

由于我的测试服务器内存比较小,我们先来配置Kafka启动内存,大家根据自己的实际情况进行配置:
1.修改bin目录下的 zookeeper-server-start.sh,将初始堆的大小(-Xms)设置小一些
1 | export KAFKA_HEAP_OPTS="-Xmx256M -Xms128M" |
- 修改
bin目录下的kafka-server-start.sh文件,将初始堆的大小(-Xms)设置小一些
1 | export KAFKA_HEAP_OPTS="-Xmx256M -Xms128M" |
注意:listeners中的IP地址要配置为服务器的IP地址
listeners=PLAINTEXT://192.168.1.101:9093
然后启动三个Kafka实例,部署好之后,可以通过Zookeeper查看集群节点数:

即,目前的集群情况如下:
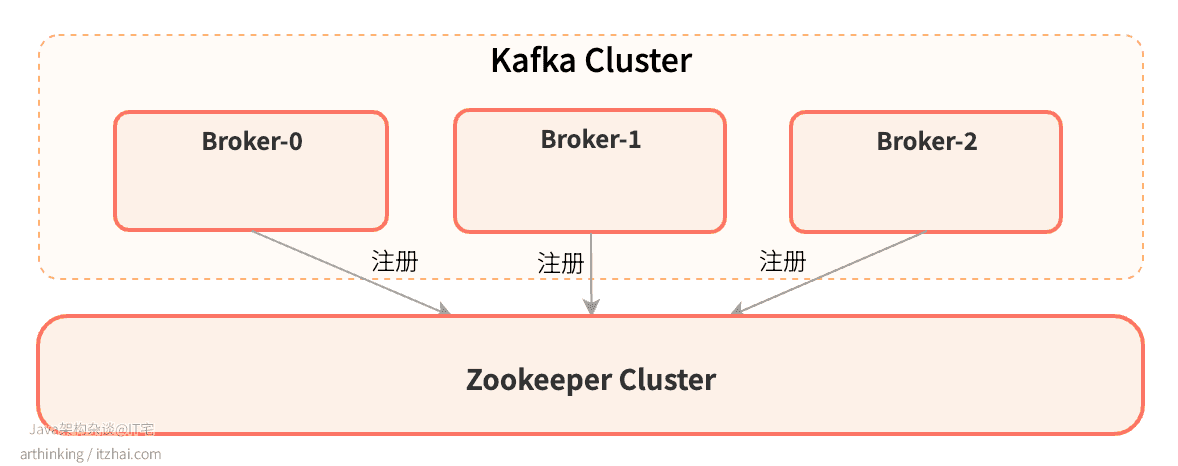
1 创建集群
每个Topic可以配置为多个分区,每个分区可以有多个副本,副本称为Replica,在副本集合中会存在一个Leader副本,Leader负责所有的读写请求,其余副本只负责从Leader同步备份数据。
1.1 ✨创建Topic
接下来新建一个Topic,副本数设置为3,分区数设置为2:

1.2 ✨查看所有Topic

1.3 ✨查看Topic分区详情
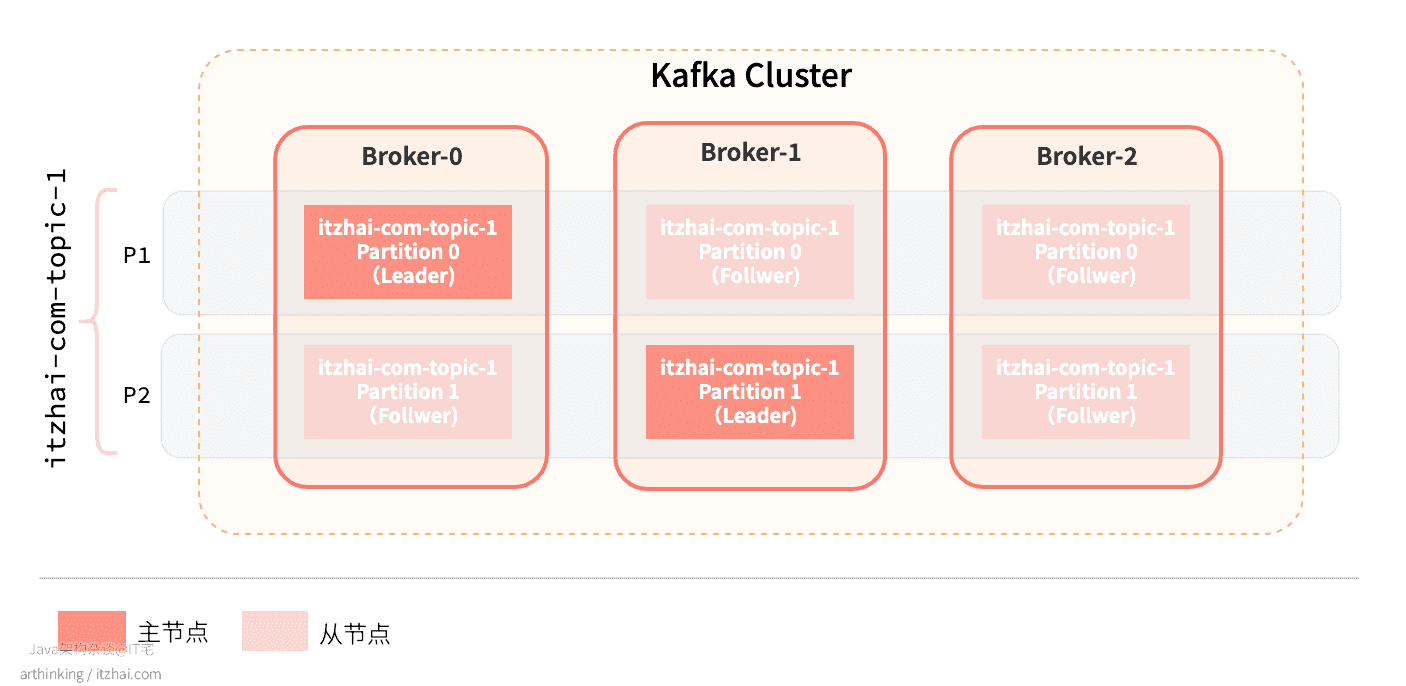
查看刚刚创建的 itzhai-com-topic-1 Topic的信息:

Topic信息属性说明:
- Topic:主题名称
- TopicId:主题id
- PartitionCount:主题分区数量
- ReplicationFactor:副本数量
- Configs:主题详细配置,每一行配置表示一个分区信息
- Topic:主题名称
- Partition:分区号
- Leader:分区的Leader副本,负责当前分区的所有读写请求
- Replicas:存放分区备份的节点
- Isr(In-Sync Replica):这个集合是Replicas的一个子集,列出当前还存活着,并且已经同步备份了该分区的节点
此时,服务器状态如下图所示:
1.3.1 ISR是干嘛的?
Isr(In-Sync Replica):是Replicas的一个子集,列出当前还存活着,并且已经同步备份了该分区的节点。
Isr中包括Leader副本,以及与Leader副本保持同步的Follower副本。
2 重新选主
副本会均匀分配到多个Broker节点上,当Leader节点挂了之后,会从副本集中选出一个新的副本作为Leader继续对外提供服务。
下面我们来测试一下,我们把Broker-1给停掉(找到servier.properties中broker.id=1的进程):
1 | ps aux | grep server-1.properties |
再次查看Topic状态:

发现Partition 1的Leader已经从Broker-1切换到了Broker-2,Broker-1已经从Isr副本集合中移除了。服务器状态如下所示:
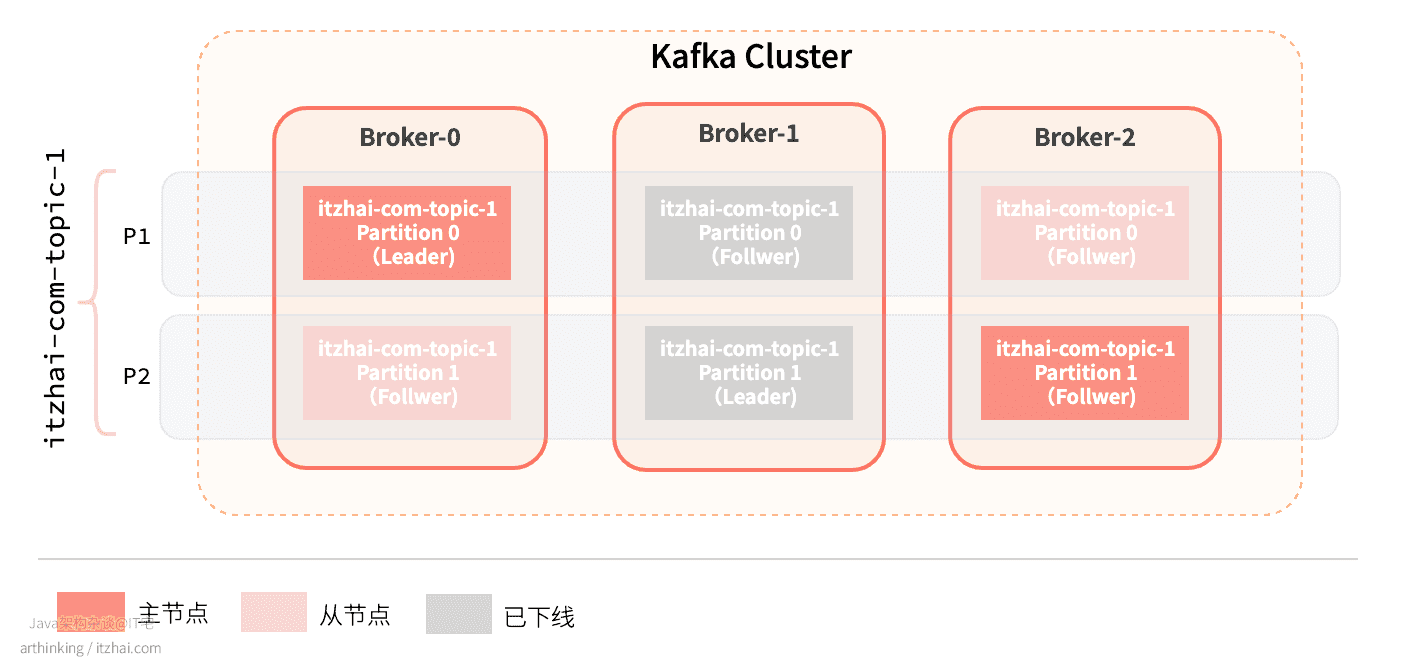
3 总控制器
3.1 总控制器是干嘛的?
