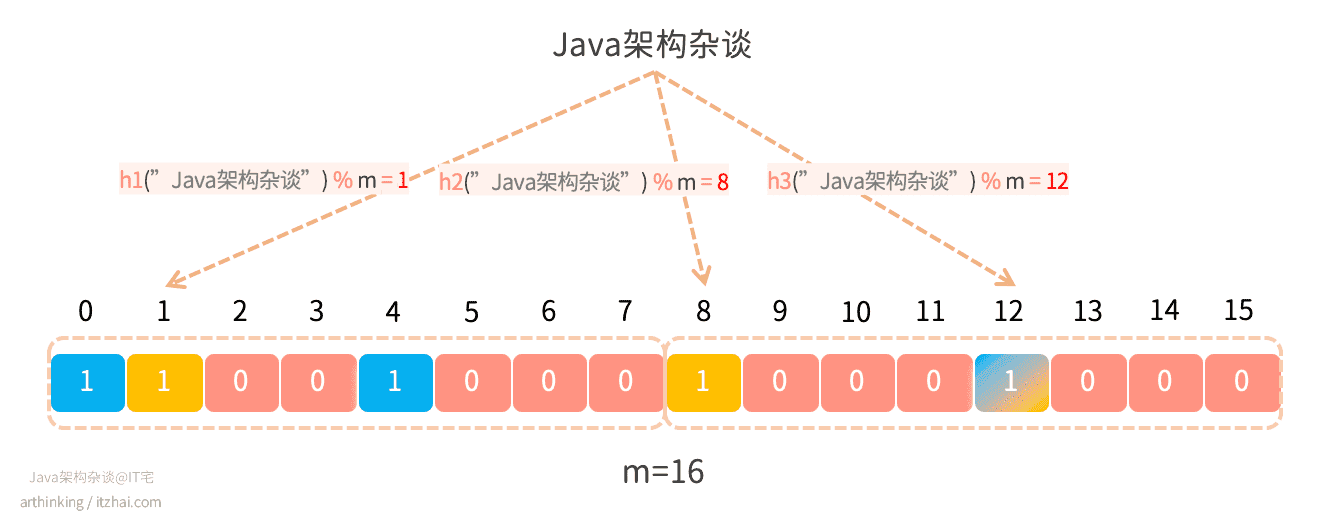
这就会导致,即使偏移量为12的这个值为1,我们也不知道究竟是“Java架构杂谈”这个元素设置进去的,还是"itzhai.com"这个元素设置进去的,这就是误判产生的原因。
在Bloom Filter中,我们为了空间效率而牺牲了精度。
如何减少误判
Bloom Filter的精度与BitMap数组的大小以及Hash函数的个数相关,他们之间的计算公式如下:
1 | p = pow(1−exp(−k/(m/n)),k) |
其中:
- m:BitMap的位数
- k:哈希函数的个数
- n:Bloom Filter中存储的元素个数
为了更方便的合理估算您的数组大小和哈希函数的个数,您可以使用Thomas Hurst提供的这个工具来进行测试:Bloom Filter Calculator [1]。
Redis中的Bloom Filter
Redis在4.0版本开始支持自定义模块,可以将自定义模块作为插件附加到Redis中,官网推荐了一个RedisBloom[2]作为Redis布隆过滤器的Module。可以通过以下几行代码,从Github获取RedisBloom,并将其编译到rebloom.so文件中:
1 | $ git clone --recursive git@github.com:RedisBloom/RedisBloom.git |
这样,Redis中就支持Bloom Filter过滤器数据类型了:
1 | BF.ADD visitors arthinking |
除了引入这个模块,还有以下方式可以引入Bloom Filter:
- pyreBloom(Python + Redis + Bloom Filter = pyreBloom);
- lua脚本来实现;
- 直接通过Redis的BitMap API来封装实现。
Bloom Filter在业界的应用
- Medium使用Bloom Filter通过过滤用户已看到的帖子来向用户推荐帖子;
- Quora在Feed后端中实现了一个共享的Bloom Filter,以过滤掉人们以前看过的故事;
- Google Chrome浏览器曾经使用Bloom Filter来识别恶意网址;
- Google BigTable,Apache HBase和Apache Cassandra以及Postgresql使用Bloom Filter来减少对不存在的行或列的磁盘查找。
3、HyperLogLog
HyperLogLog是从LogLog算法演变而来的概率算法,用于在不用存储大集合所有元素的情况下,统计大集合里面的基数。
基数:本节该术语用于描述具有重复元素的数据流中不同元素的个数。而在多集合理论中,该术语指的是多集合的重复元素之和。
HyperLogLog算法能够使用1.5KB的内存来估计超过10^9个元素的基数,并且控制标准误差在2%。这比位图或者Set集合节省太多的资源了 。
HyperLogLog算法原理
接下来我们使用一种通俗的方式来讲讲HyperLogLog算法的原理,不做深入推理,好让大家都能大致了解。
我们先从一个事情说起:你正在举办一个画展,现在给你一份工作,在入口处记下每一个访客,并统计出有多少个不重复的访客,允许小的误差,你会如何完成任务呢?
