

消费的时候,会从集群的Leader节点进行读写请求。
1 生产消息如何投递?
生产者将消息发送到Topic的某一个分区中,一般通过round-robin做简单的负载均衡,也可以通过自定义分区器根据消息中的某一个关键字来做分区,后者使用更广泛。
关于自定义分区器的例子,参考:Custom Partitioner in Kafka: Let’s Take a Quick Tour!. Retrieved from https://dzone.com/articles/custom-partitioner-in-kafka-lets-take-quick-tour[1]
我们可以直接使用Kafka提供的bash脚本来尝试发送消息,接下来演示下。
1.1 ✨发送消息例子

2 生产者相关参数
生产者最重要的三个参数[2]是:
- acks
- compression
- batch size
2.1 投递ack: acks
消息投递的持久化机制。有如下几个配置策略:
acks=0
acks=0:不需要ACK,生产者消息发出之后,不需要等待Broker的确认回复,就可以继续发送下一条消息。
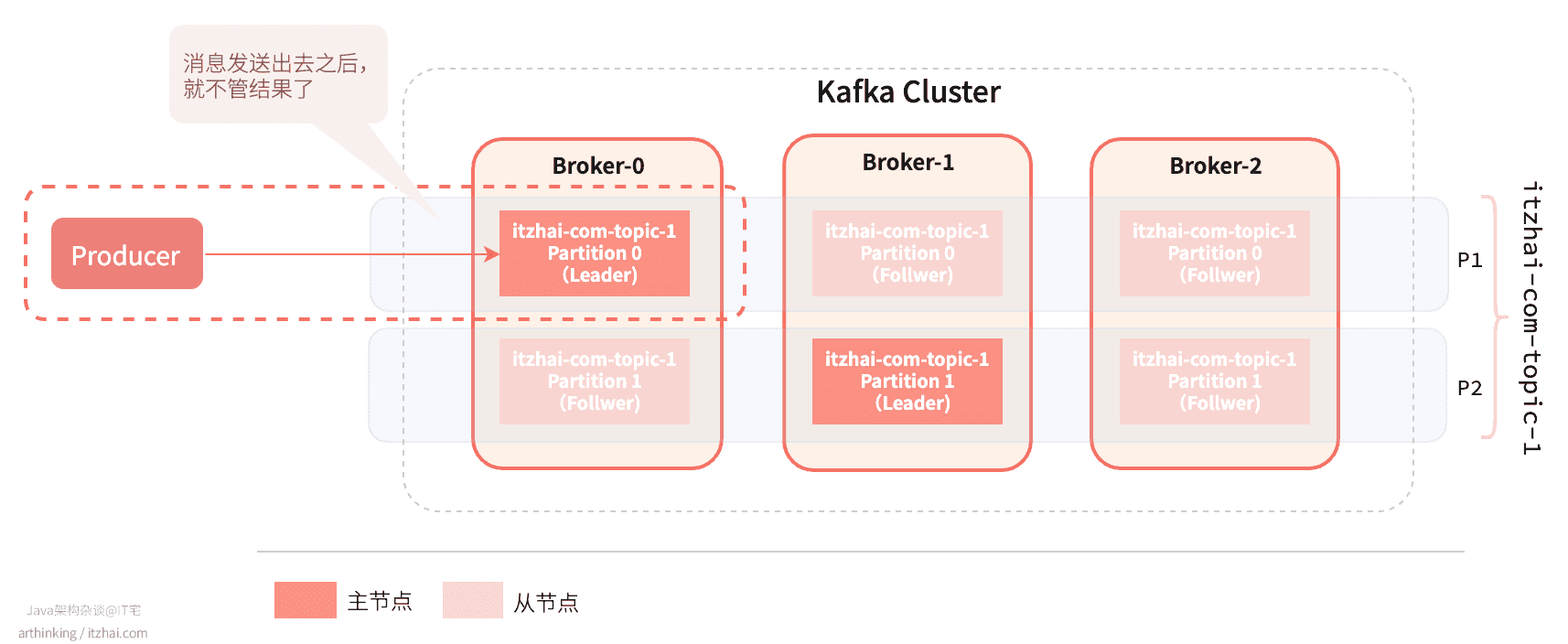
**优点:**性能高;
**缺点:**容易丢消息;
**使用场景:**适合对性能要求比较高但是对数据可靠性要求比较低的场景,如写日志。
acks=1
acks=1: 生产者发出消息后,需要Leader副本的ACK,Leader将数据持久化到本地log之后,就确认回复,而不需要等待Follower副本写入成功。这也是默认的配置值。
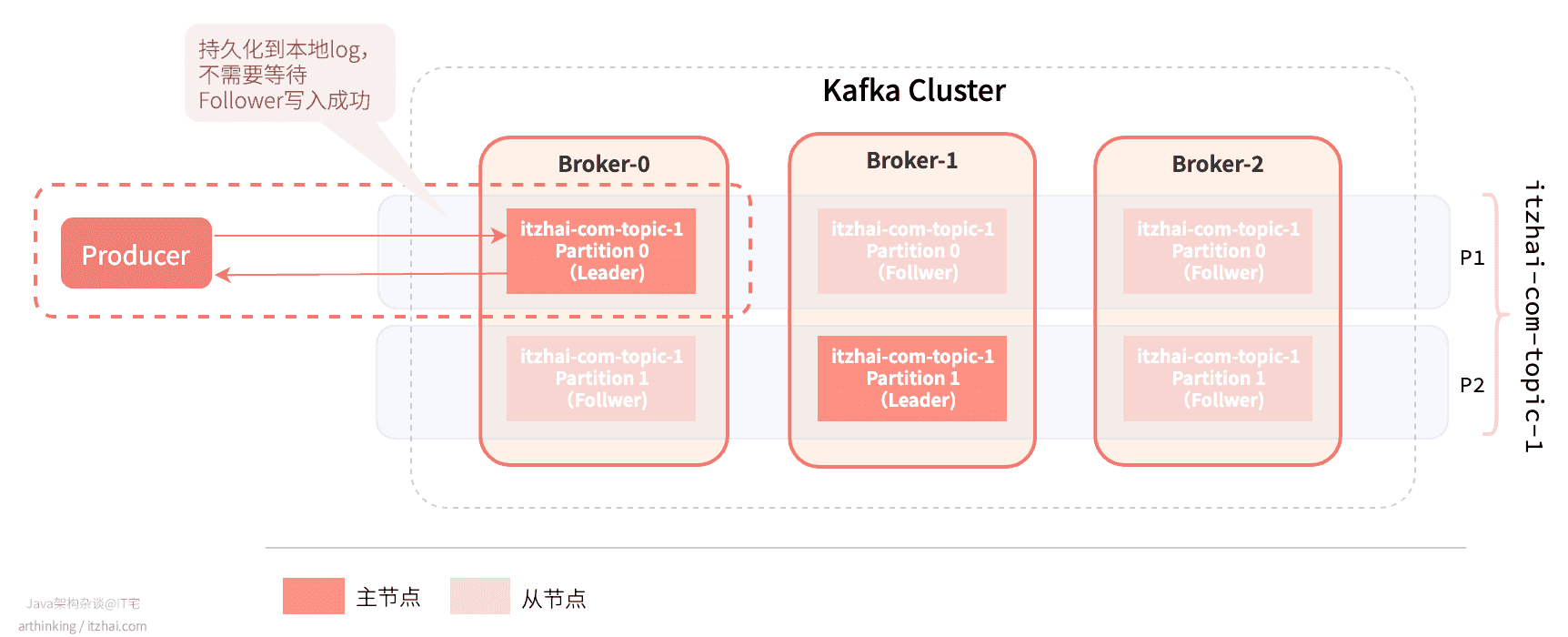
