

1 集群消费与广播消费
1.1 Kafka中的集群消费(单播消费)
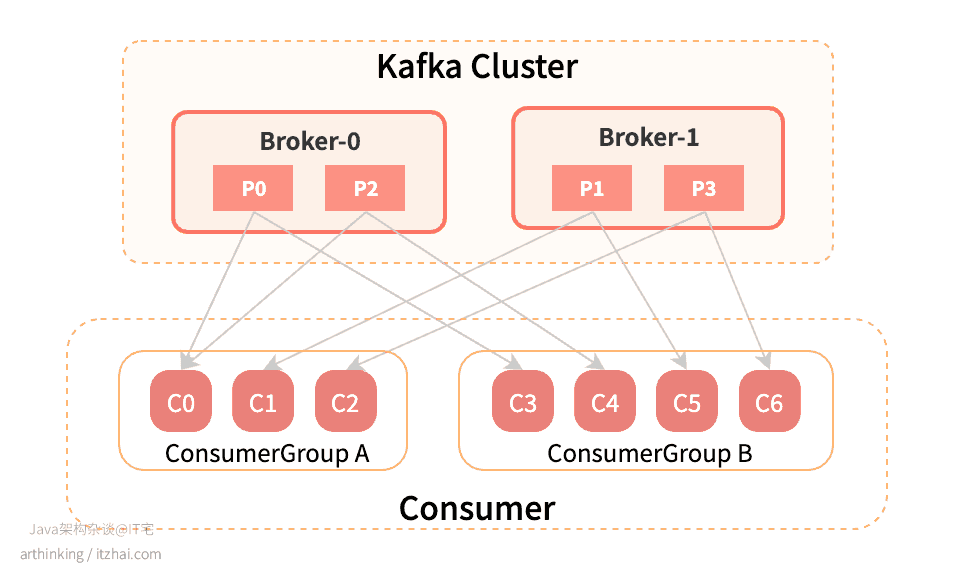
如上图,每个ConsumerGroup里面的消费者是一个集群,同一个ConsumerGroup的消费者共同消费Topic的消息,同一个Topic的一条消息只能被同一个ConsumerGroup的某一个Consumer消费,不能被重复消费,如果C0消费了一条消息,那么C1和C2就不会再消费这条消息了。要实现集群消费,只要把所有Consumer放到同一个ConsumerGroup中就可以了。
✨ 集群消费例子

我们启动了一个消费者,通过group.id参数指定消费分组arthinking来消费消息了,从而达到了集群消费的效果。
1.2 Kafka中的广播消费
**同一个Topic的一条消息可以被多个ConsumerGoup重复消费。**如果要实现广播消费,只需要把Consumer放到不同的ConsumerGroup中就可以了。
✨ 广播消费例子
为了实现广播消费效果,我们继续启用新的消费组消费即可:

2 Kafka的消费进度如何维度
2.1 消费进度相关命令
我们现在来看一下消费组的消费进度:
✨ 查看消费组消费进度

可以发现,在arthinking消费分组中,P0和P1分区都正在被同一个消费者消费,这里可以看到详细的消费进度。
我们列出所有的Topic,发现有一个消费主题__consumer_offsets,这个主题是用来维护消费进度的。
✨列出所有Topic

