

对象可以理解为Redis的数据类型,数据类型底层可以使用不同的数据结构来实现。
我们先来看看对象的基本格式:
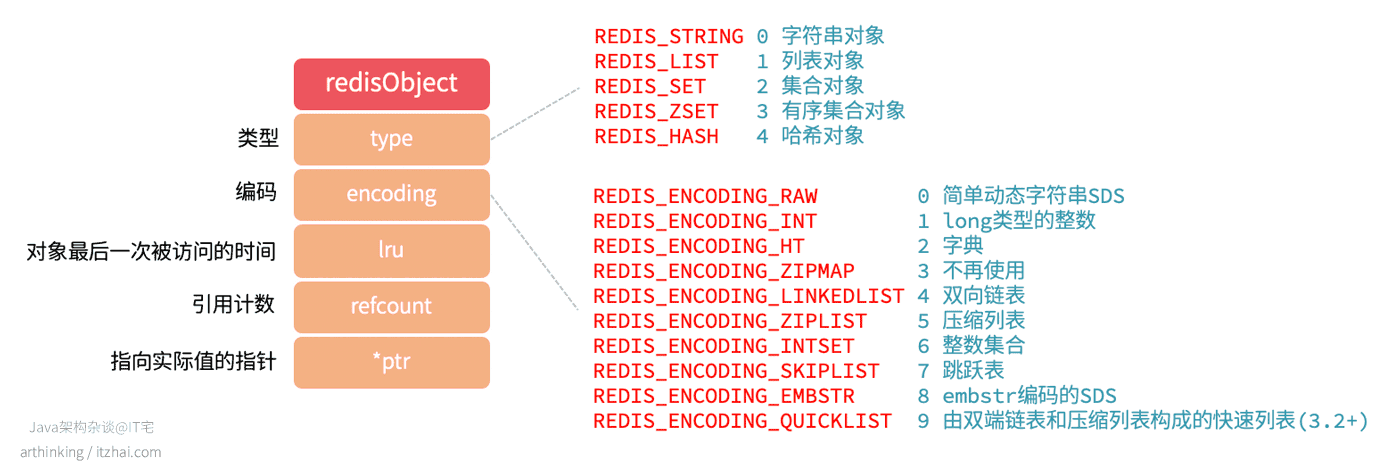
常见的有5种数据类型,底层使用10种数据结构实现,随着Redis版本的升级,数据类型和底层的数据结构也会增加。
而这5种数据类型,根据不同场景来选择不同的编码格式,如下表所示:
| 数据类型 | 编码格式 |
|---|---|
| REDIS_STRING | REDIS_ENCODING_INT |
| REDIS_ENCODING_EMBSTR | |
| REDIS_ENCODING_RAW | |
| REDIS_LIST | REDIS_ENCODING_LINKEDLIST |
| REDIS_ENCODING_ZIPLIST | |
| REDIS_ENCODING_QUICKLIST | |
| REDIS_SET | REDIS_ENCODING_INTSET |
| REDIS_ENCODING_HT | |
| REDIS_ZSET | REDIS_ENCODING_ZIPLIST |
| REDIS_ENCODING_SKIPLIST | |
| REDIS_HASH | REDIS_ENCODING_ZIPLIST |
| REDIS_ENCODING_HT |
Redis对象的其他特性:
- 对象共享:多个键都需要保存同一个字面量的字符串对象,那么多个键将共享同一个字符串对象,其中对象的refcount记录了该对象被引用的次数;
- 内存回收:Redis实现了基于引用计数的内存回收机制,当对象的refcount变为0的时候,就表示对象可以被回收了;
- 空转时长:通过
OBJECT IDLETIME命令,可以获取键的空转时长,该时长为当前时间 - 对象lru时间计算得到,lru记录了对象最后一次被命令访问的时间。
接下来我们逐个展示。
1、REDIS_STRING
REDIS_ENCODING_INT
