

Redis是一个内存的键值对数据库,但是要是服务进程挂了,如何恢复数据呢?这个时候我们就要来讲讲Redis的持久化了。
Redis的持久化有两种方式:RDB和AOF。
1、RDB
RDB是Redis持久化存储内存中的数据的文件格式。RDB,即Redis Database的简写。也称为内存快照。
1.1、如何创建RDB文件?
触发生成RDB文件命令是SAVE和BGSAVE。从命名的命名就可以知道,BGSAVE是在后台运行的:
SAVE:执行SAVE命令创建RDB文件的过程中,会阻塞Redis服务进程,此时服务器不能处理任何命令;BGSAVE:BGSAVE会派生出一个子进程来创建RDB文件,Redis父进程可以继续处理命令请求。
BGSAVE执行流程
BGSAVE执行流程如下:
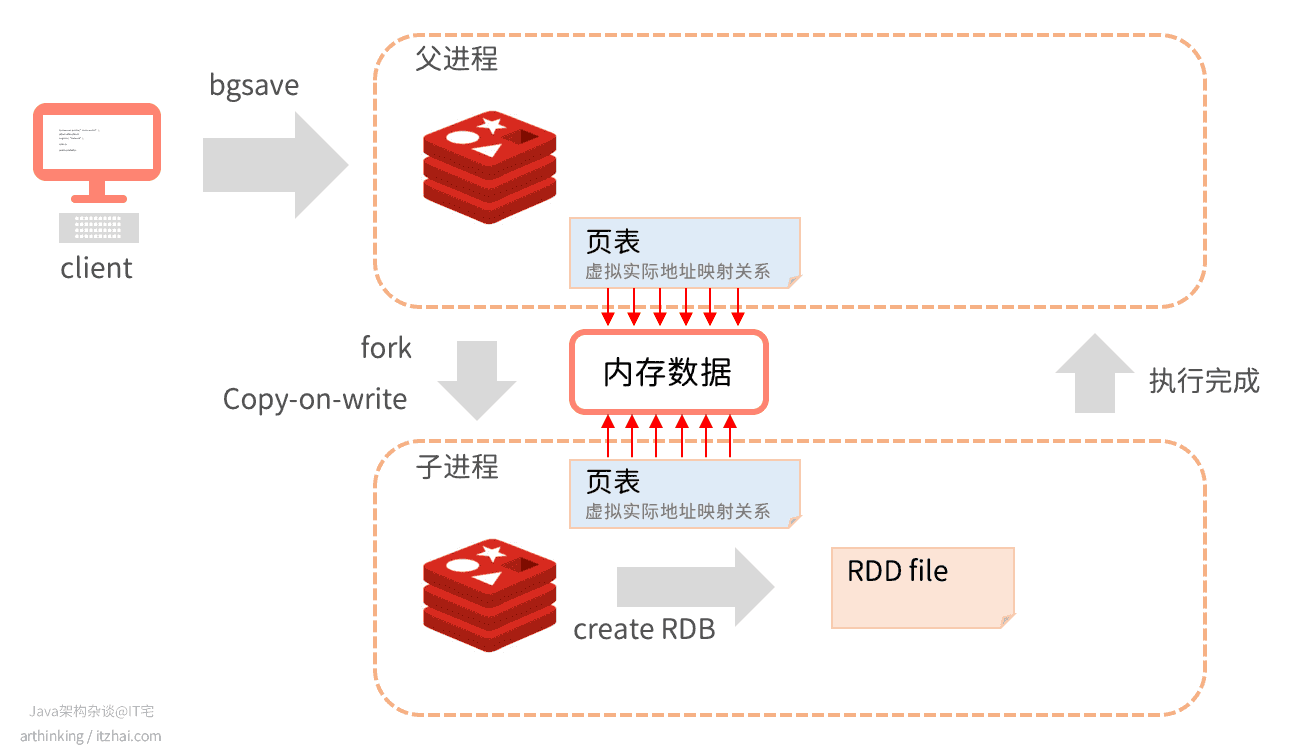
