

在介绍RocketMQ的时候,高并发异步解耦利器:RocketMQ究竟强在哪里?这篇文章中,我们介绍了RocketMQ的存储架构,由于RocketMQ是基于Kafka改造而来的,所以Rocket与Kafa的存储架构很相似。这里对比下:
- RocketMQ是把Topic分片存储到各个Broker节点中,然后在把Broker节点中的Topic继续分片为若干等分的ConsumeQueue,从而提高消息的吞吐量。ConsumeQueue是作为负载均衡资源分配的基本单元;
- 类似的,Kafka的Topic以Partition为单位,分片存储到各个Broker节点中,一个Broker节点可以存储多个Partition,Partition是作为Kafka负载均衡资源分配的基本单元。
还没有深入了解RocketMQ的朋友,可以看看高并发异步解耦利器:RocketMQ究竟强在哪里?这篇文章,更多技术文章,欢迎关注我的博客IT宅(itzhai.com)或者Java架构杂谈公众号。
1 Kafka分区文件存储方式
Kafka的Partition类似于RocketMQ的ConsumeQueue。随便查看某一个Topic Partition下的文件:

我们重点看看index, log, timeindex这三个文件。
log文件有点像RocketMQ的commitlog文件,但是Kafka是以分区为维度进行存储的,RocketMQ存储的则是整个Broker的所有消息。
每个Partition分区下面是由多个Segment(段)组成的,Segment是逻辑概念,实际上会对应到上面的三个文件:
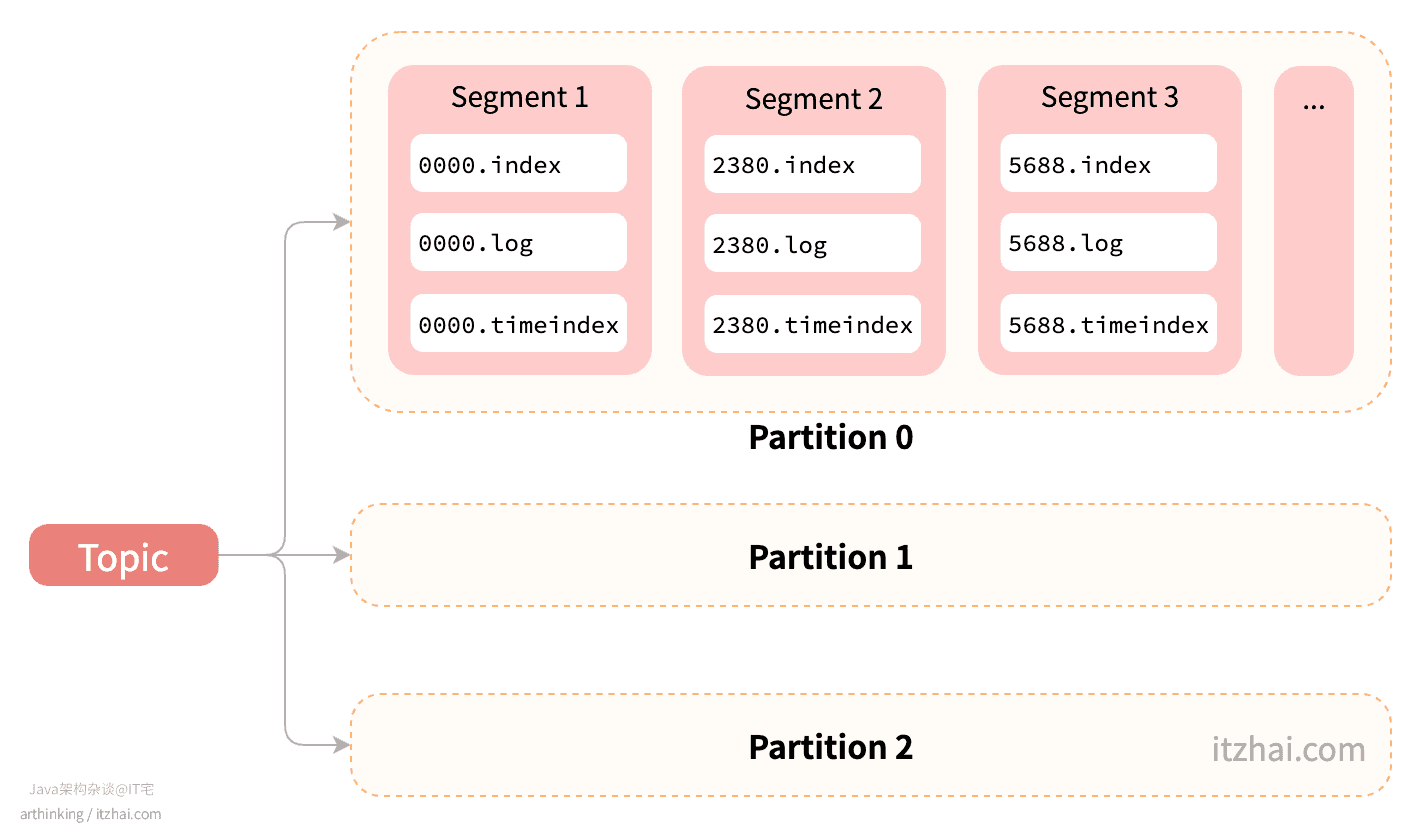