你可以把所有的用户电话号码都记下来,然后每次都做一次全量的对比,统计,得到基数,但这需要耗费大量的工作,也没法做到实时的统计,有没有更好的方法呢?

我们可以跟踪每个访客的手机号的后6位,看看记录到的后六位的所有号码的最长前导0序列。
例如:
- 123456,则最长前导0序列为0
- 001234,则最长前导0序列为2
随着你记录的人数越多,得到越长的前导0序列的概率就越大。
在这个案例中,平均每10个元素就会出现一次0序列,我们可以这样推断:
假设L是您在所有数字中找到的最长前导0序列,那么估计的唯一访客接近10ᴸ。
当然了,为了获得更加均匀分布的二进制输出,我们可以对号码进行哈希处理。最后在引入一个修正系数φ用于修正引入的可预测偏差,最终我能可以得到公式:
2ᴸ/ φ
这就是**Flajolet-Martin算法**(Philippe Flajolet和G. Nigel Martin发明的算法)。
但是假如我们第一个元素就碰到了很长的前导0序列,那么就会影响我们的预测的准确度了。
为此,我们可以将哈希函数得到的结果拆到不同的存储区中,使用哈希值的前几位作为存储区的索引,使用剩余内容计算最长的前导0序列。根据这种思路我们就得到了LogLog算法。
为了得到更准确的预测结果,我们可以使用调和平均值取代几何平均值来平均从LogLog得到的结果,这就是HyperLogLog的基本思想。
更加详细专业的解读,如果觉得维基百科的太学术了,不好理解,可以进一步阅读我从网上找的几篇比较好理解的讲解:
- Redis 中 HyperLogLog 讲解[3]
- HyperLogLog: A Simple but Powerful Algorithm for Data Scientists[4]
- Redis 中 HyperLogLog 的使用场景[5]
Redis中的HyperLogLog
Redis在2.8.9版本中添加了HyperLogLog结构。在Redis中,每个HyperLogLog只需要花费12KB的内存,就可以计算接近2^64个不同元素的基数。
Redis中提供了以下命令来操作HyperLogLog:
PFADD key element [element ...]:向HyperLogLog添加元素PFCOUNT key [key ...]:获取HyperLogLog的基数PFMERGE destkey sourcekey [sourcekey ...]:将多个HyperLogLog合并为一个,合并后的HyperLogLog基数接近于所有被合并的HyperLogLog的并集基数。
以下是使用例子:
1 | # 存储第一个HyperLogLog |
4、Geospatial
现在的App,很多都会利用用户的地理位置,做一些实用的功能,比如,查找附近的人,查找附近的车,查找附近的餐厅等。
Redis 3.2开始提供的一种高级功能:Geospatial(地理空间),基于GeoHash和有序集合实现的地理位置相关的功能。
如果叫你实现一个这样的功能,你会如何实现呢?
用户的地理位置,即地理坐标系统中的一个坐标,我们的问题可以转化为:在坐标系统的某个坐标上,查找附近的坐标。
而Redis中的Geo是基于已有的数据结构实现的,已有的数据结构中,能够实现数值对比的就只有ZSET了,但是坐标是有两个值组成的,怎么做比较呢?