如果一个字符串对象保存的是整数,并且可以用long类型表示,那么ptr会从void * 变为long类型,并且设置字符串编码为REDIS_ENCODING_INT。
1 | 127.0.0.1:6379> set itzhai 10000 |

REDIS_ENCODING_EMBSTR
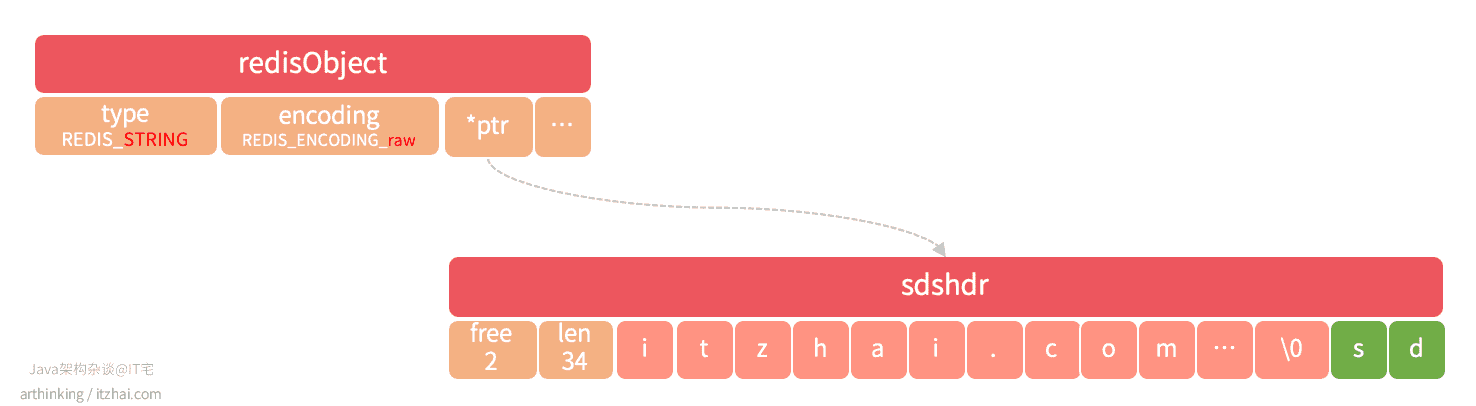
如果存储的是字符串,并且值长度小于等于44个字节,那么将使用embstr编码的SDS来保存这个字符串值。
raw编码的SDS会调用两次内存分配函数来分别创建redisObject和sdshdr结构,而embstr编码只需要调用一次内存分配函数就可以了,redisObject和sdshdr保存在一块连续的空间中,如下图:

1 | 127.0.0.1:6379> set name "itzhai" |
REDIS_ENCODING_RAW
如果存储的是字符串值,并且值长度大于44字节,那么将使用SDS来保存这个字符串值,编码为raw:
1 | 27.0.0.1:6379> set raw_string "abcdefghijklmnopqrstuvwxyzabcdefghijklumnopqr" |
注意:不同版本的Redis,Raw和embstr的分界字节数会有所调整,本节指令运行于 Redis 6.2.1
STRING是如何进行编码转换的?
浮点数会以REDIS_ENCODING_EMBSTR编码的格式存储到Redis中:
1 | 127.0.0.1:6379> OBJECT ENCODING test |
long类型的数字,存储之后,为REDIS_ENCODING_INT编码,追加字符串之后,为REDIS_ENCODING_RAW编码:
1 | 127.0.0.1:6379> set test 12345 |
REDIS_ENCODING_EMBSTR 类型的数据,操作之后,变为REDIS_ENCODING_RAW编码:
1 | 127.0.0.1:6379> OBJECT ENCODING test |
总结一下:
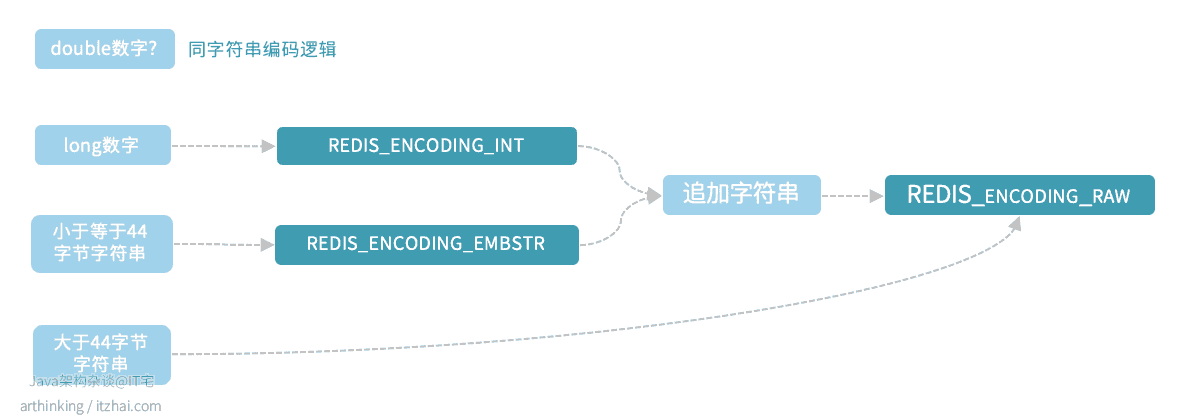
EMBSTR编码的字符串不管追加多少字符,不管有没有到达45字节大小,都会转为RAW编码,因为EMBSTR编码字符串没有提供修改的API,相当于是只读的,所以修改的时候,总是会先转为RAW类型再进行处理。
2、REDIS_LIST
Redis 3.2版本开始引入了quicklist,LIST底层采用的数据结构发生了变化。
Redis 3.2之前的版本
列表对象底层可以是ziplist或者linkedlist数据结构。
使用哪一种数据结构:
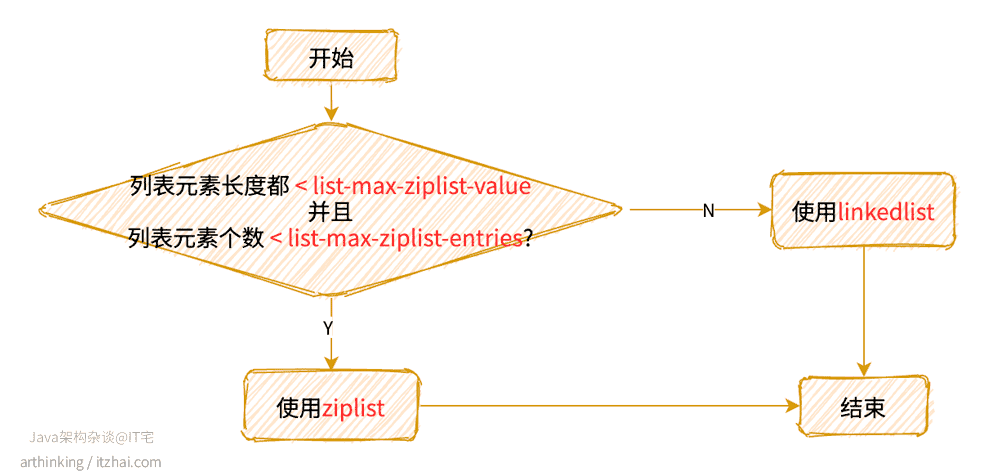
REDIS_ENCODING_ZIPLIST
ziplist结构的列表对象如下图所示:
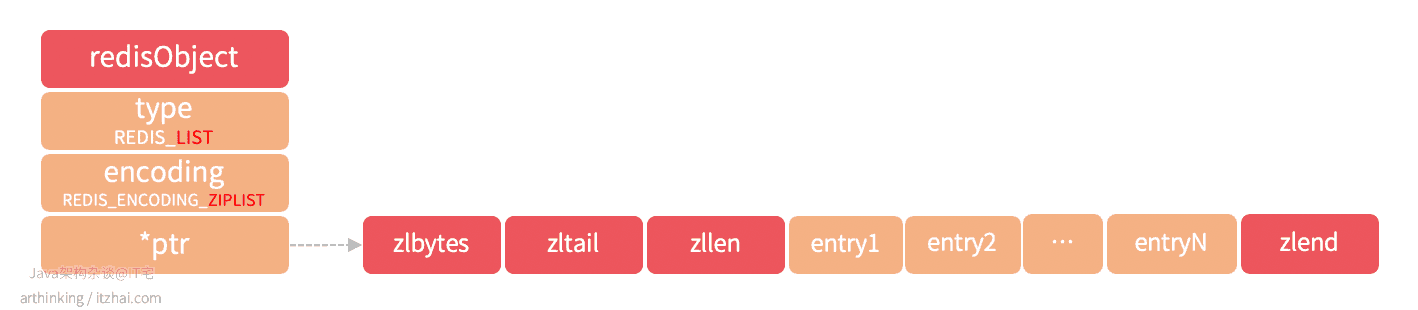
REDIS_ENCODING_LINKEDLIST
linkedlist结构的列表对象如下图所示
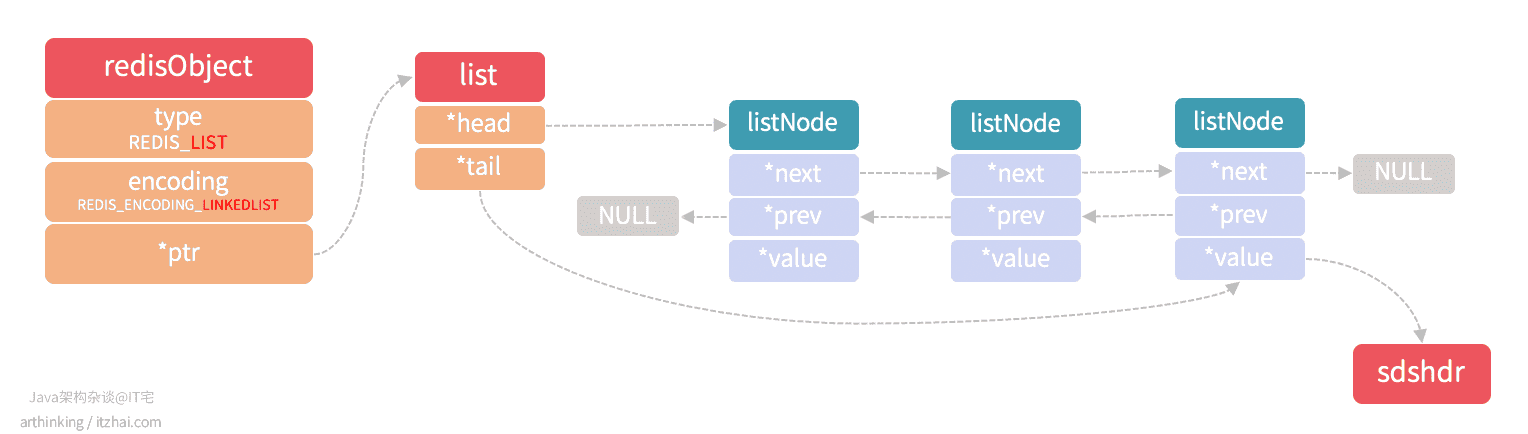
linkedlist为双向列表,每个列表的value是一个字符串对象,在Redis中,字符串对象是唯一一种会被其他类型的对接嵌套的对象。
Redis 3.2之后的版本
而Redis 3.2之后的版本,底层采用了quicklist数据结构进行存储。
3、REDIS_HASH
哈希对象的编码可以使ziplist或者hashtable数据结构。
使用哪一种数据结构:
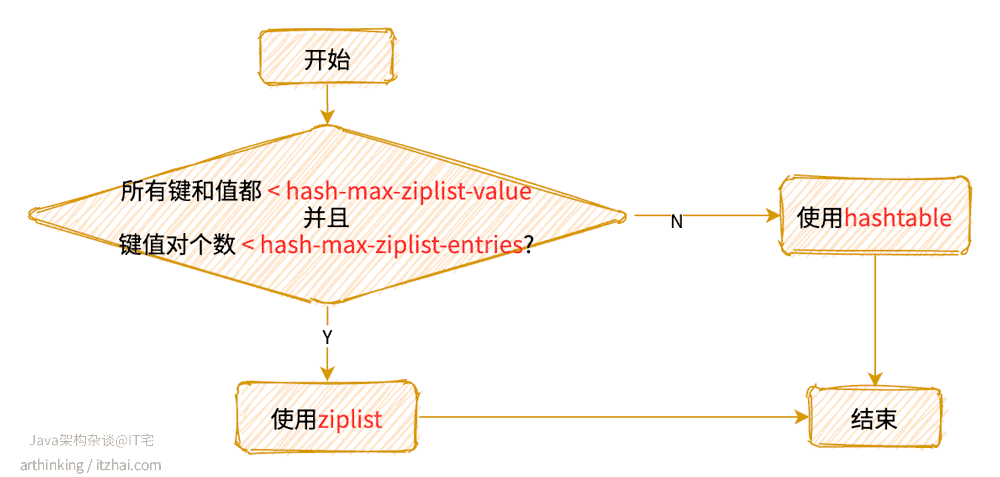
REDIS_ENCODING_ZIPLIST
我们执行以下命令:
1 | 127.0.0.1:6379> HSET info site itzhai.com |
得到如下ziplist结构的哈希对象:
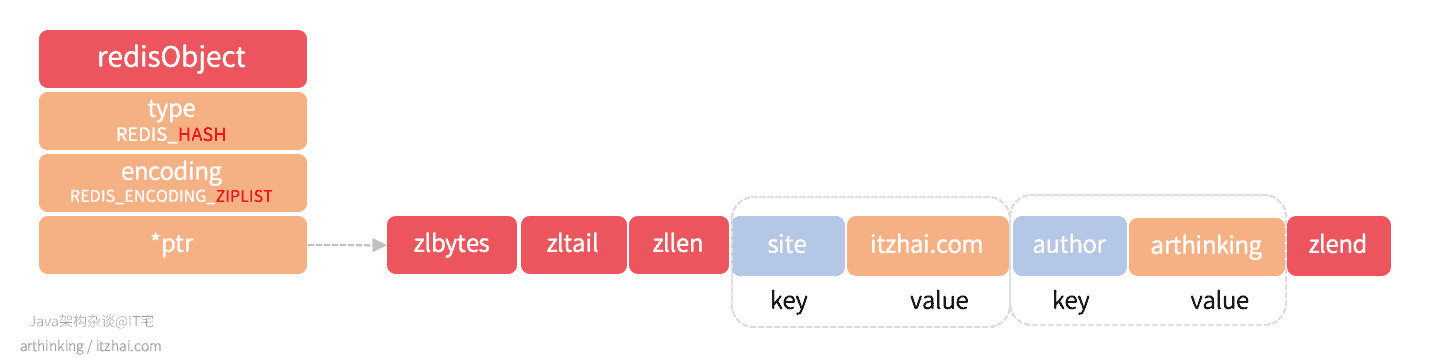
REDIS_ENCODING_HT
hashtable结构的哈希对象如下图所示:
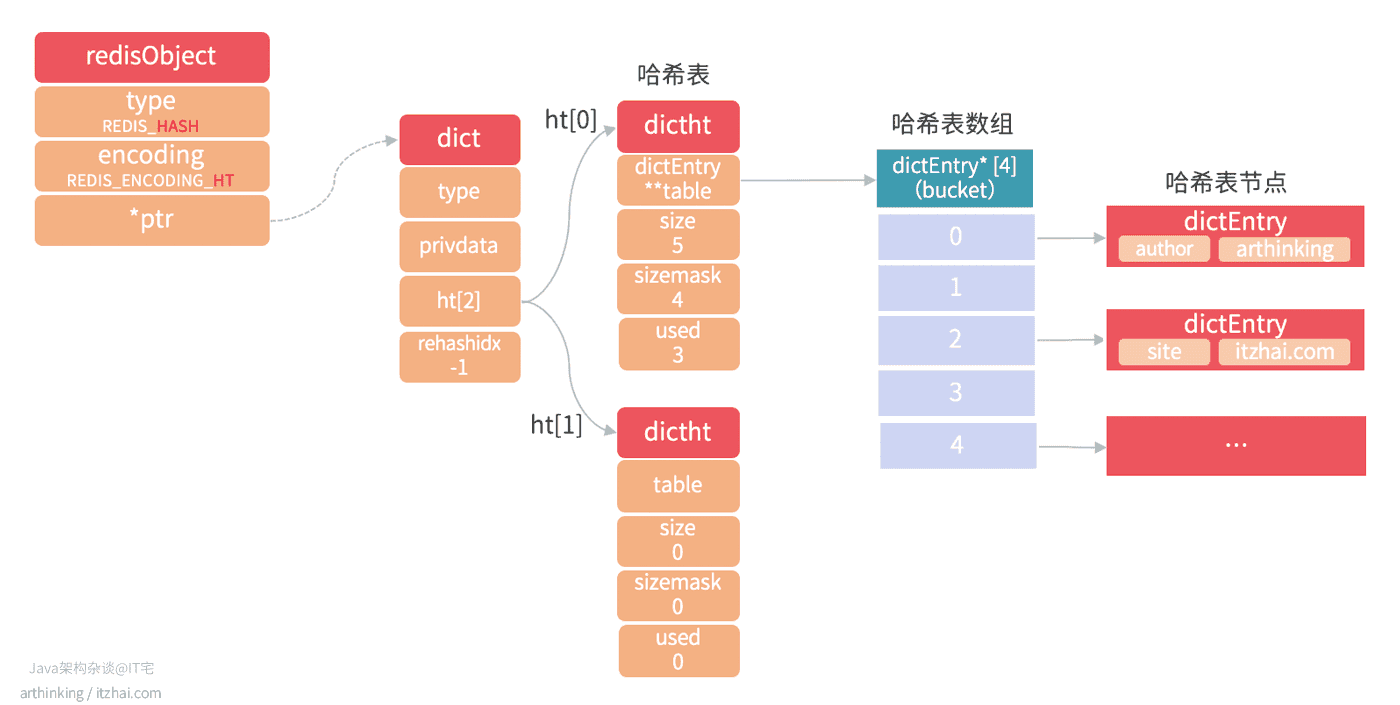
其中,字典的每个键和值都是一个字符串对象。
4、REDIS_SET
集合对象的编码可以是intset或者hashtable数据结构。
使用哪一种数据结构:
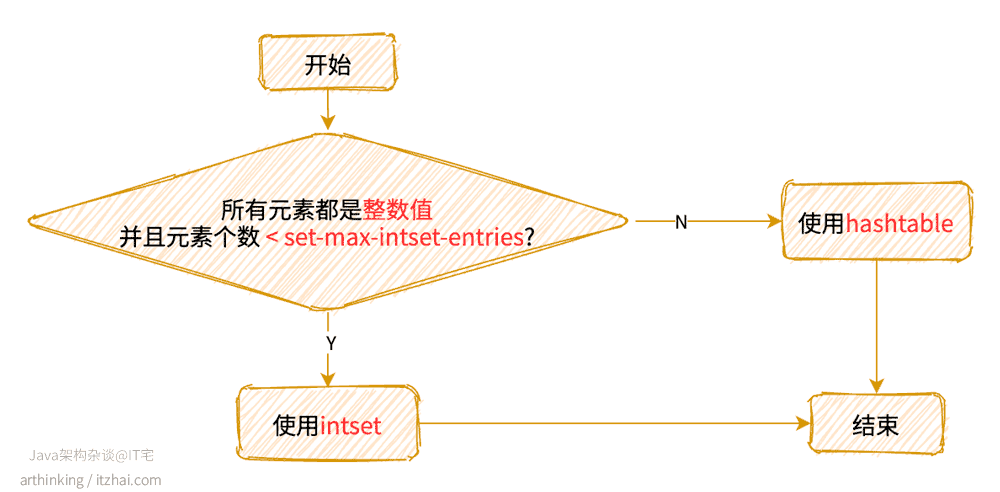
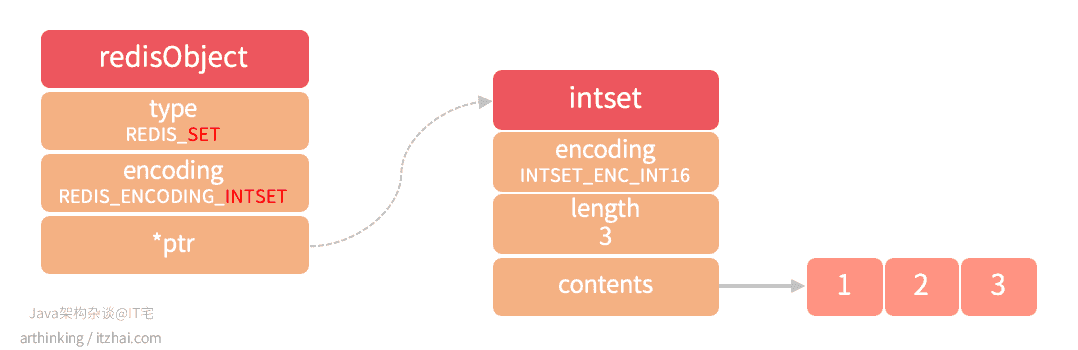
REDIS_ENCODING_INTSET
执行以下命令:
1 | 127.0.0.1:6379> SADD ids 1 3 2 |
则会得到一个intset结构的集合对象,如下图:
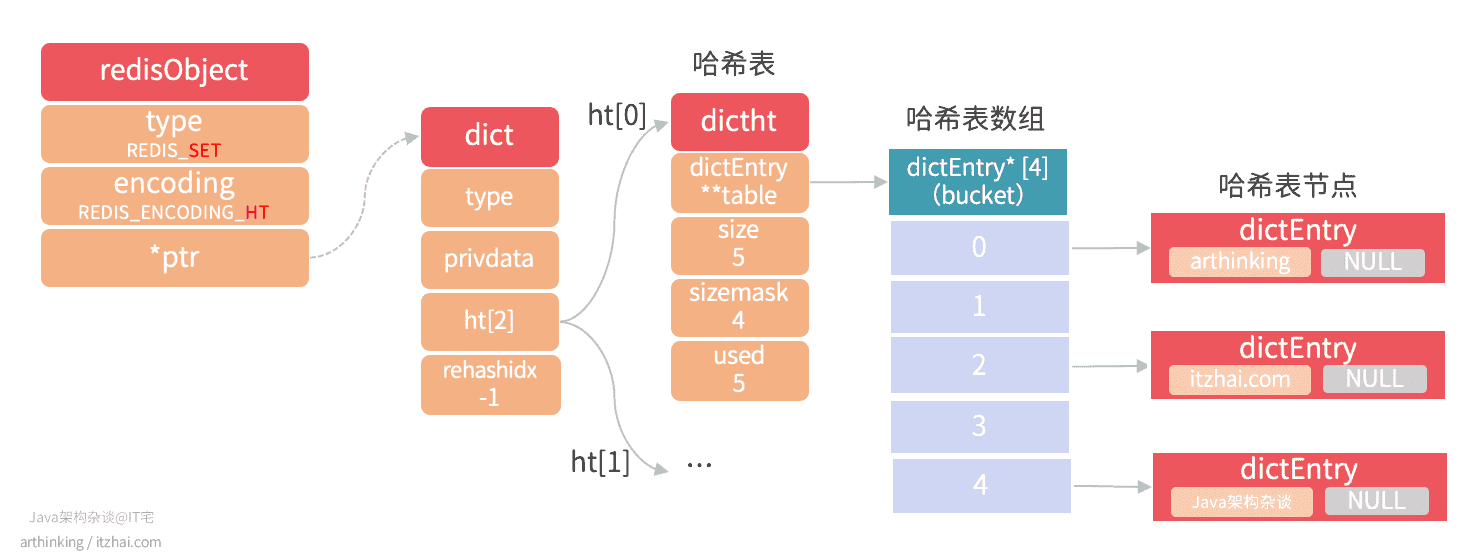
REDIS_ENCODING_HT
执行以下命令:
1 | 127.0.0.1:6379> SADD site_info "itzhai.com" "arthinking" "Java架构杂谈" |
则会得到一个hashtable类型的集合对象,hashtable的每个键都是一个字符串对象,每个字符串对象包含一个集合元素,hashtable的值全部被置为NULL,如下图:
5、REDIS_ZSET
有序集合可以使用ziplist或者skiplist编码。
使用哪一种编码:
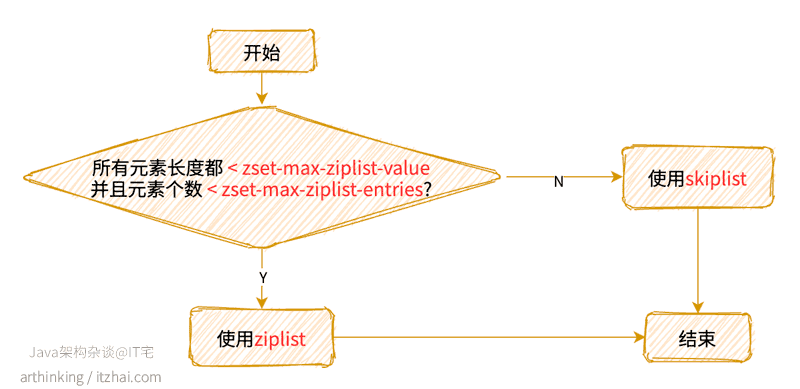
REDIS_ENCODING_ZIPLIST
执行以下命令:
1 | 127.0.0.1:6379> ZADD weight 1.0 "Java架构杂谈" 2.0 "arthinking" 3.0 "itzhai.com" |
则会得到一个ziplist编码的zset,如下图:

REDIS_ENCODING_SKIPLIST
执行以下命令:
1 | 127.0.0.1:6379> ZADD weight 1 "itzhai.com" 2 "aaaaaaaaaabbbbbbbbbccccccccccddddddddddeeeeeeeeeeffffffffffgggggg" |