我们再来看一下Kafka的集群架构图:
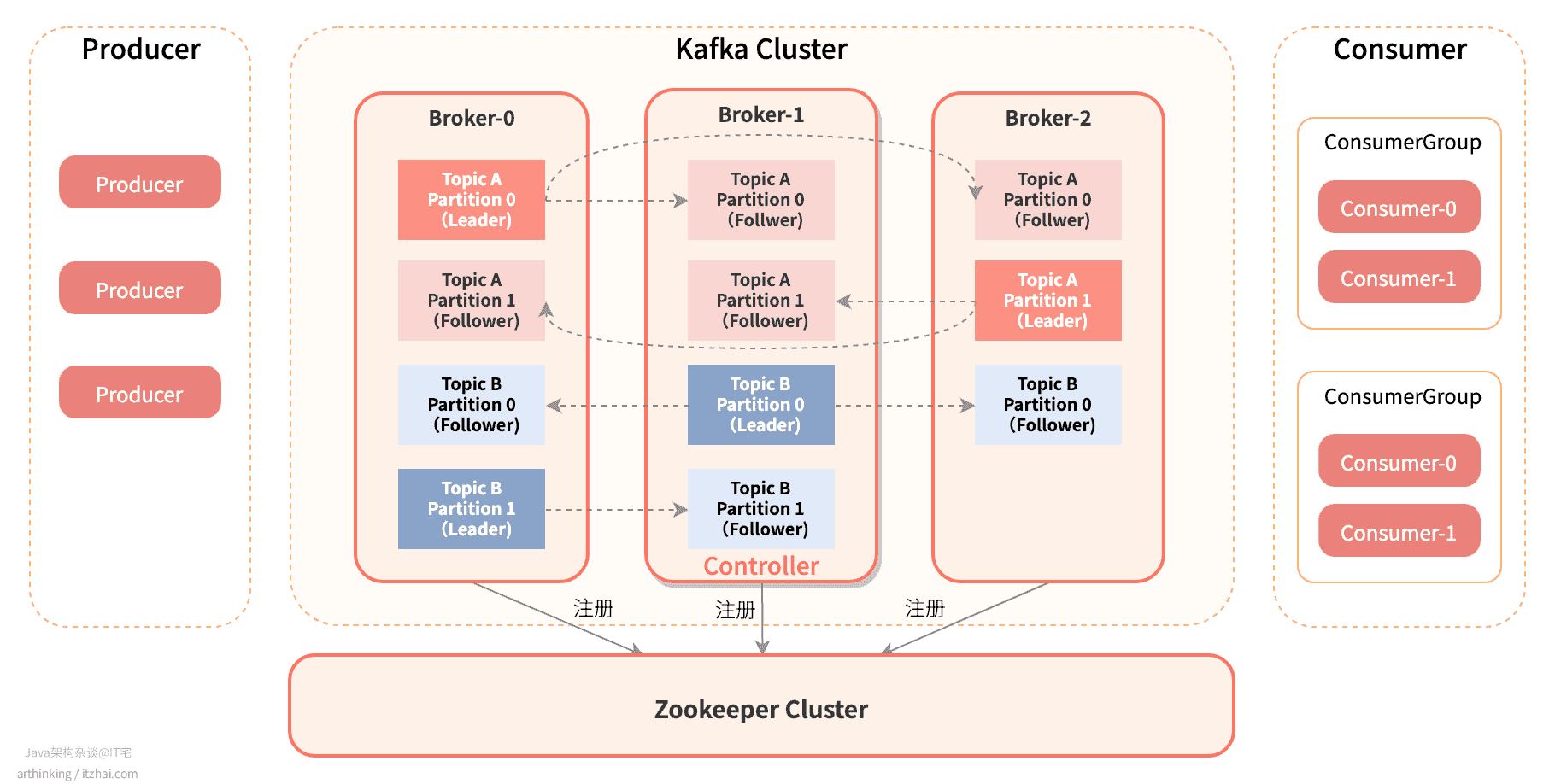
在Broker集群中,会选举出一个Controller总控制器。总控制器主要负责:
-
监听集群信息变更:
- 监听集群变更:为
Zookeeper的/brokers/ids节点添加BrokerChangeListener,用于处理Broker节点增减变更;
- 监听集群变更:为
-
监听Topic变更:
-
为
Zookeeper的/brokers/topics节点添加TopicChangeListener,用于处理Topic增减变更; -
为
Zookeeper的/admin/delete_topics节点添加TopicDeletionListener,用于处理删除Topic的事件; -
为
Zookeeper的/brokers/topics/[topic]节点添加PartitionModificationsListener,用于监听Topic分区分配变更;
-
-
选举Partition分区Leader:分区的Leader副本宕机之后,Controller负责为该分区选举一个新的Leader副本;
-
更新集群元数据信息:感知到分区的ISR集合有变更之后,Controller通知所有的Broker更新其元数据信息。
Zookeeper中存储了Kafka集群信息,可以从Zookeeper中查看到当前总控制器是哪个Broker:

可以发现,id为0的Broker是当前的总控制器。
3.2 总控制器是如何选出来的?
**首次选举Controller:**集群启动的时候,每个Broker节点都会尝在Zookeeper中创建临时节点/controller,最终只会有一个节点能够创建成功,这个节点就会作为Controller总控制器。
**重新选举Controller:**当Controller所在的Broker发生故障之后,Zookeeper中的/controller临时节点会被删除,/broker/ids中对应的Broker节点信息业会被删除。其他Broker节点监听这两个Zookeeper节点,当监听到/controller临时节点消失了,就会尝试往Zookeeper创建该节点,写成功的那个Broker将会成为新的Controller。
3.3 Topic的最优Leader副本是如何选举出来的?
一般的,在分布式系统中,Leader的选举算法很多,如Zab、Raft、Viewstamped Replication等。Kafka使用的Leader选举算法更像是微软的PacificA算法。
Controller负责为Topic选取Leader副本:Controller从ISR列表中选择第一个分区作为Leader,因为ISR第一个分区可能是同步数据最多的副本,可以尽可能保证数据不丢失。
**重新选举Leader副本:**当Controller监听到/brokers/ids中的Broker节点消失的时候,会重新执行Leader选举流程。
相关参数:
unclean.leader.election.enable:true表示当ISR列表所有副本都挂了之后,可以在ISR以外的副本选取Leader副本。从而可以提高可用性,但是可能会导致丢失更多的数据;false表示只能从ISR中选择Leader副本。
3.3.1 Kafka的Topic Leader选举机制有啥优势?
与一般的少数服从多数选举算法不同,Kafka通过使用ISR来实现选举的,ISR的数量不需要超过副本数量的一半,从而使得在可靠性和吞吐量上面取得平衡,一般我们设置为一个大于1的值。
4 Rebalance机制
Rebalance机制是Kafka消费机制的核心。
当消费组消费者数量发生变化、或者消费组消费主题数量变化、主题分区数量变化等的时候,Kafka会重新分配消费者和分区的关系,也就是做一次Rebalance。
**Kafka保证一个Topic分区只会配给一个组内的消费者,**而一个消费者可以消费多个分区。
关于Rebalance的具体原理,找到了一篇讲的比较好的文章,可以参考:Apache Kafka Rebalance Protocol, or the magic behind your streams applications[1]
4.1 什么时候会触发Rebalance机制?