我们看看__consumer_offsets这个Topic的详情:
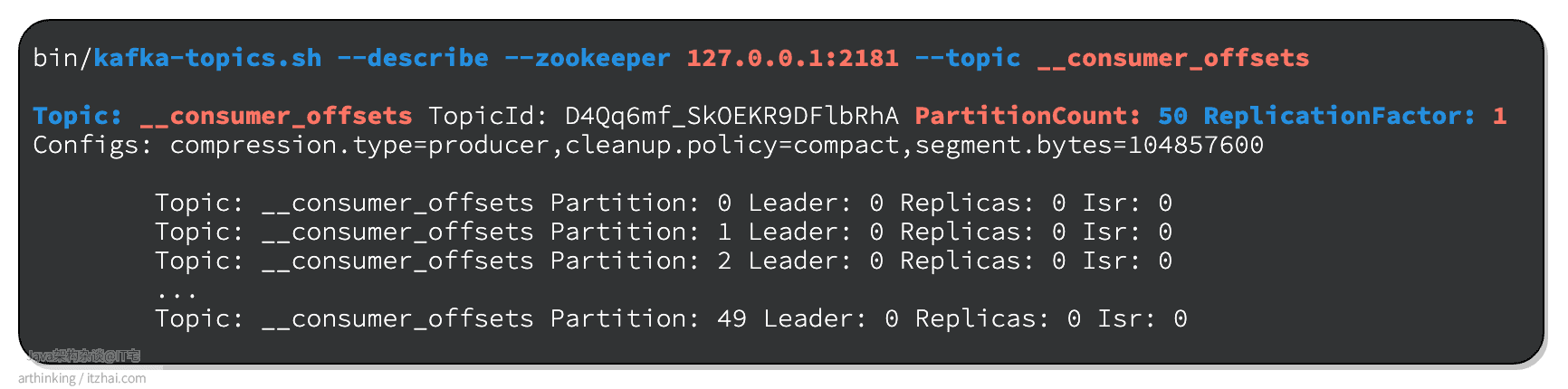
可以发现,这个Topic有50个Partition,副本数为1。topic配置的清理策略是compact,即总是保留最新的key。
2.2 __consumer_offsets
__consumer_offsets这个Topic就是用于维护消费组的消费进度的。__consumer_offsets中保存的也是普通的Kafka消息,主要保留三类消息消息:
- Consumer group组元数据消息,如groupId,组成员状态,成员配置信息等;这类消息在Group Rebalance的时候写入;
- Consumer group位移消息,存储消费组的消费进度;这类消息在提交消费进度的时候写入;
- Tombstone消息或Delete mark消息。每当Consumer Group下已经没有任何激活的成员并且所有位移数据都被删除时,Kafka就会将该Group状态设置为Dead,并发送一条tombstone消息,表明要彻底删除这个Group的信息。这类消息在Kafka后台线程扫描并删除过期位移或者
__consumer_offsets分区副本重分配的时候写入。
这里我们主要关注的就是Consumer group的位移消息。该消息的key的格式是:groupId + topic + partition分区号,即,每个topic的每个分区,针对不同的消费分组,都会存储一个消费进度。value是消费偏移量offset。
__consumer_offset Topic相关配置参数:
- offsets.topic.num.partitions:分区数量,默认为50;
- offsets.topic.replication.factor:副本因子,默认为1。
推荐副本因子设置成>1,以提供数据存储的可靠性。
3 消费者是如何提交offset的?
3.1 自动提交 enable.auto.commit
通过enable.auto.commit参数,可以控制是否自动提交offset,默认为true。
如果设置为false,则消费完成之后,记得手动提交ack,否则,每次重启消费者之后,会继续从未提交的位置继续重复消费消息。
auto.commit.interval.ms配置自动提交的时间间隔。
自动提交会有什么问题?
假设设置的自动提交时间间隔为1秒,取出一批数据之后,需要5秒才能消费完,但是还没消费完,程序就挂了。导致这批未被消费部分的数据再也没有机会被消费到了,即消息错过消费。
假设取出的一批数据为10条,假设成功处理了两条消息,还没有触发自动提交offset,消费程序就挂了,下次重启消费程序之后,会导致这两条消息再次被消费到,即消息重复消费。
3.2 同步提交&异步提交
如果设置为手动提交,需要调用提交的API。在kafka-clients的API中,kafka为我们提供了同步提交和异步提交的API。
同步提交:
1 | consumer.commitSync(); |
异步提交:
1 | consumer.commitAsync(new OffsetCommitCallback() { |
4 有哪些消费历史消息的方法?
4.1 指定分区消费
指定消费0分区:
1 | String TOPIC_NAME = "itzhai-com-test1"; |
4.2 消息回溯消费
指定0分区,从头消费:
1 | String TOPIC_NAME = "itzhai-com-test1"; |
4.3 指定offset消费
1 | String TOPIC_NAME = "itzhai-com-test1"; |
4.4 指定时间点消费
从指定时间点往后找到第一条消息的偏移量,开始消费。 最终都是调用指定offset进行消费。
相关例子:
1 | // 消费8小时前的消息 |
4.4.1 基于时间点消费底层是如何实现的?
由上面的例子可以发现,基于时间的消费,也是先找到对应时间的消息offset,最终都是基于offset去消费的。
5 消费者相关参数
5.1 消费提交: enable.auto.commit
参考 5.3.1 自动提交 enable.auto.commit
5.2 最大拉取消息数: max.poll.interval.ms
每次poll拉取的最大消息数,根据消费处理速度进行配置。如果消费者消费速度很快,则可以设置的大点。
5.3 消费者在线判断: heartbeat.interval.ms 和 session.timeout.ms
heartbeat.interval.ms参数配置消费者给Broker发送心跳的间隔时间。当Broker进行Rebalance的时候,接收到了消费者的心跳,将把Rebalance方案响应给Consumer。
session.timeout.msBroker等待消费者发送心跳的最大时间,如果超过了这个时间,消费者就会被判断为出问题,会被踢出消费组,导致该消费者占用的Partition被重新分配给其他消费者。
5.4 最大poll时间间隔: max.poll.interval.ms
如果两次poll时间超过这个间隔,Broker就会认为这个消费者消费太慢了,会把消费者剔除消费组,让出分区,并把分区分配给其他的消费者进行消费。
5.4.1 为什么生产的消费者突然就不消费消息了?
如果消费者每次启动了,消费若干条消息就不再消费消息了,而生产者是有不断生产消息的,就需要确认消费者是否被T掉了,可能是两次poll的时间超过了max.poll.interval.ms配置的值。为了解决这个问题,可以:
- 增加
max.poll.interval.ms配置的时间,建议不要配置的太大,不然就没办法基于这个参数判断消费者的消费能力了,导致没法把分区重分配给消费能力更好的消费者; - 减小
max.poll.interval.ms,即每次poll拉取的消息数降低点,避免消费时间过长; - 检查消费者消费性能是否有瓶颈,根据实际情况进行优化。
5.5 新消费组是否从头消费: auto.offset.reset
auto.offset.reset用于配置新的消费组的消费行为,配置新的消费组是否从头开始消费分区,还是只消费增量的消息,可选配置:
latest:只消费增量的消息,即消费消费组启动后分区接收到的消息,默认为该配置;earliest:从头开始消费分区消息,后续会根据offset记录消费进度,消费增量的消息。

