

1 Kafka为啥性能这么高?
大家知道RocketMQ是基于Kafka改造而来的,因此Kafka的高性能原因与RocketMQ类似,以下是Kafka高性能的原因:
- 磁盘顺序读写:Kafka写消息都是直接追加到文件末尾的,不会有随机写的情况,另外,不会随机删除日志,只会按照删除策略删除一整段的历史消息。
- 与RocketMQ不同的是,kafka不会像RocketMQ那样预分配一个很大的文件来存储消息,Kafka的顺序写可以理解为分段顺序写的,一般一台服务器只部署Kafka就更接近与完全顺序;
- 批量读写数据,以及压缩传输:
- Rocket发送消息底层是分批发送的,提高了传输和存储的效率;
- 数据零拷贝技术:通过mmap内存映射,以及sendfile,减少了数据拷贝次数,提高了数据发送效率。
2 Kafka支持延时队列吗?
很遗憾,Kafka中并没有像RocketMQ中提供的那种延时队列功能,不过可以参考RocketMQ自己实现一个延时队列。RocketMQ不正是基于Kafka演变而来的么。
参考做法:按延时时间分为不同的延时等级,分别创建对应的延时主题:delay_1s, delay_10s, delay_30s…通过定时任务轮训这些主题,根据消息的创建时间,对比判断主题的队列是否到期,如果到期了,就把消息转发给具体的业务处理的topic进行处理,由于排在前面的消息肯定时候最早到期的,所以可以很快的找到所有要处理的消息,处理完毕。
3 Kafka支持事务消息吗?
Kafka中有事务的概念,但是并不支持类似RocketMQ中的分布式事务消息,Kafka中的事务只是用于保证发送多条消息时候,同时成功或者失败。
有时候,我们在做完一次业务处理之后,需要发多条不同的消息给不同的消费方,这个时候要确保消息同时发送成功的话,就可以使用Kafka的事务了[1]:
1 | Properties producerProps = new Properties(); |
4 Kafka如何避免重复消费?