在发起BGSAVE命令之后,Redis会fork出一个子进程用于执行生成RDB文件。fork的时候采用的是写时复制(Copy-on-write)技术。不会立刻复制所有的内存,只是复制了页表,保证了fork执行足够快。如上图,Redis父进程和执行BGSAVE的子进程的页表都指向了相同的内存,也就是说,内存并没有立刻复制。
然后子进程开始执行生成RDB。
在生成RDB过程中,如果父进程有执行新的操作命令,那么会复制需要操作的键值对,父子进程之间的内存开始分离:
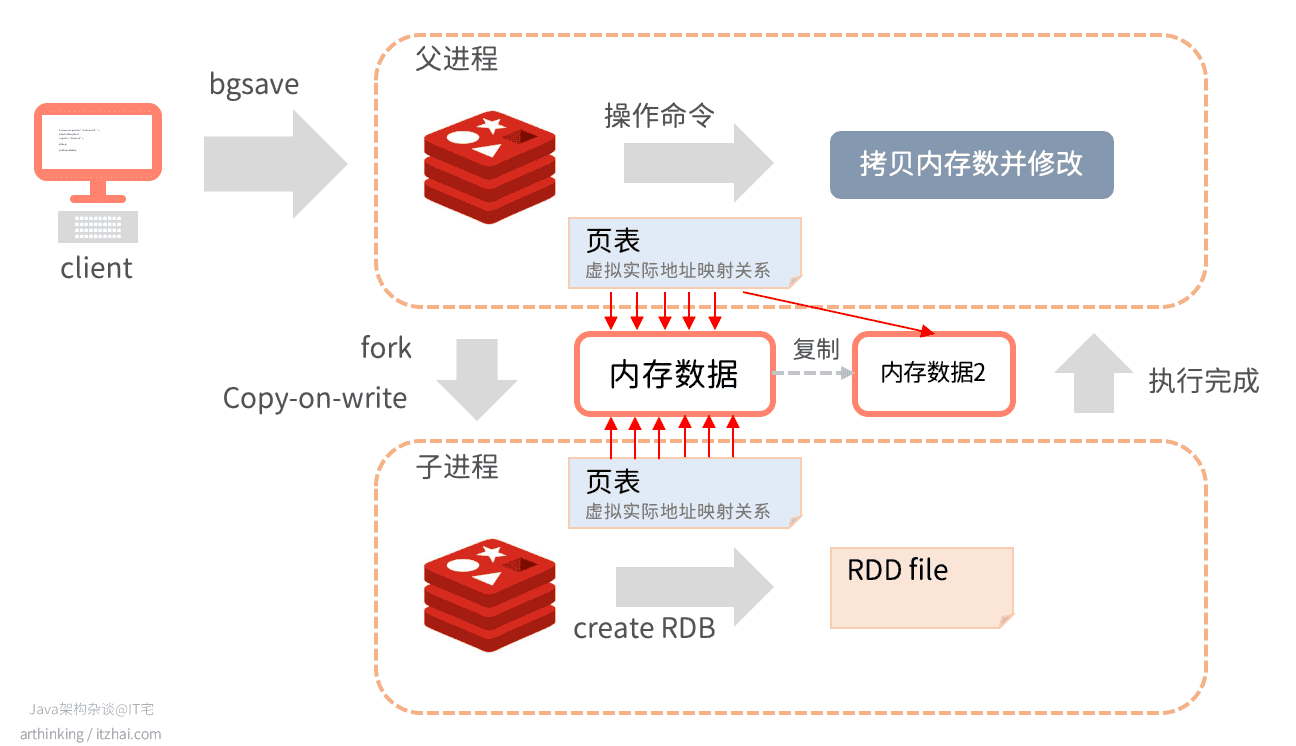
如上图,父进程执行命令修改了一些键值对的时候,该部分键值对实际上会复制一份进行修改,修改完成之后,父进程中的该内存数据的指针会指向被复制的的内存。而子进程继续指向原来的数据,原来的数据内容是不会被修改的。
在生成RDB文件过程中,父进程中对数据的修改操作不会被持久化。
执行BGSAVE会消耗很多内存吗?