**优点:**比acks=0可靠,确保消息写入到了Leader;
**缺点:**Leader挂掉的时候,Follower没有成功备份数据,那么消息会丢失;
**使用场景:**对消息可靠性有一定要求,但是不是很高,消息丢失之后通过专门的补偿机制去保证数据的完整性,并且对性能要求高的场景。如订单状态更新消息,假如消息丢失了,还有定时任务去轮训补偿。
acks=all 或者 -1
acks=all或者-1: 需要等到min.insync.replicas个副本(包括Leader副本)都成功写入消息,才进行确认回复。Leader挂了,触发选举机制,选举策略是优先选举同步成功的Follower节点为新的Leader。
假设min.insync.replicas=2,则有如下同步过程:
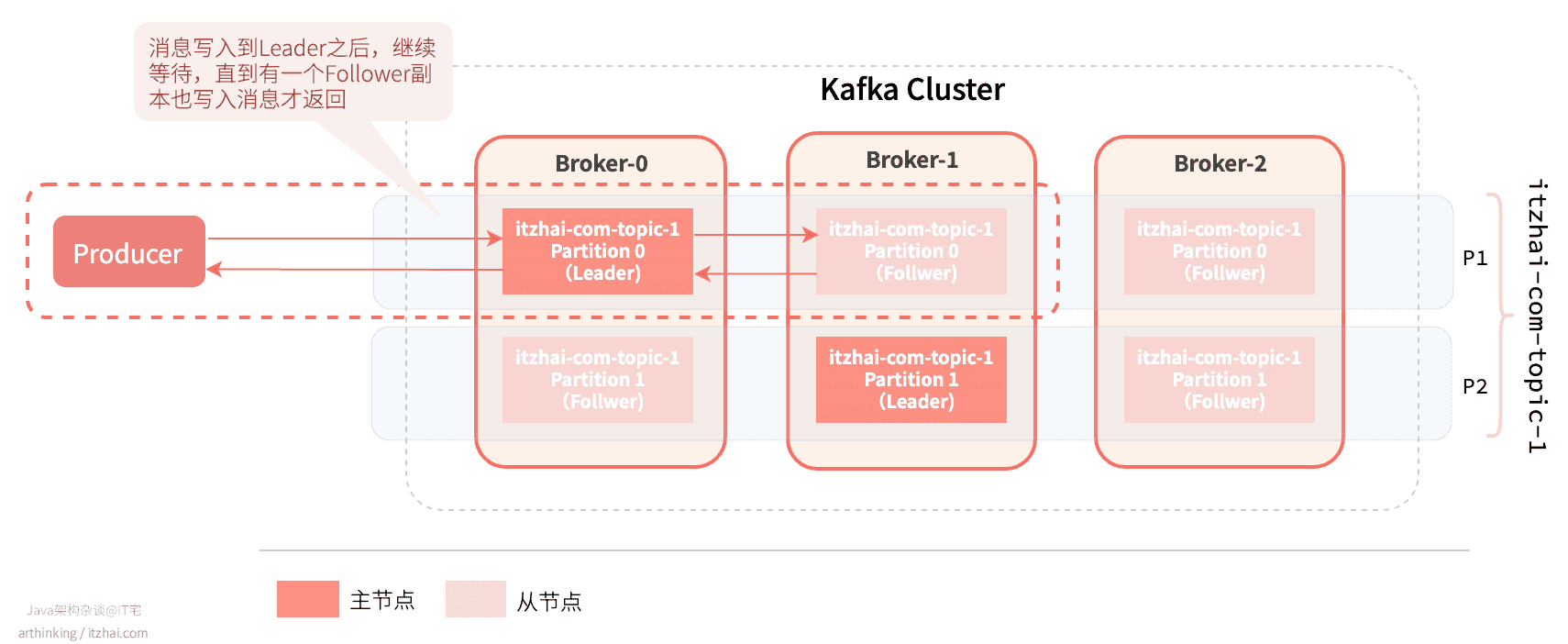
**优点:**消息的可靠性可以得到更大程度的保证;
**缺点:**性能更低;
**使用场景:**对消息可靠性要求很高的场景,不允许丢失消息,如金融业务。
min.insync.replicas
acks=all或者-1时,min.insync.replicas参数设置必须成功写入日志的最小副本个数,如果达不到这个数量,那么生产者将引发异常:NotEnoughReplicas 或者NotEnoughReplicasAfterAppend。
通过配合min.insync.replicas 和 acks 一起使用,你可以拥有更大的持久性保证。
如果要保证更高持久化可靠性,一般的,如果Topic的副本因子为3 ,那么一般将 min.insync.replicas 设置为 2,acks设置为all,如果大多数副本没有收到写入,这将确保生产者引发异常。
2.2 重试: retries和retry.backoff.ms
retries用于配置重试次数,配置为大于0,则在发送失败、网络异常等场景下回触发重新发送。重试可能会导致消息的重复投递,需要消费端做好消费幂等处理。