避免重复消费,是任何消息队列中间件都不可避免遇到的问题,我么接下来说下在Kafka中导致重复消费的原因和解决方法。
4.1 生产端
如果生产端配置了重试机制,那么在网络不稳定,或者发送超时的情况下,就会尝试重新发送,这可能会导致Broker接收到重复的消息。
4.2 消费端
当消费端设置为自动提交Offset的时候,可能在消费一批数据过程中,还没来得及提交,服务就挂了,下次重启消费者,就会导致重复消费该批消息。
为了避免重复消费,在消费端,需要做好幂等处理。
5 消息堆积如何处理?
产生消息堆积的原因,不外乎两种:
- 消费端程序有bug,或者数据有问题,导致一直消费失败,消息一直得不到正确处理从而导致消息堆积;
- 消费者的消费性能太差,或者消费消息的时间太长了,导致消息堆积着来不及消费。
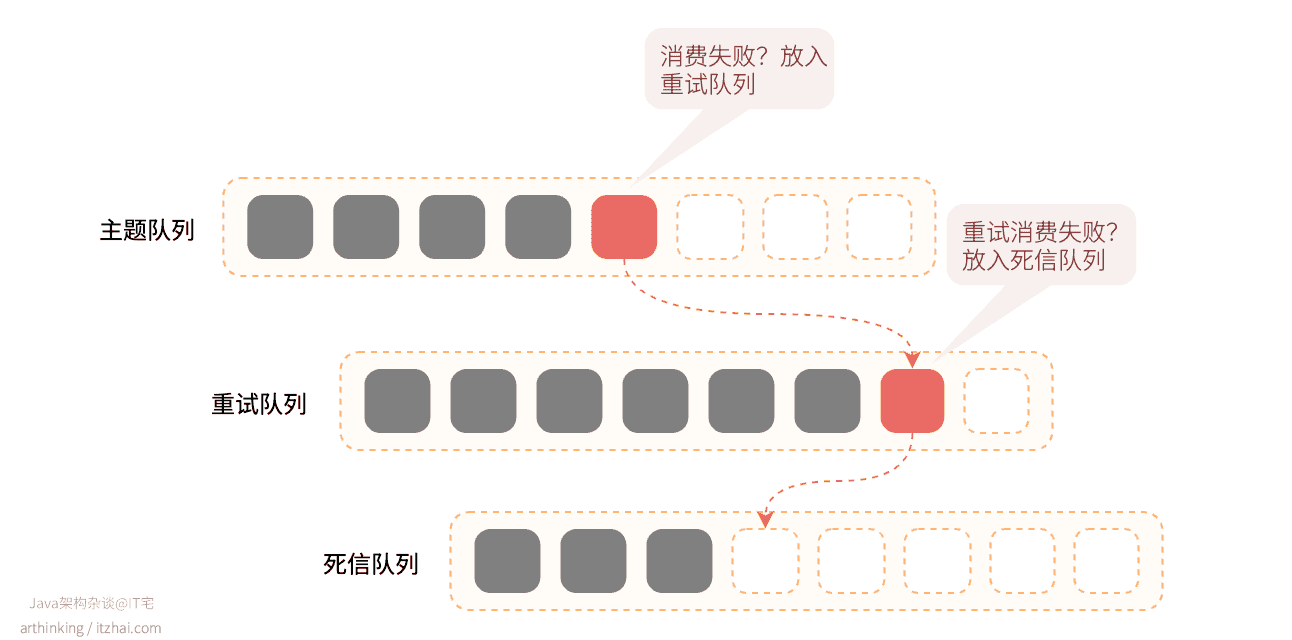
针对第一种情况,为了避免消息队列,可以把这种消息单独放到死信队列中做特殊处理。由于Kafka中并没有提供类似RocketMQ的那种死信队列[2],所以需要专门准备一个这样的主题充当死信队列。进入死信队列的消息需要进行分析并处理掉消费不成功的问题。
更进一步的,也可以参考RocketMQ,先把消费失败的消息放到一个专门负责重试的重试队列中,执行多次重试可以通过创建多个主题来完成,如果重试队列还是消费失败,则把消息放入死信队列。具体做法可以参考此文:Building Reliable Reprocessing and Dead Letter Queues with Apache Kafka. Retrieved from https://eng.uber.com/reliable-reprocessing/[3]
针对第二种情况,由于分区数量是固定的,即使增加消费者,也没办法加快消费速度。为了快速修复问题,可以修改消费者程序,把消息快速转发到另一个新的主题中,并给这个主题设置很多分区,最后启动对应数量的消费者进行消费:
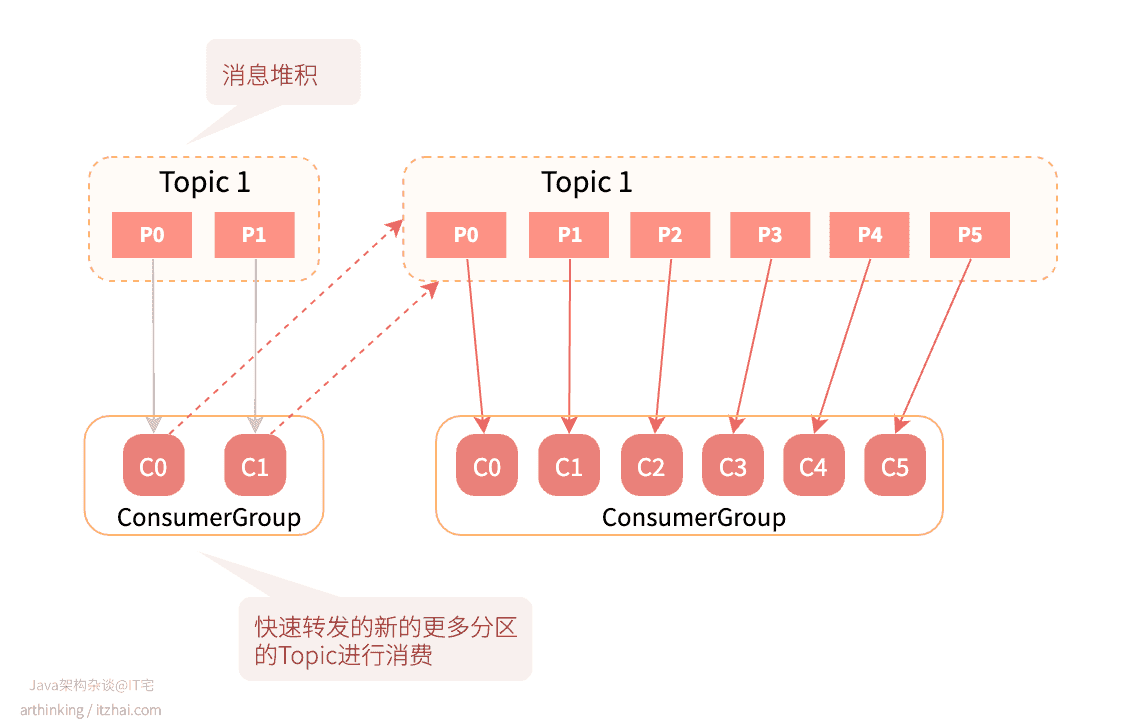
6 消息顺序性如何保证?