log:数据文件,存储实际的消息数据;index:索引文件,存储消息数据的索引;timeindex:索引文件,提供时间维度的检索。
Segment文件的命名规则:Partition的第一个Segment文件从0开始,后续每生成一个新的Segment文件的时候,文件名以当前Partition的最大offset为基准,文件名长度为64位long类型。
Segment生成相关配置:
log.segment.bytes: 每个segment的大小,达到这个大小后会创建一个新的segment,默认是1G;log.segment.ms: 配置每隔多少毫秒产生一个新的segment,默认是7天。
2 log数据文件
log文件存储实际的消息数据,可以通过参数log.segment.bytes指定一个log文件大小,log文件的消息是顺序写的。
3 index索引文件
index:是一个稀疏索引,默认的,Kafka每接收4k(可通过log.index.interval.bytes参数配置)就记录当前一条消息的offset和消息在log日志中的实际位置到index索引文件。也就是说,Kafka是采用稀疏索引来实现信息检索的,如下图,Kafka会把offset为3,7,10的消息的offset以及在log文件中的实际位置存入index文件中:

我们可以通过以下命令查看index文件的内容:
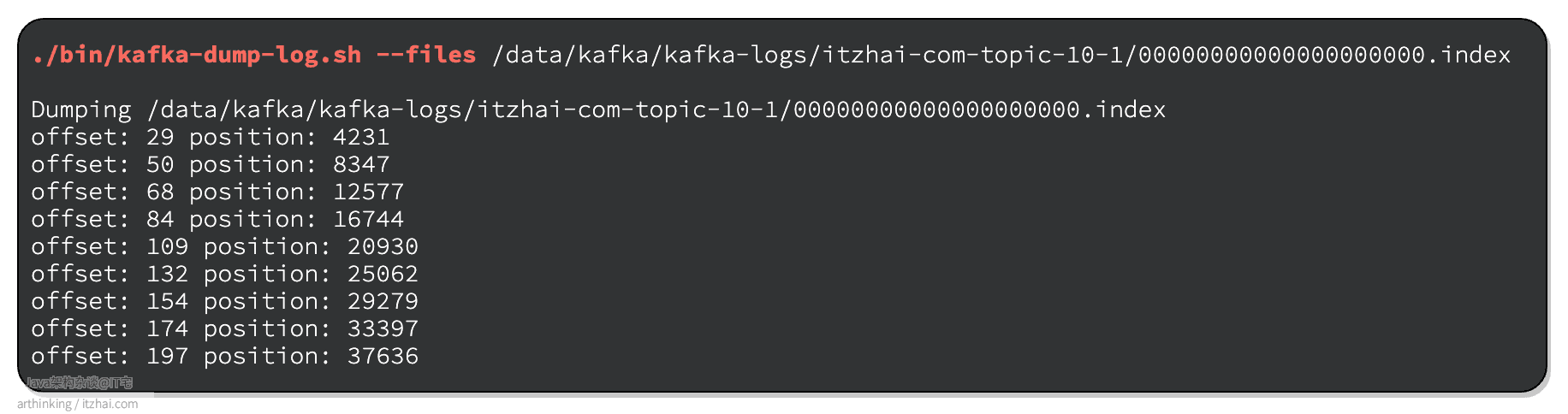
log.index.interval.bytes:索引条目区间密度,默认4k,每接收4k就记录当前一条消息的offset。增加索引条目的区间密度会影响索引文件的区间密度和查询效率。
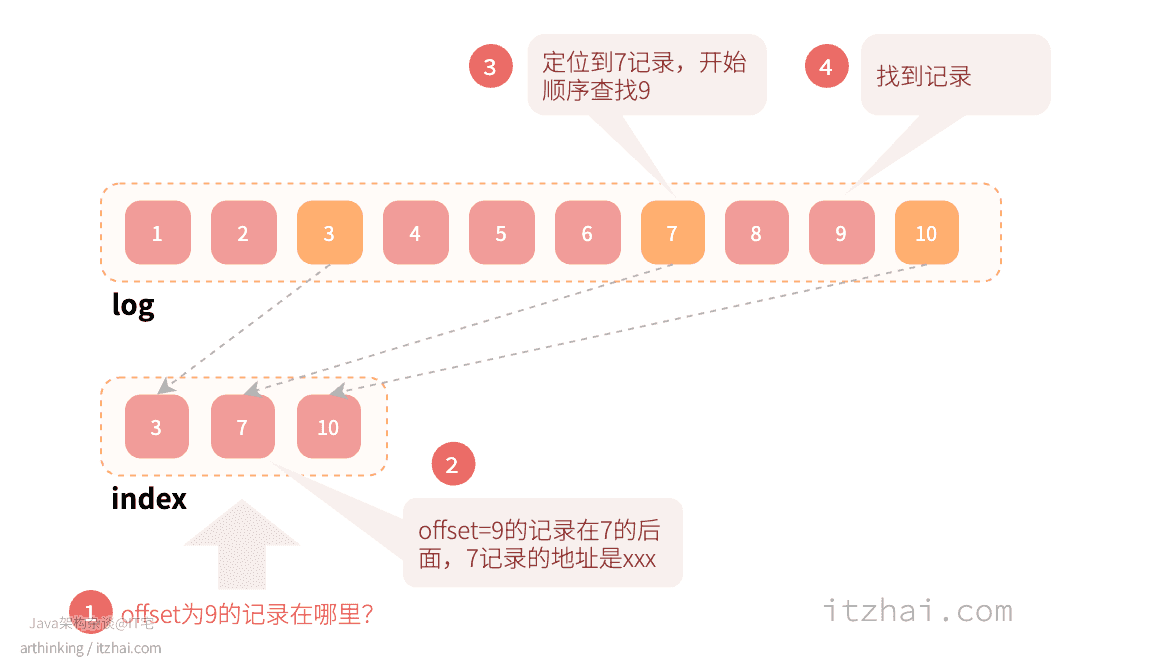