**核心思想:**将二维的坐标转换为一维的数据,就可以通过ZSET,B树等数据结构进行对比查找附近的坐标了。
我们可以基于GeoHash编码,把坐标转换为一个具体的可比较的值,再基于ZSET去存储获取。
GeoHash编码
GeoHash编码的大致原理:将地球理解为一个二维平面,将平面递归分解为子块,每个子块在一定的经纬度范围有相同的编码。
总结来说就是利用二分法分区间,再给区间编码,随着区块切分的越来越细,编码长度也不断追加,变得更精确。
为了能够直观的对GeoHash编码有个认识,我们来拿我们的贝吉塔行星来分析,如下图,我们把行星按照地理位置系统展开,得到如下图所示的坐标系统:
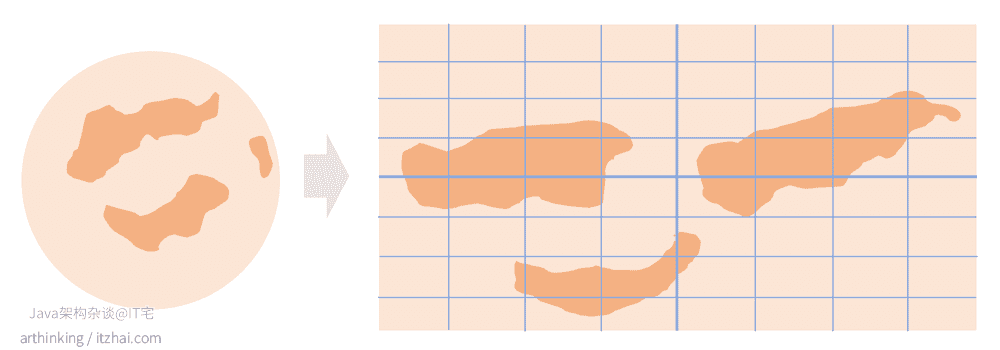
我们可以给坐标系统上面的区块进行分块标识,规则如下:
- 把纬度二等分:左边用0表示,右边用1表示;
- 把经度二等分:左边用0表示,右边用1表示。
偶数位放经度,奇数位放维度,划分后可以得到下图:
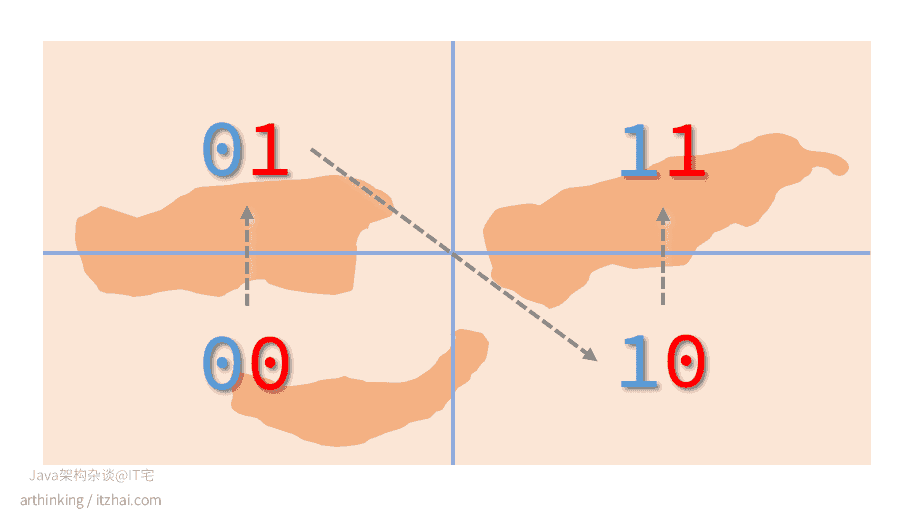
其中,箭头为数值递增方向。上图可以映射为一维空间上的连续编码: 00 01 10 11,相邻的编码一般距离比较接近。
我们进一步递归划分,划分的左边或者下边用0表示,右边或者上边用1表示,可以得到下图:
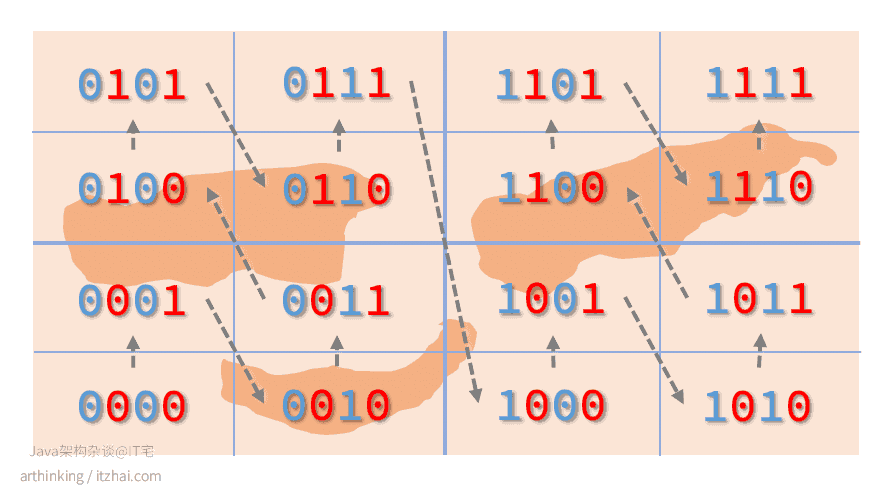
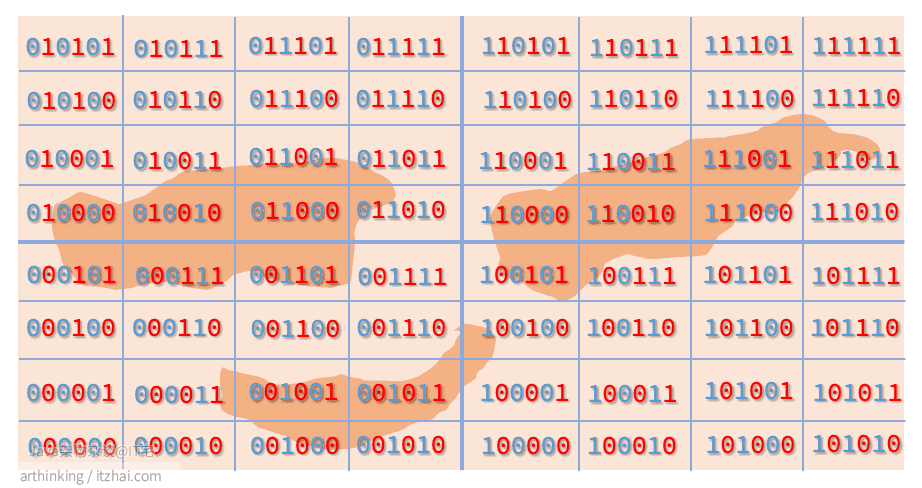
GeoHash Base32编码
最后,使用以下32个字符对以上区块的经纬度编码进行base 32编码,最终得到区块的GeoHash Base32编码。
| Decimal | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Base 32 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | b | c | d | e | f | g |
| Decimal | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| Base 32 | h | j | k | m | n | p | q | r | s | t | u | v | w | x | y | z |
同一个区块内,编码是相同的。可以发现:
- 编码长度越长,那么编码代表的区块就越精确;
- 字符串相似编码所代表的区块距离相近,但有特殊情况;