为了保证消息消费的顺序性,最简单的做法就是:
- 发送端设置同步发送,避免异步发送导致乱序;
- 消费端消息统一发到同一个分区,通过一个消费者去消费消息。
但是这样会导致消息处理的效率很低,拖慢系统的吞吐量。
为了提高性能,需要考虑其他的思路。RocketMQ中,提供给了MessageQueueSelector接口,可以把具有相同标识(如订单号)的消息统一发到同一个消息队列中,参考IT宅上一篇文章(高并发异步解耦利器:RocketMQ究竟强在哪里?)。我们也可以考虑类似的思路:按照消息的某种标识,把相同标识的消息投递到同一个分区,从而保证同同一个标识的消息在分区中是顺序消费的。
7 消息如何回溯消费?
在某些场景下,如消费程序有问题时,修复了消费程序之后,想要重新消费之前已经消费过的消息,就需要用到回溯消息的功能更了。回溯消息支持指定offset消费,也支持指定时间点消费,参考5.4 有哪些消费历史消息的方法。
8 如何实现消息传递保障?
对于消息中间件,可以提供多种传递保障:
- 最多一次,消息可能会丢失,但绝对不会重发;
- 至少一次,消息不会丢失,但有可能会导致重发;
- 正好一次,每个消息传递一次且仅一次。
在Kafka可以通过acks参数值控制传递保障行为:
- 最多一次:acks=0
- 至少一次:acks=all 或者 -1
- 正好一次:acks=all 或者 -1,消费端加上消费幂等性保证。当然,也可以使用Kafka的幂等性投递来实现。
Kafka中的幂等性投递消息是如何实现的?
相关参数:enable.idempotence
当设置为“true”时,生产者将确保只会投递一条消息到Broker中。如果为“false”,则生产者则可能会由于网络等问题导致重试投递,导致重复消息。请注意,启用幂等性要求
max.in.flight.requests.per.connection小于或等于 5(保留任何允许值的消息排序),retries大于 0,并且acks必须为“all”。**实现原理:**Kafka每次发送消息的时候,会给消息生成PID和Sequence Number,一并发送给Broker,Broker根据PID和Sequence Number判断生产者发送过来的消息是否相同,只有不相同的才会接收并存储起来。
我精心整理了一份Redis宝典给大家,涵盖了Redis的方方面面,面试官懂的里面有,面试官不懂的里面也有,有了它,不怕面试官连环问,就怕面试官一上来就问你Redis的Redo Log是干啥的?毕竟这种问题我也不会。

在Java架构杂谈公众号发送Redis关键字获取pdf文件:
References
Exactly Once Processing in Kafka with Java. Retrieved from https://www.baeldung.com/kafka-exactly-once ↩︎
Kafka Connect 101: Error Handling and Dead Letter Queues. Retrieved from https://www.youtube.com/watch?v=KJUlnmEjbTY ↩︎
Building Reliable Reprocessing and Dead Letter Queues with Apache Kafka. Retrieved from https://eng.uber.com/reliable-reprocessing/ ↩︎