支持重试可能影响消息的顺序性,比如:
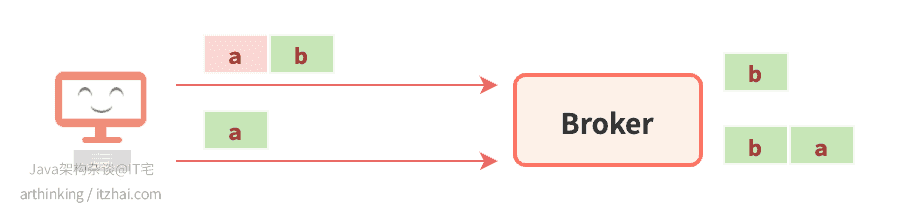
a b两个批次发送到Broker的单个分区中,a批次第一次发送失败了,但是b批次发送成功了,导致Broker先接收到b批次,然后重试发送a批次,最终导致Broker分区中的a b批次消息顺序改变了。
如果需要确保这种情况的顺序性,请配置max.in.flight.requests.per.connection参数的值为1。
如果重试次数用完之前,就到达到了重试超时时间(达到了delivery.timeout.ms配置的值),那么将不继续进行重试。一般的,用户更愿意使用delivery.timeout.ms来控制重试行为。
retry.backoff.ms参数则是用于控制重试间隔。
2.3 分批发送: buffer.memory, batch.size和linger.ms
设置分批发送每个批次的大小。
Kafka为了提高发送消息,将生产者请求传输的所有记录组合成一个一个的批次进行分批发送,这类似于TCP中的Nagle算法。
这个暂存消息的发送缓冲区大小是通过buffer.memory参数进行设置的。
分批批次大小是通过batch.size参数进行设置的。
一旦获取到batch.size大小的批次之后,就立刻发送出去。
linger.ms参数控制最多每间隔多久发送一个批次,如果在linger.ms间隔内就获取到了完整的批次,那么就会立刻发送出去。如果等到linger.ms时间,还没有收集到完整的一批数据,那么也会强制发送出去。
linger.ms默认值为0,表示消息会立即被发送出去,发送效率相对较低。

如果消息生产的速度太慢,为了避免消息一直发送不出去,注意留一下linger.ms配置的发送间隔,可以适当缩小发送间隔。