则会得到一个skiplist编码的zset,skiplist编码的zset底层同时包含了一个字典和跳跃表:
1 | typedef struct zset { |
如下图所示:
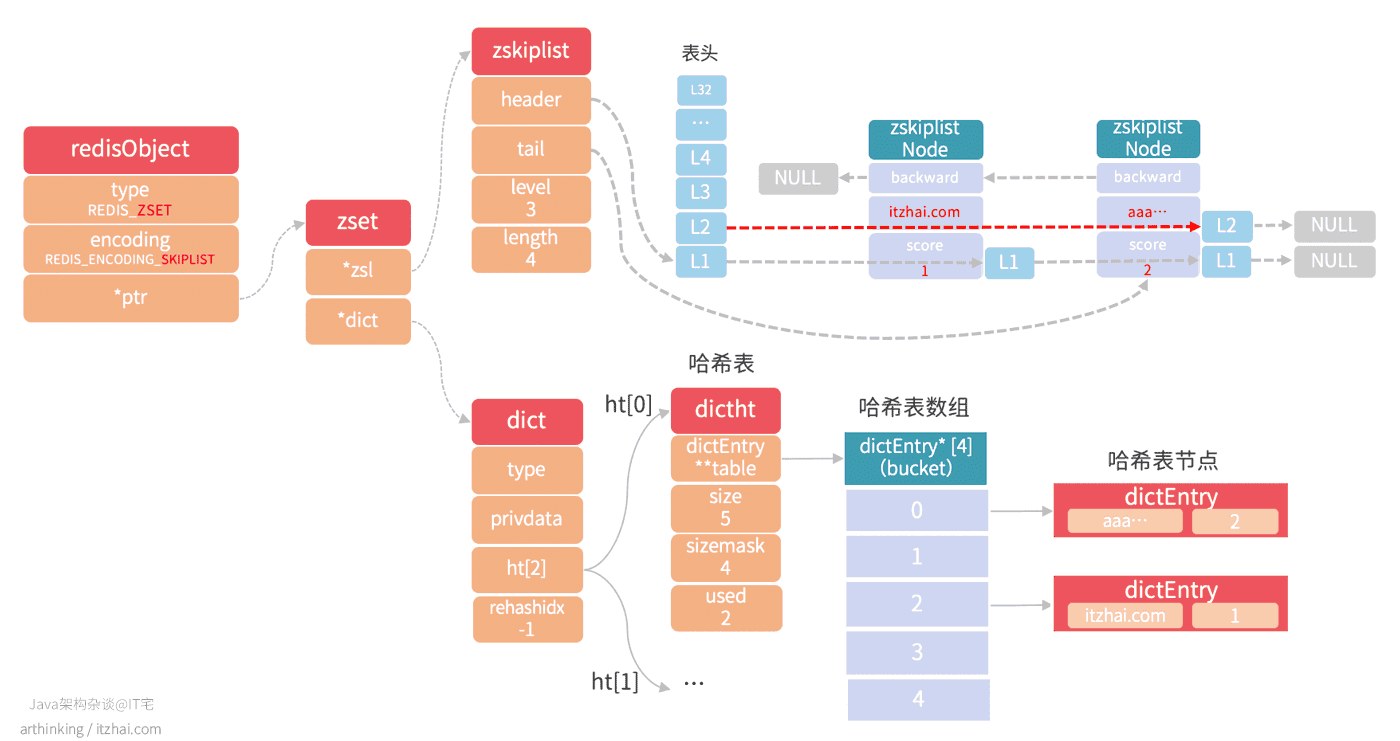
其中:
- 跳跃表按照分值从小到大保存了所有的集合元素,一个跳跃表节点对应一个集合元素,object属性保存元素成员,score属性保存元素的分值,ZRANK,ZRANGE,ZCARD,ZCOUNT,ZREVRANGE等命令基于跳跃表来查找的;
- 字典维护了一个从成员到分值的映射,通过该结构查找给定成员的分值(ZSCORE),复杂度为O(1);
- 实际上,字典和跳跃表会共享元素成员和分值,所以不会造成额外的内存浪费。
6、REDIS_MODULE
从Redis 4.0开始,支持可扩展的Module,用户可以根据需求自己扩展Redis的相关功能,并且可以将自定义模块作为插件附加到Redis中。这极大的丰富了Redis的功能。
关于Modules的相关教程:Redis Modules: an introduction to the API[1]
Redis第三方自定义模块列表(按照GitHub stars数排序):Redis Modules[2]
7、REDIS_STREAM
这是Redis 5.0引入的一个新的数据类型。为什么需要引入这个数据类型呢,我们可以查阅一下:RPC11.md | Redis Change Proposals[3]:
1 | This proposal originates from an user hint: |
这使得Redis作者去思考Apache Kafka提供的类似功能。同时,它有点类似于Redis LIST和Pub / Sub,不过有所差异。
STREAM工作原理
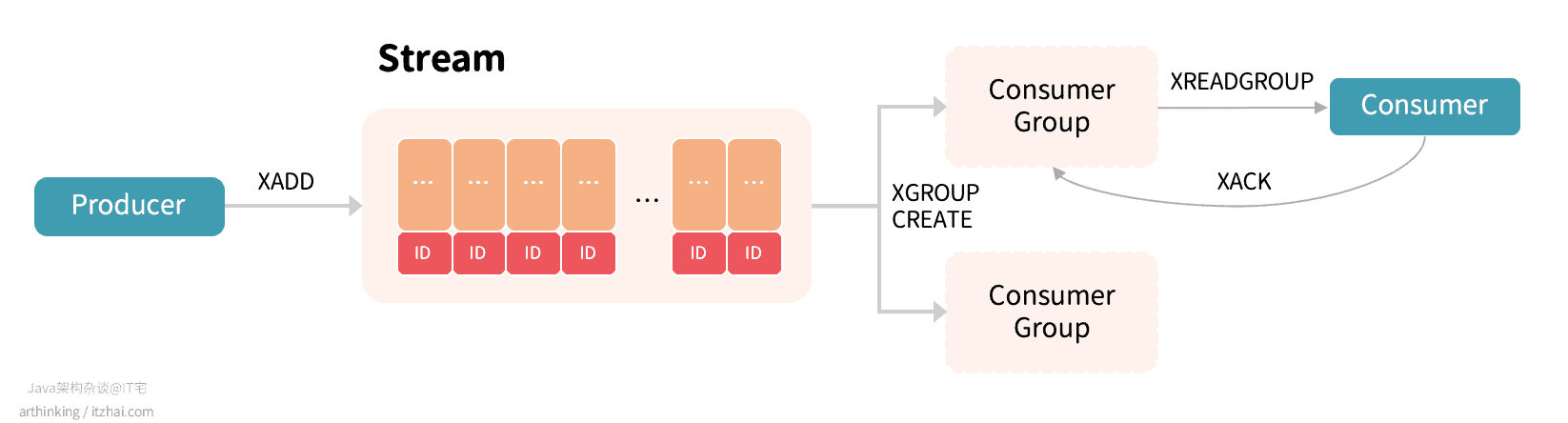