由上面描述可知,BGSAVE并不会立刻复制内存数据,而是采用了写时复制技术,所以并不会立刻消耗很多内存。
但是如果Redis实例写比读的执行频率高很多,那么势必会导致执行BGSAVE过程中大量复制内存数据,并且消耗大量CPU资源,如果内存不足,并且机器开启了Swap机制,把部分数据从内存swap到磁盘上,那么性能就会进一步下降了。
服务端什么时候会触发BGSAVE?
Redis怎么知道什么时候应该创建RDB文件呢?我们得来看看redisServer中的几个关键属性了,如下图:
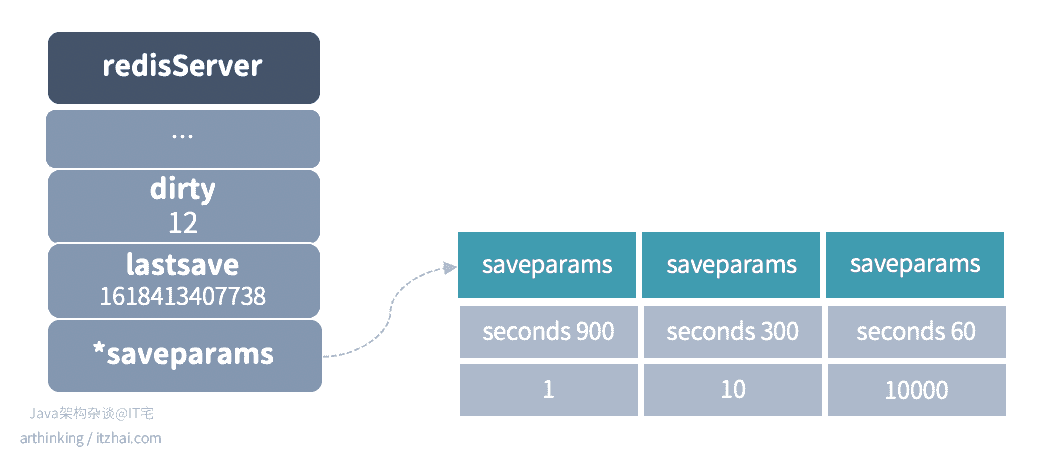
- dirty计数器:记录距离上一次成功执行SAVE或者BGSAVE命令之后,服务器数据库进行了多少次修改操作(添加、修改、删除了多少个元素);
- lastsave时间:一个Unix时间戳,记录服务器上一次成功执行SAVE或者BGSAVE命令的时间;
- saveparams配置:触发BGSAVE命令的条件配置信息,如果没有手动设置,那么服务器默认设置如上图所示:
- 服务器在900秒内对数据库进行了至少1次修改,那么执行BGSAVE命令;
- 服务器在300秒内对数据库进行了至少10次修改,那么执行BGSAVE命令;
- 服务器在60秒内对数据库进行了至少10000次修改,那么只需BGSAVE命令。
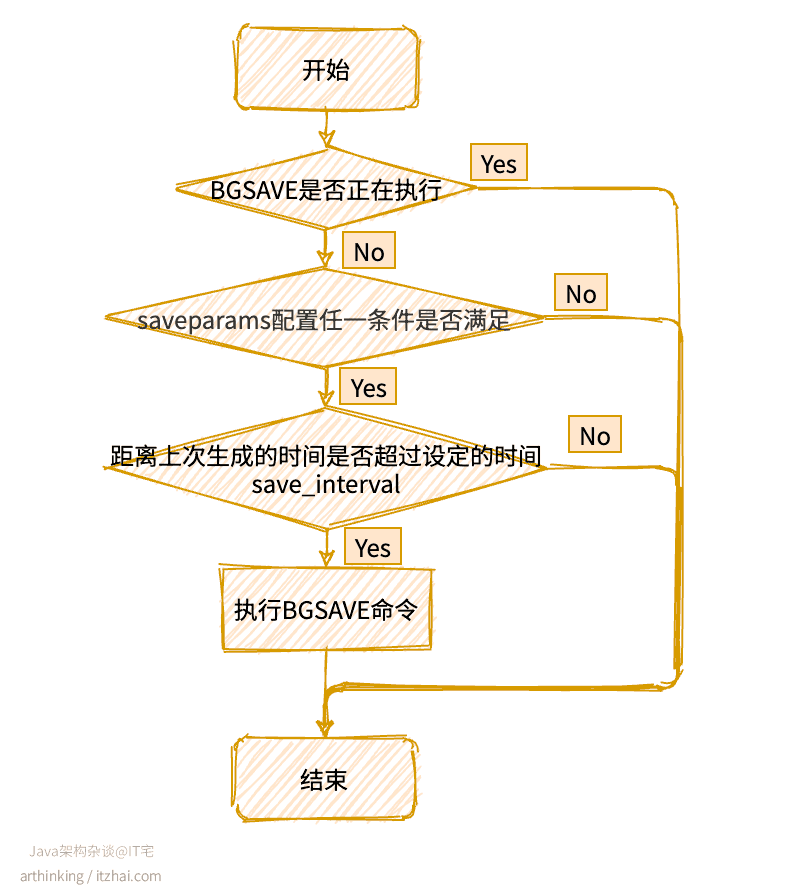
Redis默认的每隔100毫秒会执行一次serverCron函数,检查并执行BGSAVE命令,大致的处理流程如下图所示:
1.2、如何从RDB文件恢复?