3 Kafka是如何保证数据的可靠性?
3.1 生产端
在Kafka 0.8.0之前,是没有副本的概念的,数据可能会丢失,只能存储一些不重要的数据。
从0.l8.0banb开始引入了分区副本,每个分区可以配置几个副本。Kafka的分区多副本机制是可靠性保证的核心。
为了保证可靠性,我们可以使用同步发送,根据不同的场景,配置合理的acks参数值。
为了严格保证可靠性,以下是需要的配置:
生产者:acks=all,并且使用同步阻塞的方式发送消息;Topic:replication.factor >= 3,min.insync.replicas >= 2;Broker:unclean.leader.election.enable=false,确保ISR集合中没有可用的在线副本时,不会去选举ISR之外的副本作为新的Leader。
unclean.leader.election.enable设置为true,意味着允许选举非ISR集合的副本作为新的Leader,即使配置了acks=all,新选举出来的Leader也可能消息是落后的。
如下图,原本ISR中有三个副本,某个时间之后,Follower1脱离了ISR,并且落后Leader比较多:
此时ISR中的副本都下线了,unclean.leader.election.enable=true,那么,会把Follower1选举为新的 Leader:
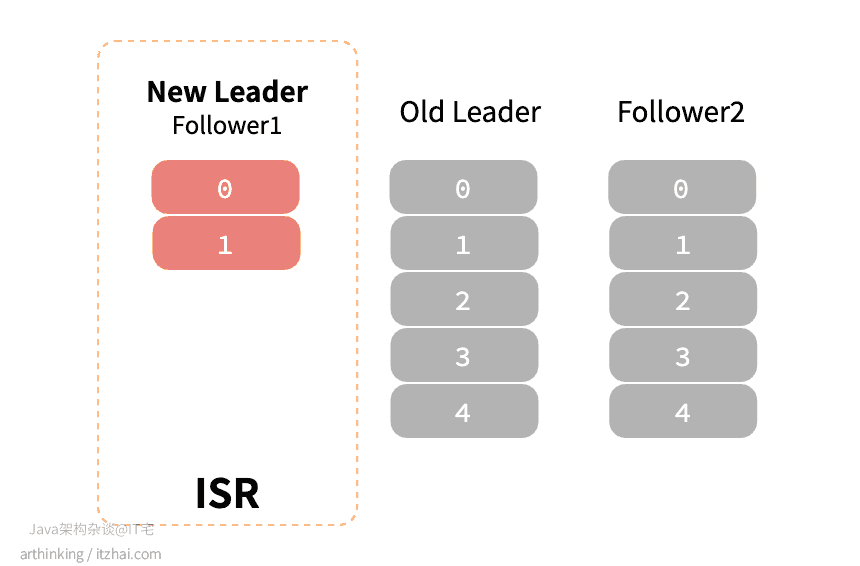
此时新的Leader副本开始接收消息,假如原来的Leader此后又恢复了,称为了新的Follower副本,那么会开始尝试从新的Leader副本同步消息,此时这个新的 Follower副本的LEO比新的Leader还要大,最终会把这个新的Follower副本的日志进行截断,保持与心Leader一致,最终导致数据丢失:
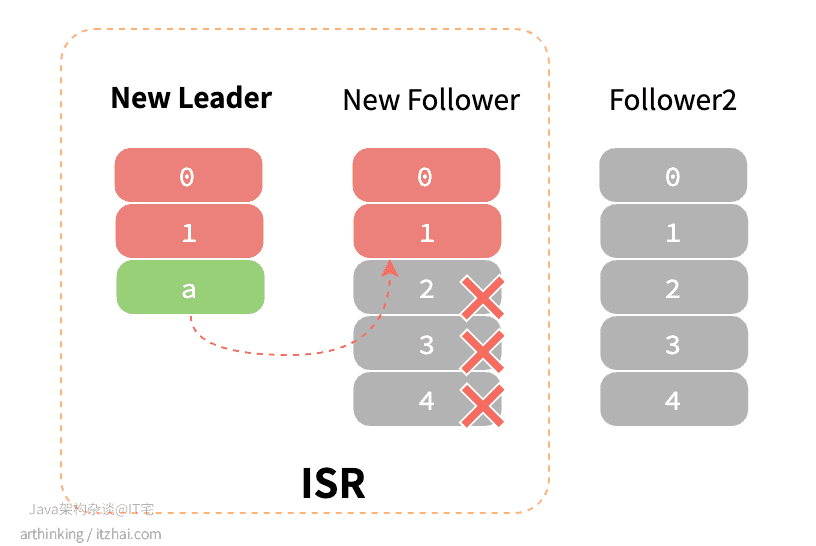
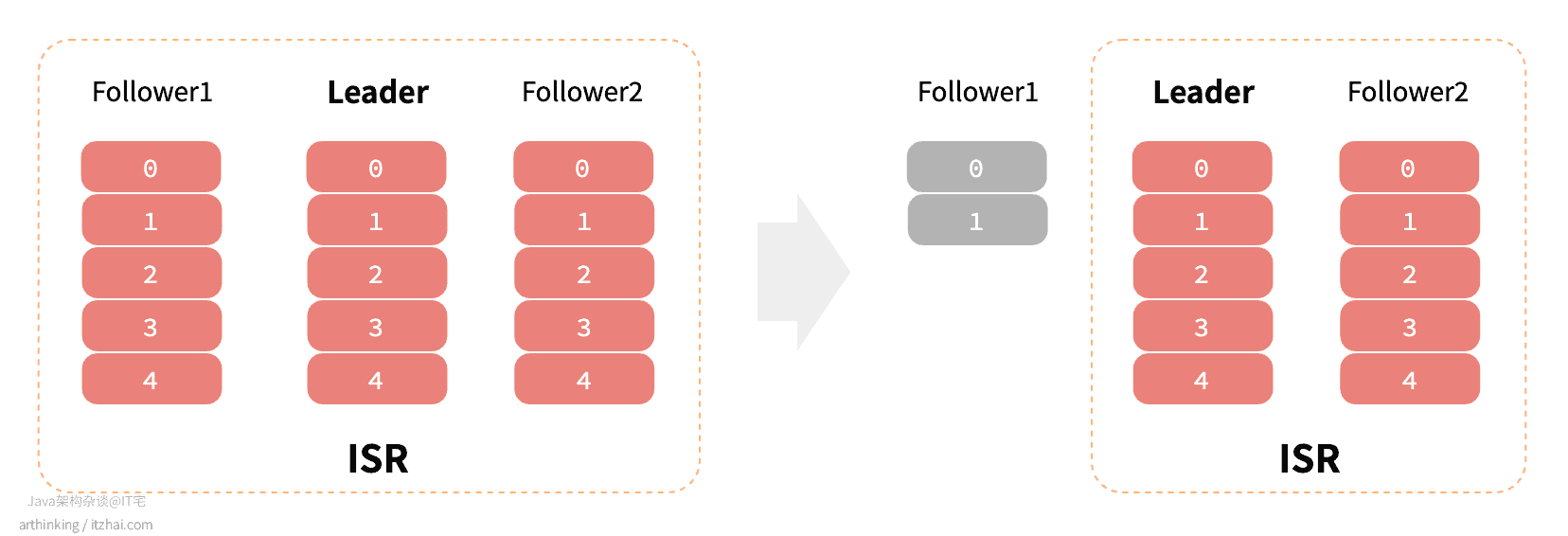
3.2 消费端
对于消费端,为了避免丢失未处理完的消息,需要设置为手动提交。
4 Kafka是如何保证数据的一致性?
保证数据一致性,也就是无论是对于老的Leader,还是新选举出来的Leader,消费者都需要读到一样的数据。
为了支持以上特性,Kakfa引入了HW(High Watermark)高水位的概念。ISR中每个副本最后的那个日志偏移量称为LEO(Log End Offset),HW的取值为ISR集合中最小的LEO,消费者只能消费到HW对应的日志。有点抽象?IT宅来给大家上图,一看就懂:
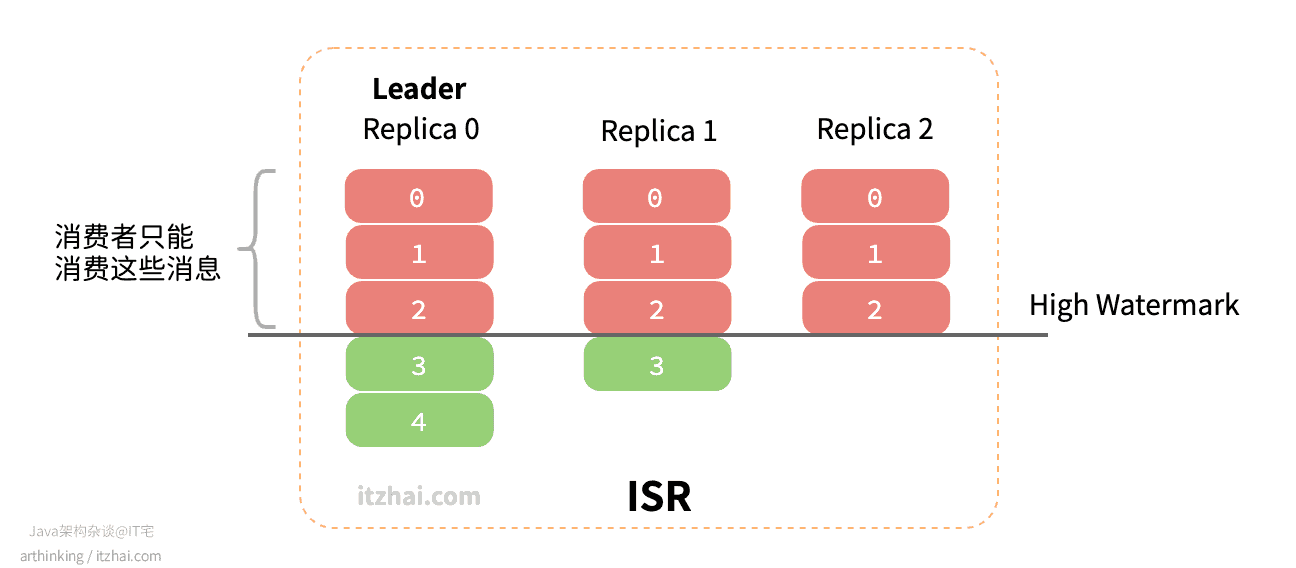
如上图,ISR中有三个副本,Replica 0为Leader,副本0的消息3和消息4都没有完全同步给其他副本,所以HW在消息2处,消费者只能消费到消息2以及之前的消息。
通过引入HW,就避免让消费者消费到还没有完全同步到ISR中所有副本的消息,避免由于切换Leader导致能够读取到的消息变少了,从而导致数据不一致问题。
为了避免部分副本写入速度太慢,导致影响消费者消费消息的及时性,可以配置参数replica.lag.time.max.ms参数,指定副本在复制消息时可被允许的最大延迟时间。如果超过这个时间副本还没有同步好消息,那么副本就会被剔出ISR集合。
HW是用于控制消费行为的,即使acks设置为0,超过HW的消息也是不能被消费者消费端。
讲完了消息的投递,我们接下来讲讲消息的消费。更多图解系列文章,欢迎关注我的博客IT宅(itzhai.com)或者Java架构杂谈公众号。