如上图:生产者通过XADD API生产消息,存入Stream中;通过XGROUP相关API管理分组,消费者通过XREADGROUP命令从消费分组消费消息,同一个消费分组的消息只会分配各其中的一个消费者进行消费,不同消费分组的消息互不影响(可以重复消费相同的消息)。
Stream中存储的数据本质是一个抽象日志,包含:
- 每条日志消息都是一个结构化、可扩展的键值对;
- 每条消息都有一个唯一标识ID,标识中记录了消息的时间戳,单调递增;
- 日志存储在内存中,支持持久化;
- 日志可以根据需要自动清理历史记录。
Stream相关的操作API
-
添加日志消息:
-
XADD:这是将数据添加到Stream的唯一命令,每个条目都会有一个唯一的ID:1
2
3
4
5
6# * 表示让Redis自动生成消息的ID
127.0.0.1:6379> XADD articles * title redis author arthinking
# 自动生成的ID
1621773988308-0
127.0.0.1:6379> XADD articles * title mysql author Java架构杂谈
1621774078728-0
-
-
读取志消息:
-
XREAD:按照ID顺序读取日志消息,可以从多个流中读取,并且可以以阻塞的方式调用:1
2
3
4
5
6
7
8
9
10
11
12# 第一个客户端执行以下命令,$ 表示获取下一条消息,进入阻塞等待
127.0.0.1:6379> XREAD BLOCK 10000 STREAMS articles $
# 第二个客户端执行以下命令:
127.0.0.1:6379> XADD articles * title Java author arthinking
1621774841555-0
# 第一个客户端退出阻塞状态,并输出以下内容
articles
1621774841555-0
title
Java
author
arthinking -
XRANGE key start end [COUNT count]:按照ID范围读取日志消息; -
XREVRANGE key end start [COUNT count]:以反向的顺序返回日志消息;