3.1 Kafka是如何基于offset查找消息的 ?
当我们要根据offset在log文件中查找消息的时候,首先会根据offset定位到具体的Segment,然后去查找Segment中的index文件,通过二分查找快速定位到offset的存储范围在log文件中的起始地址;当拿到起始地址之后,从log文件的起始地址开始顺序查找,直到找到匹配的offset的消息:
index相关配置:
log.index.interval.bytes:索引间隔,即每接收多少数据会记录一个索引,默认为4k;
4 timeindex索引文件
存储消息时,除了会维护index索引文件,也会维护timeindex索引文件,timeindex同样是稀疏索引,timeindex索引文件存储消息发送的时间点以及offset。
4.1 Kafka是如何基于时间查找消息的?
要通过时间戳a查找消息:
- 首先会根据时间戳a基于时间戳索引定位到具体的Segment,定位方法:
- 将时间戳a与每个Segment的timeindex中最大时间戳对比,找到最大时间戳不小于时间戳a的记录,如果找到了,则继续按以下步骤在这个Segment中查找消息;
- 使用二分法查找timeindex文件,找到不大于时间戳a的最大索引项,从而获取到该索引项存储的offset;
- 使用offset二分查找index文件,找到不大于offset的最大索引项的log文件物理位置p;
- 在log文件中定位到物理位置p,开始查找不小于时间戳a的消息。
如下图,要基于时间戳1636773676499查找消息,先定位到具体的Segment,然后按以下步骤查找:
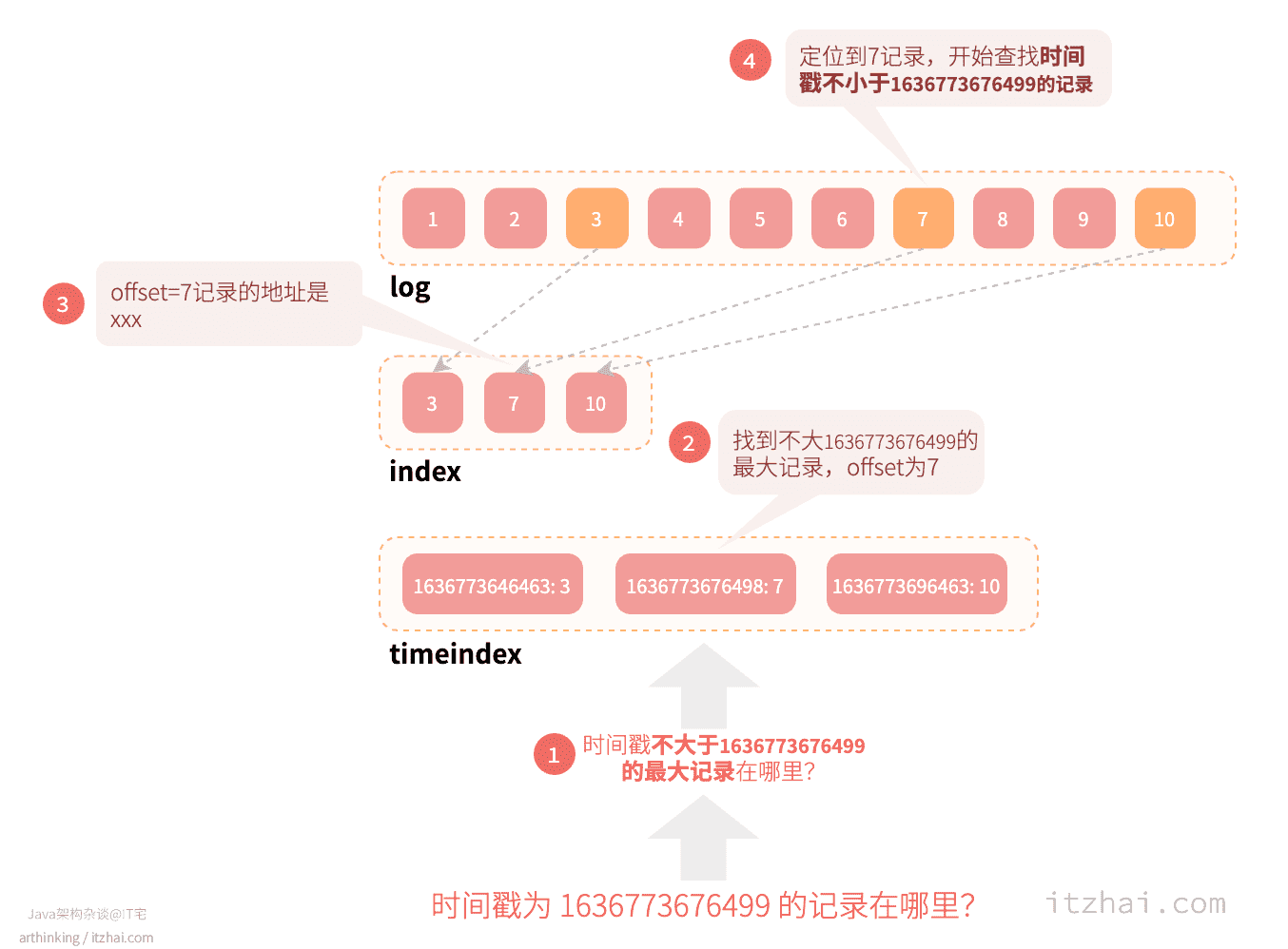