Redis只会在启动的时候尝试加载RDB文件,但不是一定会加载RDB文件的,关键处理流程如下图:
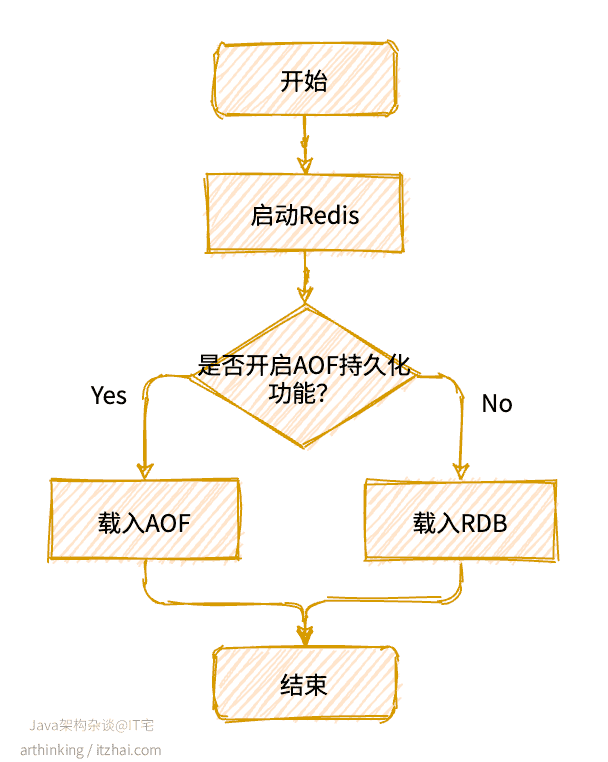
服务器在载入RDB文件期间,一直处于阻塞状态。
1.3、RDB文件结构是怎样的?
我们用一张图来大致了解下RDB文件的结构,如下图所示:
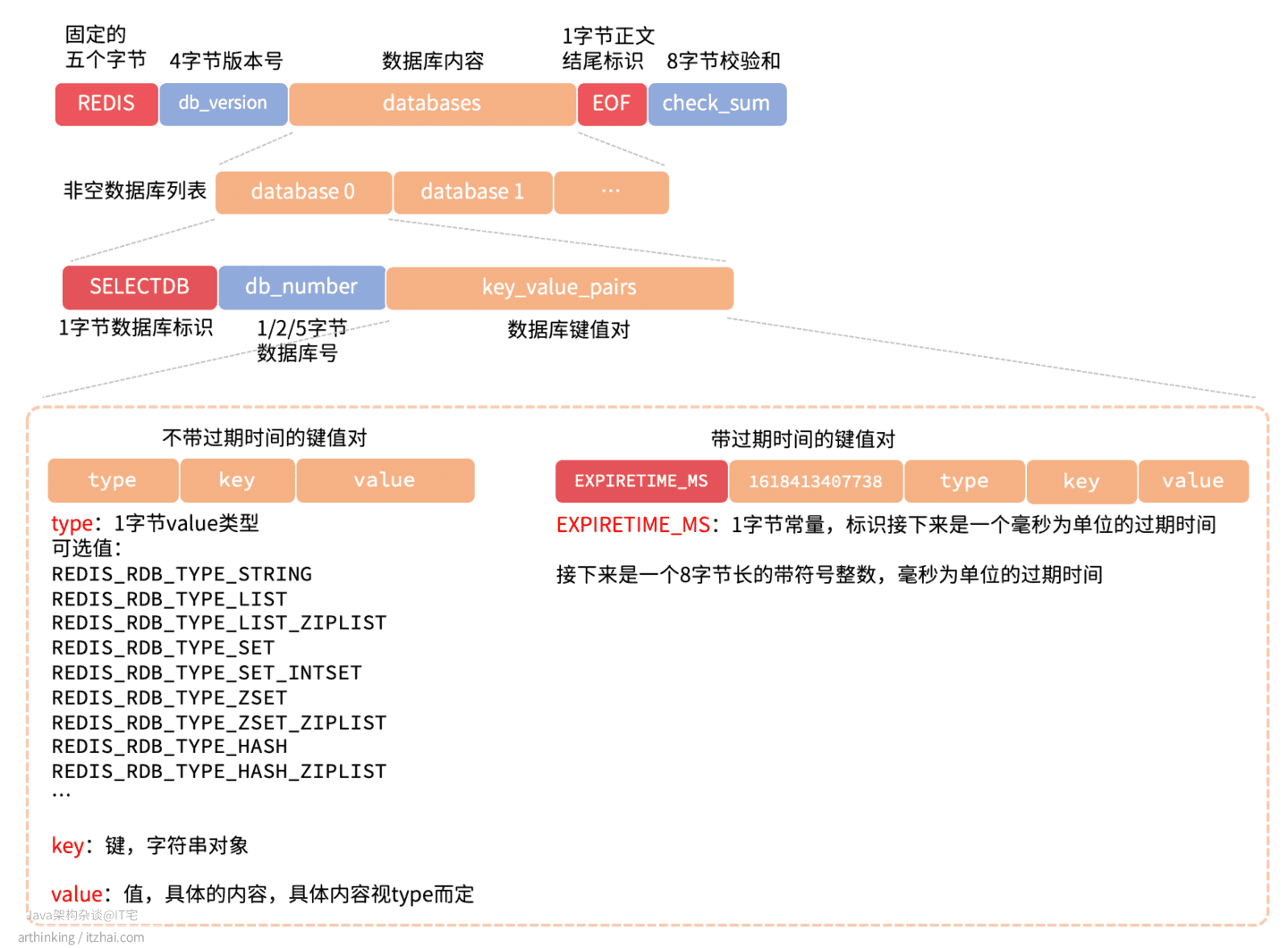
具体格式以及格式说明参考上图以及图中的描述。
而具体的value,根据不同的编码有不同的格式,都是按照约定的格式,紧凑的存储起来。
2、AOF
从上一节的内容可知,RDB是把整个内存的数据按照约定的格式,输出成一个文件存储到磁盘中的。