-
-
删除志消息:
XDEL key ID [ID ...]:从Stream中删除日志消息;XTRIM key MAXLEN|MINID [=|~] threshold [LIMIT count]:XTRIM将Stream裁剪为指定数量的项目,如有需要,将驱逐旧的项目(ID较小的项目);
-
消息消费:
-
XGROUP:用于管理消费分组:1
2
3
4
5
6
7
8# 给articles流创建一个group,$表示使用articles流最新的消息ID作为初始ID,后续group内的Consumer从初始ID开始消费
127.0.0.1:6379> XGROUP CREATE articles group1 $
# 指定消费组的消费初始ID
127.0.0.1:6379> XGROUP SETID articles group1 1621773988308-0
OK
# 删除指定的消费分组
127.0.0.1:6379> XGROUP DESTROY articles group1
1 -
XREADGROUP:XREADROUP是对XREAD的封装,支持消费组:1
2
3
4
5
6
7
8# articles流的group1分组中的消费者consumer-01读取消息,> 表示读取没有返回过给别的consumer的最新消息
127.0.0.1:6379> XREADGROUP GROUP group1 consumer-01 COUNT 1 STREAMS articles >
articles
1621774078728-0
title
mysql
author
Java架构杂谈 -
XPENDING key group [start end count] [consumer]:检查待处理消息列表,即每个消费组内消费者已读取,但是尚未得到确认的消息; -
XACK:Acknowledging messages,用于确保客户端正确消费了消息之后,才提供下一个消息给到客户端,避免消息没处理掉。执行了该命令后,消息将从消费组的待处理消息列表中移除。如果不需要ACK机制,可以在XREADGROUP中指定NOACK:1