根据Geohash[6]可知,当GeoHash Base32编码长度为8的时候,距离精度在19米左右。
关于区块距离的误差
基于GeoHash产生的空间填充曲线最大缺点是突变性:有些编码相邻但是距离却相差很远,如下图:
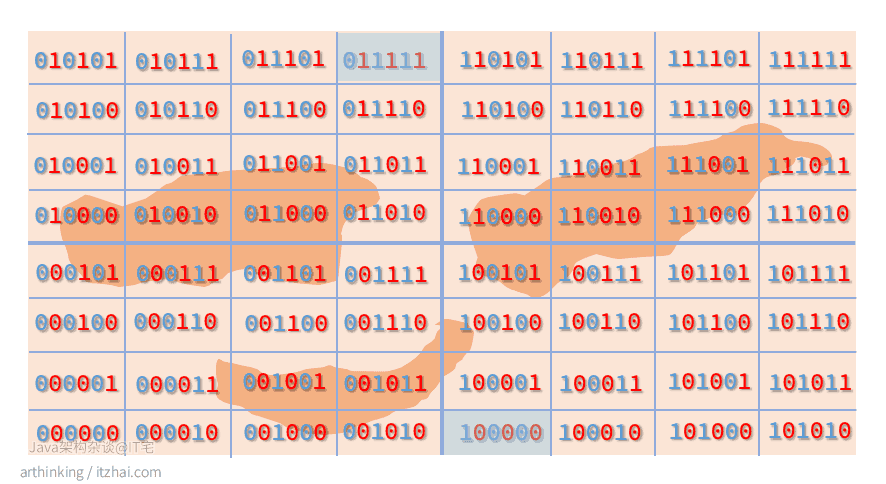
因此,为了避免曲突变造成的影响,在查找附近的坐标的时候,首先筛选出GeoHash编码相近的点,然后进行实际的距离计算。
Redis中的Geo
Redis中的Geo正是基于GeoHasn编码,把地理坐标的编码值存入ZSET中,进行查找的。
下面我们演示一下相关API的用法:
1 | # 添加国内的6个旅游地点 |
正是因为命令执行完全是在内存中处理的,所以redis执行速度非常快,但是为了数据的持久化,我们就不能离开磁盘了,因为一旦断点,内存的数据就都丢失了。
下面再来讲讲Redis是怎么通过磁盘来提供数据持久化,和宕机后的数据恢复的。
References
Bloom Filter Calculator. Retrieved from https://hur.st/bloomfilter ↩︎
RedisBloom Bloom Filter Command Documentation. Retrieved from https://oss.redislabs.com/redisbloom/Bloom_Commands/ ↩︎
Redis 中 HyperLogLog 讲解. Retrieved from https://www.huaweicloud.com/articles/4318da1b4433ab32b21e385dde2247d6.html ↩︎
HyperLogLog: A Simple but Powerful Algorithm for Data Scientists. Retrieved from https://towardsdatascience.com/hyperloglog-a-simple-but-powerful-algorithm-for-data-scientists-aed50fe47869 ↩︎
Redis 中 HyperLogLog 的使用场景. Retrieved from https://www.cnblogs.com/54chensongxia/p/13803465.html ↩︎
Geohash. Retrieved from https://en.wikipedia.org/wiki/Geohash ↩︎