而AOF(Append Only File)则有所不同,是保存了Redis执行过的命令。
AOF,即Append Only File的简写。
我们先来看看,执行命令过程中是如何生成AOF日志的:
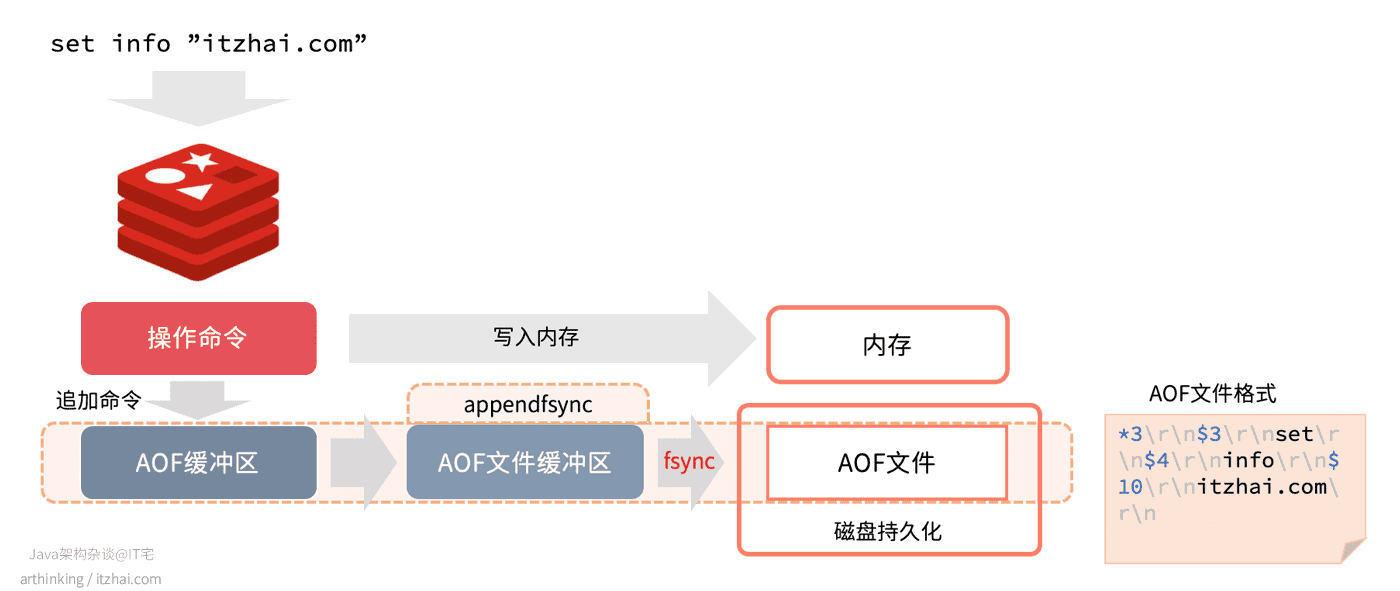
如上图,是Redis执行命令过程中,产生AOF日志的一个过程:
- 执行完命令之后,相关数据立刻写入内存;
- 追加命令到AOF缓冲区(对应redisServer中的aof_buf属性),该缓冲区用于把AOF日志追写回到磁盘的AOF文件中,有三种不同的写回策略,由
appendfsync参数控制:- Always:同步写回,每个写命令执行完毕之后,立刻将AOF缓冲区的内容写入到AOF文件缓冲区,并写回磁盘;
- Everysec:每秒写回,每个写命令执行完后,将AOF缓冲区所有内容写入到AOF文件缓冲区,如果AOF文件上次同步时间距离现在超过了一秒,那么将再次执行AOF文件同步,将AOF文件写回磁盘;
- No:操作系统控制写回,每个写命令执行完毕之后,将AOF缓冲区的内容写入到AOF文件缓冲区,具体写回磁盘的时间,由操作系统的机制来决定。
2.1、AOF文件格式
AOF文件格式如上图最右边所示:
*3:表示当前命令有三部分;$3:每个部分以$ + 数字打头,数字表示这部分有多少字节;- 字符串:该部分具体的命令内容。
2.2、应该用哪种AOF写回策略?
可以看到appendfsync是实现数据持久化的关键技术了,哪种写回策略最好呢?