2127.0.0.1:6379> XACK articles group1 1621776474608-0
1 -
XCLAIM:如果某一个客户端挂了,可以使用此命令,让其他Consumer主动接管它的pending msg:1
2# 1621776677265-0 消息闲置至少10秒并且没有原始消费者或其他消费者进行推进(确认或者认领它)时,将所有权分配给消费者consumer-02
XCLAIM articles group1 consumer-02 10000 1621776677265-0
-
-
运行信息:
XINFO:用于检索关于流和关联的消费者组的不同的信息;XLEN:给出流中的条目数。
Stream与其他数据类型的区别
| 特性 | Stream | List, Pub/Sub, Zset |
|---|---|---|
| 查找元素复杂度 | O(long(N)) | List: O(N) |
| 偏移量 | 支持,每个消息有一个ID | List:不支持,如果某个项目被逐出,则无法找到最新的项目 |
| 数据持久化 | 支持,Streams持久化道AOF和RDB文件中 | Pub/Sub:不支持 |
| 消费分组 | 支持 | Pub/Sub:不支持 |
| ACK | 支持 | Pub/Sub:不支持 |
| 性能 | 不受客户端数量影响 | Pub/Sub:受客户端数量影响 |
| 数据逐出 | 流通过阻塞以驱逐太旧的数据,并使用Radix Tree和listpack来提高内存效率 | Zset消耗更多内存,因为它不支持插入相同项目,阻止或逐出数据 |
| 随机删除元素 | 不支持 | Zset:支持 |
Redis Stream vs Kafka
Apache Kafka是Redis Streams的知名替代品,Streams的某些功能更收到Kafka的启发。Kafka运行所需的配套比较昂贵,对于小型、廉价的应用程序,Streams是更好的选择。