当发生以下情况时,会触发Rebalance机制:
- 消费者的数量发生变化:
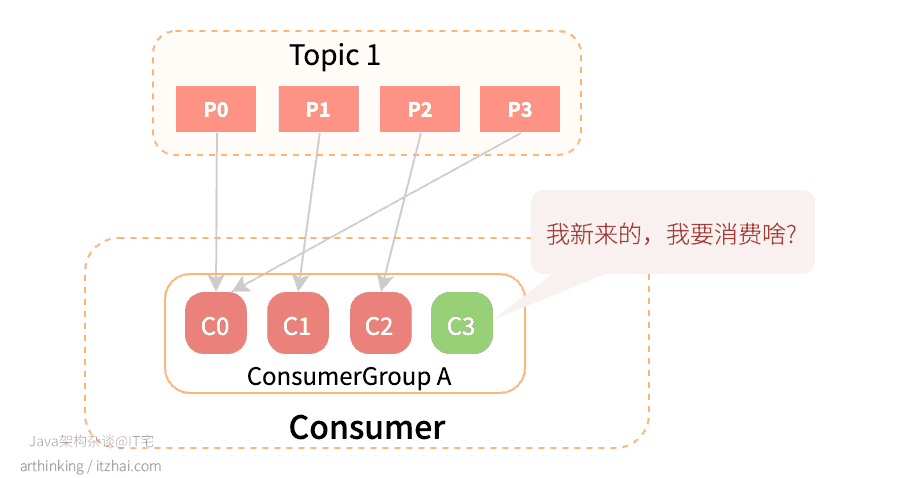
- 主题分区的数量发生变化:
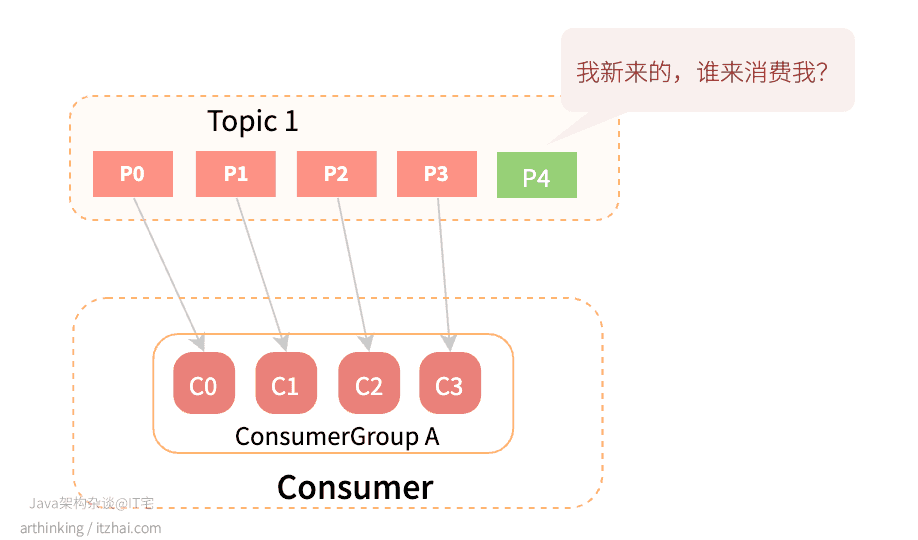
- 消费组订阅的Topic数量发生了变化:
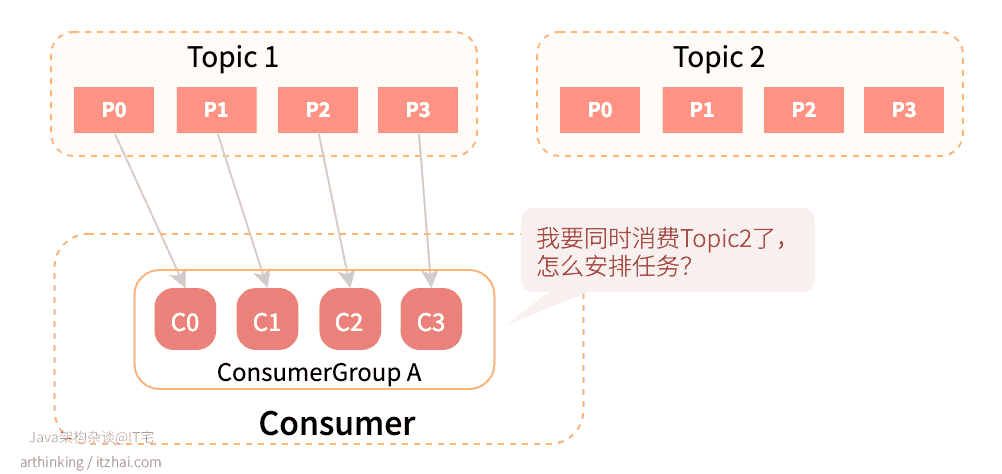
4.2 Kafka中有哪些Rebalance的策略?
Rebalance策略主要有三种:Range、RoundRobin、StickyAssignor(粘性分配器)。在声明消费者的时候可以指定:
1 | props.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, StickyAssignor.class.getName()); |
属于同一组的所有消费者必须声明一个共同的策略。如果消费者尝试加入分配配置与其他组成员不一致的组,会引发如下异常:
1 | org.apache.kafka.common.errors.InconsistentGroupProtocolException: The group member’s supported protocols are incompatible with those of existing members or first group member tried to join with empty protocol type or empty protocol list. |
4.2.1 RangeAssignor[2]
范围分配器,这是默认的策略。
范围分配器是在每个主题基础上工作的,对于每个主题,按照数字顺序排列可用分区,使用组协调器分配的member_id按字典顺序排列消费者。然后将分区数除于消费者总数,以确定分配给每个消费者的分区数,如果没有均匀划分,那么前几个消费者将有一个额外的分区。
如下例子:
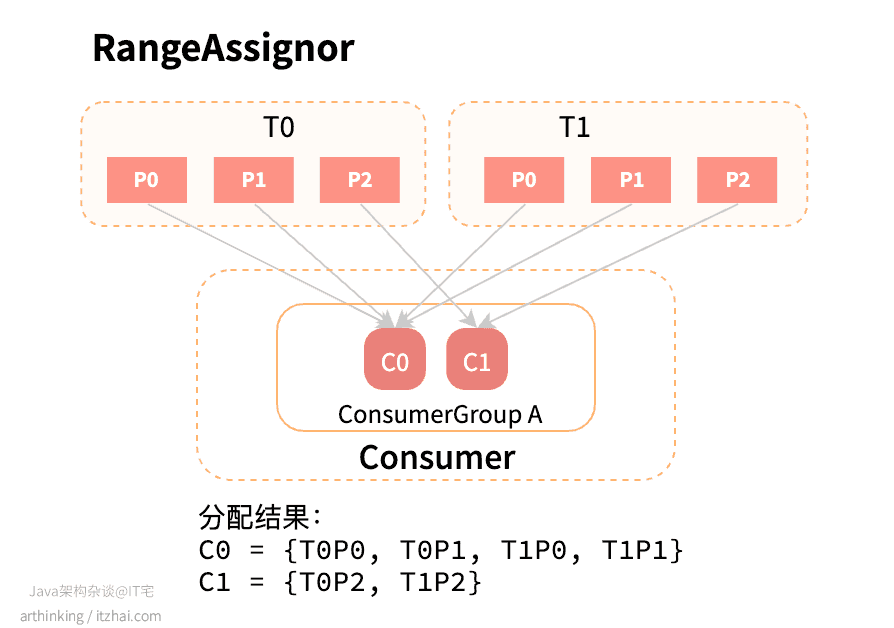
假设有两个消费者C0和C1,两个主题T0和T1,每个主题有3个分区,使用范围分配器最终分配结果:
- C0 = {T0P0, T0P1, T1P0, T1P1}
- C1 = {T0P2, T1P2}
RangeAssignor有何缺点?
我们假设消费组中的消费者数量多于主题的分区数量,则会出现以下情况:
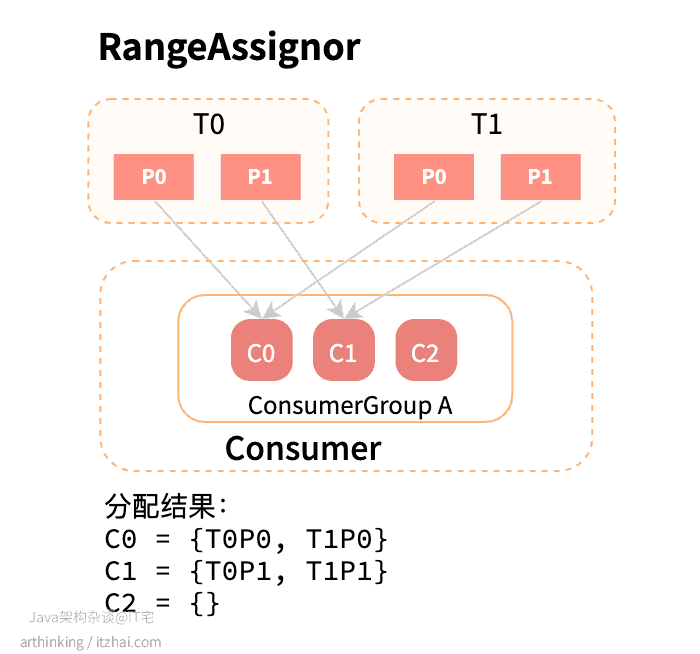
可以发现C3消费者并没有在消费任何分区的消息,并没有尽可能地使用到所有的消费者。
4.2.2 RoundRobinAssignor[3]
循环分配器,让消费组中的所有消费者平均分配可用分区。同样的,首先按照顺序排列可用分区和消费者。循环分配器把所有主题的所有可用分区轮训地分配给订阅它们的消费者。
假设所有消费者实例订阅的主题都相同,则分区将均匀分布:
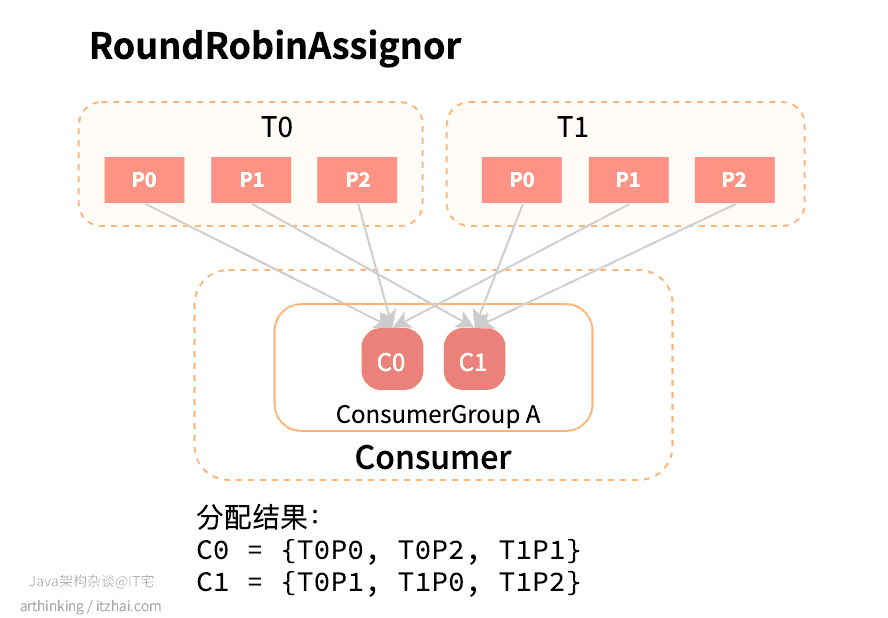
T0和T1的分区:T0P0, T0P1, T0P2, T1P0, T1P1, T1P2将以此轮训的分配给C0和C1。
可以发现,RoundRobin尽可能地使用到了所有的消费者,把分区更均匀的分配给消费者。
上一节的例子使用RoundRobin策略,结果如下图所示:
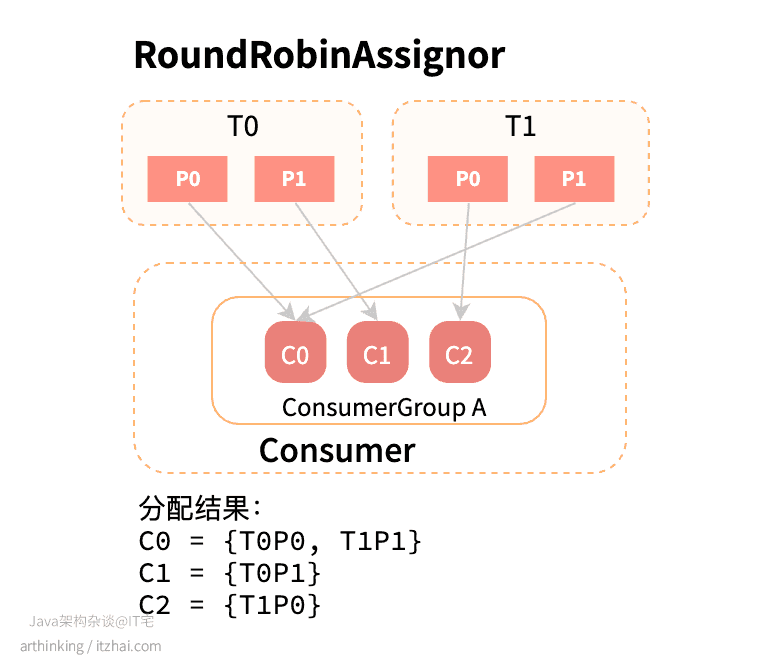
可以发现C2也被利用起来了。
RoundRobin有何缺点?
虽然RoundRobin尽可能的利用所有的消费者,但是一旦消费者数量发生变化触发Rebalance时,会导致更多的分区重分配。
4.2.3 StickyAssignor[4]
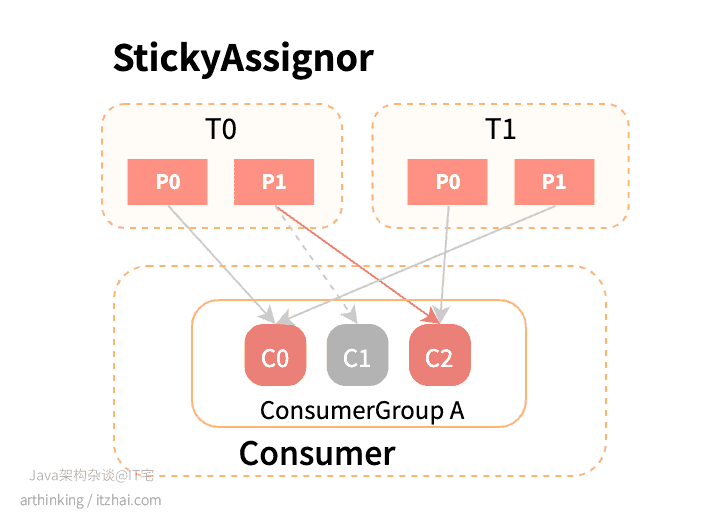
粘性分配策略,与RoundRobin类似,但是在Rebalance时,会遵循以下原则:
- 分区尽可能保证分布均匀;
- 分区分配尽可能保持不变更;
优先保证分布均匀。
使用StickyAssignor策略的情况下,假如C1挂了,那么只需要把原本C1的T0P1分区分配给C2即可:
4.3 集群消费Rebalance机制是如何工作的?[1:1]
Kafka的Rebalance流程会经历以下几个阶段:
4.3.1 选择组协调器阶段
Kafka会为每个消费组选择一个Broker来作为组协调器,组协调器负责监控消费组里所有消费者的心跳,判断机器是否下线,以及开启消费者Rebalance。