这里,我们通过一个表格来对比下:
| 写回策略 | 写回时机 | 优点 | 缺点 |
|---|---|---|---|
| Always | 同步写回 | 数据基本不丢失 | 每次写数据都要同步,性能较差 |
| Everysec | 每秒写回 | 性能与可靠性的平衡 | 宕机将丢失一秒的数据 |
| No | 操作系统控制写回 | 性能好 | 宕机将丢失上一次同步以来的数据 |
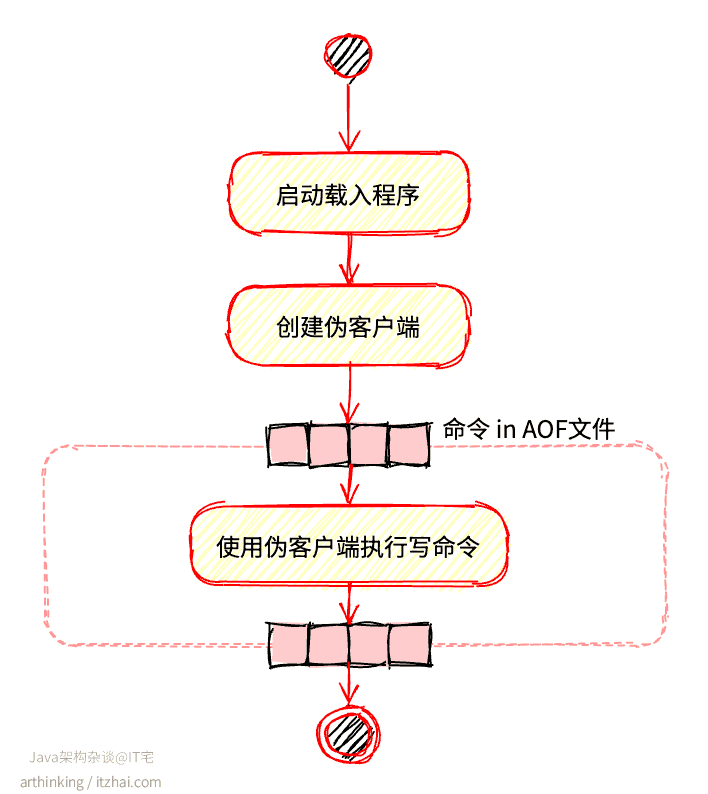
2.3、如何通过AOF实现数据还原?
为了实现数据还原,需要把AOF日志中的所有命令执行一遍,而Redis命令只能在客户端上下文中执行,所以会先创建一个不带网络套接字的伪客户端进行执行命令,大致流程如下:
2.4、AOF文件太大了,影响载入速度怎么办?
如果AOF文件太大,需要执行的命令就很多,载入速度回变慢,为了避免这种问题,Redis中提供了AOF重写机制,把原来的多个命令压缩成一个,从而减小AOF文件的大小和AOF文件中的命令数量,加快AOF文件的载入速度。
Redis中触发AOF重写的是bgrewriteaof命令。
要注意的是,AOF重写并不是读取原来的AOF文件的内容进行重写,而是根据系统键值对的最新状态,生成对应的写入命令。
重写效果
比如执行了以下命令:
1 | RPUSH list "a |
那么,理想的情况,执行AOF重写之后,生成的AOF文件的内容会变为如下所示:
1 | RPUSH list "a" "b" |
最终,每个键,都压缩成了一个命令。
如果集合中的元素太多了,如何生成命令?
为了避免命令太长,导致客户端输入缓冲区溢出,重写生成命令的时候,会检查元素个数,如果超过了
redis.h/REDIS_AOF_REWRITE_ITEMS_PER_CMD(64),那么将拆分为多条命令。
AOF重写运行原理
重写运行原理如下图所示:
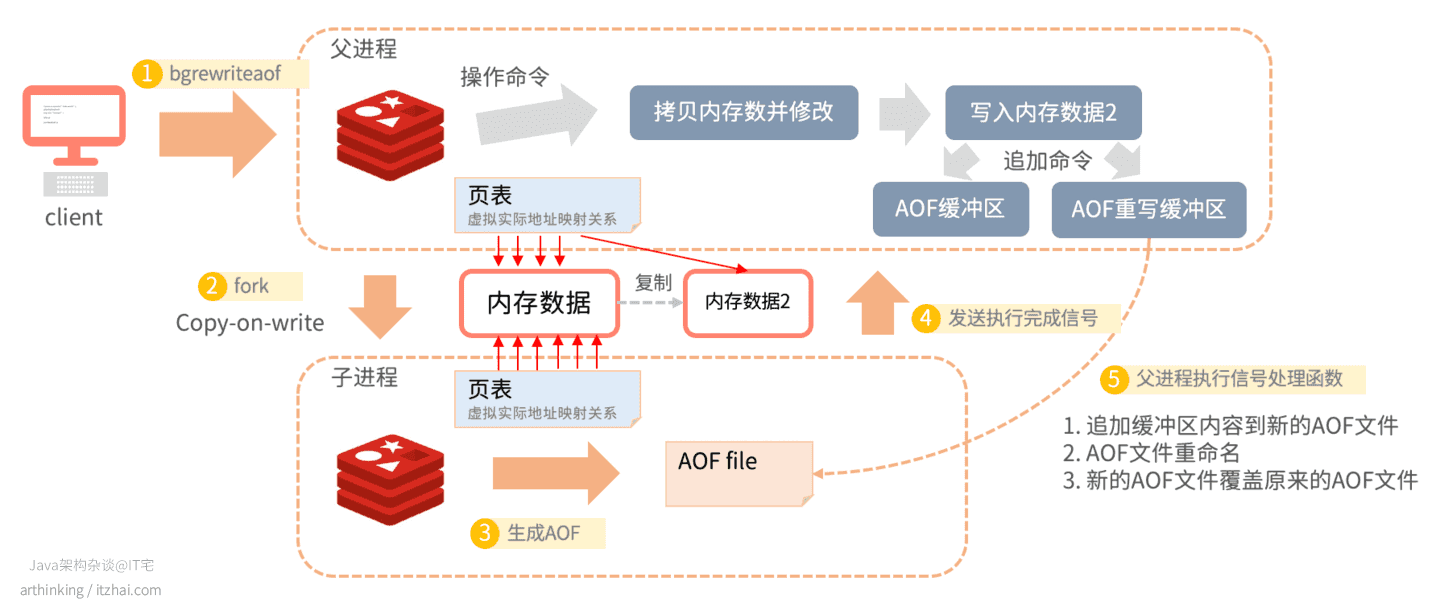
- 1、触发bgrewriteaof命令;
- 2、fork子进程,采用写时复制,复制页表;
- 如果此时父进程还需要执行操作命令,则会拷贝内存数据并修改,同时追加命令到AOF缓冲区和AOF重写缓冲区中;
- 3、根据内存数据生成AOF文件;
- 4、生成完成之后,向父进程发送信号;
- 5、父进程执行信号处理函数,这一步会把AOF重写缓冲区中的数据追加到新生成的AOF文件中,最终替换掉旧的AOF文件。
AOF重写涉及到哪些关键设计点?
不停服:所谓的不停服,指的是父进程可以继续执行命令;双写:因为重写不一定会成功,所以在重写过程中执行的操作命令,需要同时写到AOF缓冲区和AOF重写缓冲区中。这样一来:- 即使重写失败了,也可以继续使用AOF缓冲区,把数据回写到AOF文件;
- 如果重写成功了,那么就把AOF重写缓冲区的数据追加到新的AOF文件即可;
内存优化:这里采用的是写时复制技术,保证fork效率,以及尽可能少的占用过多的内存。
3、有没有那种快速恢复、开销小、数据不丢失的持久化方案?
Redis 4.0开始提供了RDB+AOF的混合持久化方式,结合了两者的优点。对应的配置项开关为:aof-use-rdb-preamble。
开启了混合持久化之后,serverCron定时任务以及BGREWRITEAOF命令会触发生成RDB文件,在两次生成RDB文件之间执行的操作命令,使用AOF日志记录下来。
最终生成的RDB和AOF都存储在一个文件中。
通过这种方案,基本保证了数据的不丢失,但是在分布式主从集群系统中,一旦发生了故障导致主从切换或者脑裂问题,就不可避免的导致主从数据不一致,可能导致数据丢失。有没有修复主从数据不一致问题的方法决定了数据会不会丢失,很可惜,Redis不管怎么做,都是有可能丢失消息的,我们在分布式章节会详细介绍这类问题。
4、RDB、AOF仍然不够快?
虽然RDB文件生成,或者AOF重写都用上了写时复制技术,但是如果内存中的数据实在太多了,那也是会造成Redis实例阻塞的。
有没有更好的方案呢?有,可以实现的思路:让内存中的数据不能保存太多,内存只存储热点数据,对于冷数据,可以写入到SSD硬盘中,再把未写入SSD硬盘的数据通过某种方式记录下来,可以参考MySQL的binlog,这样不用RDB或者AOF,就实现了数据的持久化。
比如,360开源的Pika。
不过该方案也是有缺点的,如果要频繁的从SSD中加载数据,那么查询的性能就会低很多。另外SSD硬盘的使用寿命也和擦写次数有关,频繁的改写,SSD硬盘成本也是一个问题。
这种方案适合需要大容量存储、访问延迟没有严格要求低业务场景中使用。