消费组中的每个消费者在启动的时候都会向Kafka集群中的某个节点发送FindCoordinator请求来查找对应的组协调器GroupCoordinator,并与之建立网络连接。
如何选择组协调器?
Kafka会选择消费分组正在使用的consumer_offsets分区对应的Broker作为ConsumerGroup的Coordinator。
消费分组写消息的consumer_offsets分区号:
hash(ConsumerGroupId) % __consumer_offsets 主题的分区数。
4.3.2 消费者加入消费组阶段
成功找到消费组对应的GroupCoordinator之后,就进入加入消费组阶段。
此时消费者向GroupCoordinator发送JoinGroup请求,申请加入消费组,此时会启动Rebalance协议。
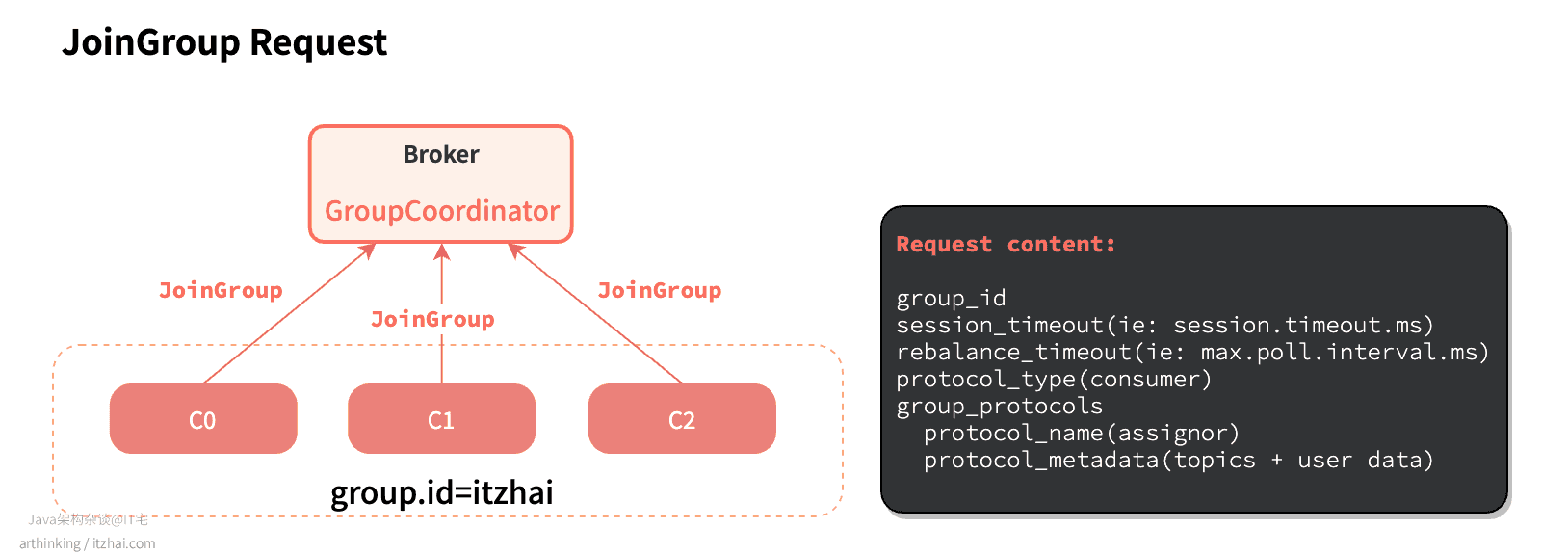
Join Group 包含了一些消费者客户端配置信息,如session.timeout.ms和max.poll.interval.ms等,组协调器使用这些属性进行消费者下线状态判断。另外,请求中包含了成员支持的客户端协议列表,以及用于执行客户端协议的元数据。
GroupCoordinator会从Consumer Group中选择第一个加入消费组的消费者作为组长(Leader),并把消费组的情况发送给这个组长,组长负责在本地制定分区方案。
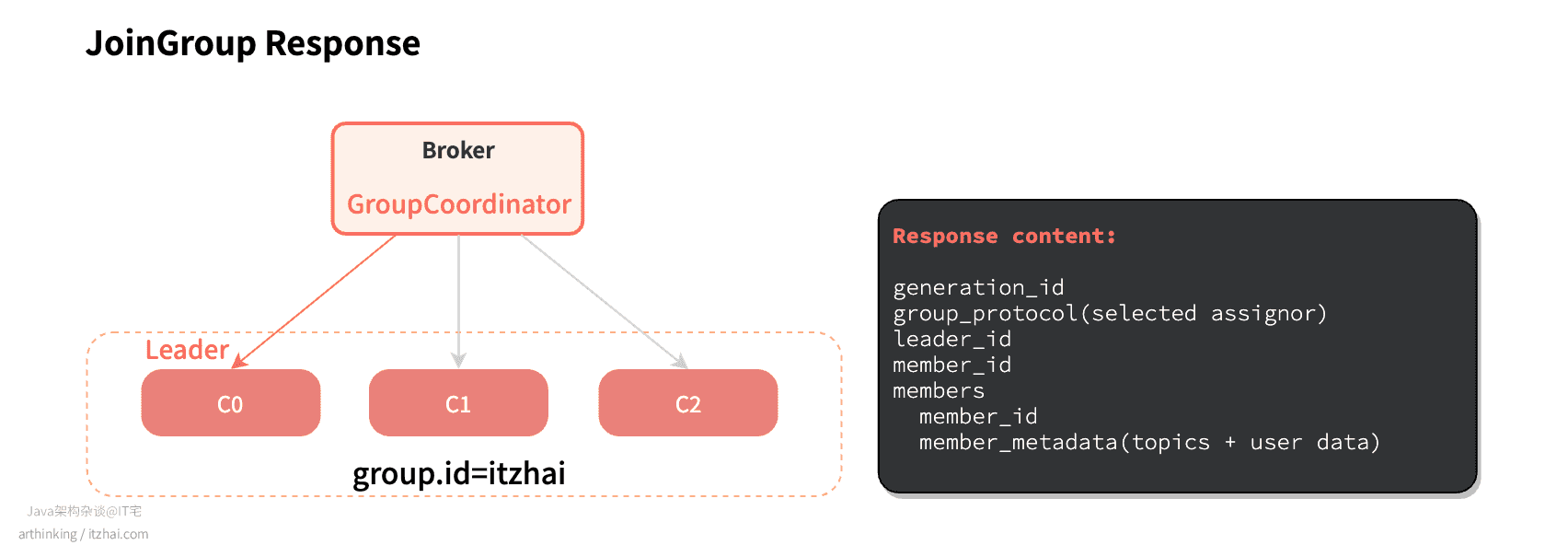
4.3.3 同步与执行分区方案阶段
消费组的组长制定好分区方案后,给GroupCoordinator发送SyncGroup请求,并附加上制定好的分区作业,非组长则简单的发送一个空请求。:
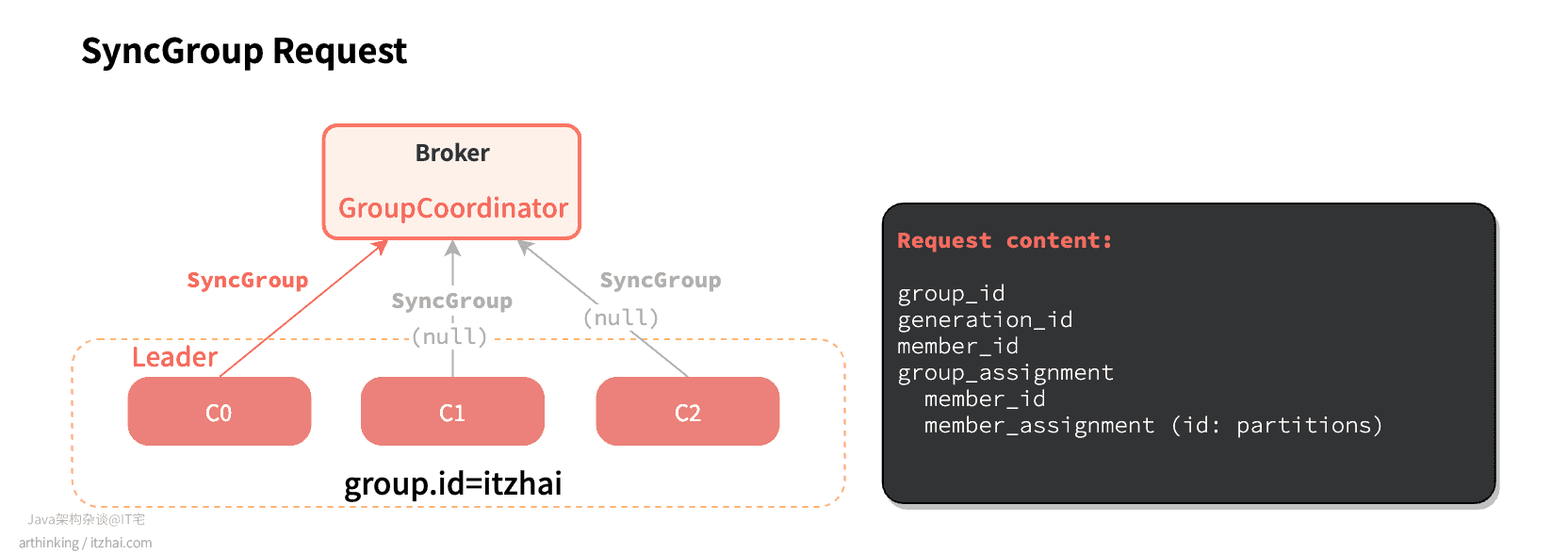
然后GroupCoordinator把分区方案响应给组里的所有消费者。最终消费者连接指定的分区,并进行消息消费:
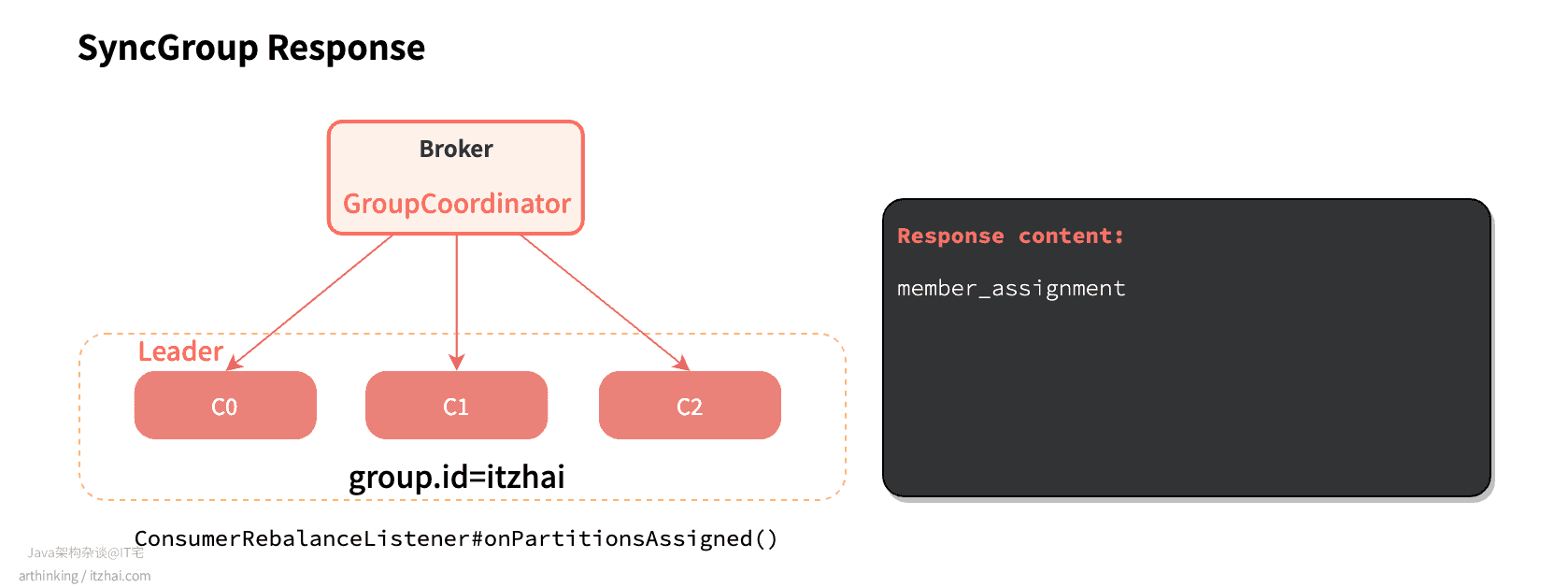
每个消费者定期向组协调器发送心跳请求,以保持会话状态(相关配置:heartbeat.interval.ms)。如果此时正在进行Rebalance操作,组协调器会响应告知消费者需要重新加入组。
当集群节点比较多的时候,Rebalance可能会花费比较多的时间,导致消耗Broker服务器的资源,影响消费性能,为此,尽量选择在系统负载比较低的时候进行Rebalance。
注意:通过assign指定消费分区的情况下,Kafka不会进行Rebalance:
References
Apache Kafka Rebalance Protocol, or the magic behind your streams applications. Retrieved from https://medium.com/streamthoughts/apache-kafka-rebalance-protocol-or-the-magic-behind-your-streams-applications-e94baf68e4f2 ↩︎ ↩︎
Class RangeAssignor. Retrieved from https://kafka.apache.org/23/javadoc/org/apache/kafka/clients/consumer/RangeAssignor.html ↩︎
Class RoundRobinAssignor. Retrieved from https://kafka.apache.org/23/javadoc/org/apache/kafka/clients/consumer/RoundRobinAssignor.html ↩︎
Class StickyAssignor. Retrieved from https://kafka.apache.org/23/javadoc/org/apache/kafka/clients/consumer/StickyAssignor.html ↩︎