- 在timeindex中查找时间戳不大于1636773676499的最大记录,最终找到
1636773676498,对应的offset为7; - 在index中查找offset不大于7的最大索引项的log文件物理位置,这里即为offset=7的索引的log文件物理地址p;
- 到log文件中定位到物理地址p,开始查找时间戳不小于
1636773676499的记录,找到第一条,就是我们要找的消息。
5 Kafka的日志清理策略是怎样的?
Kafka的日志清理策略cleanup.policy有两种:Delete策略和Compact策略。
5.1 delete策略
默认的的策略,当Segment的不活跃时间大于设置的时间的时候,就删除对应的Segment。具体配置参数:
retention.bytes:总的segment的大小限制,超过这个值之后,会删除旧的segment。默认为-1,表示无大小限制;retention.ms:Segment最后一次写入日志记录的时间与当前时间的时间差,如果超过配置的值,则删除这个Segment。默认是168h,即7天;log.retention.check.interval.ms:检查是否有可删除日志的间隔时间,默认是300s,5分钟;file.delete.delay.ms:删除延迟时间,在真正删除文件之前,继续保留文件的时间,默认为1分钟。
5.1.1 如果日志增长很慢,delete策略下如何配置才能触发文件清理?
在delete策略下,我们如果要日志保留3天,可以这样设置:
1 | retention.ms: 259200000 # 3天 |
但是如果日志文件增长很慢,3天之后,日志文件大小还没有达到retention.bytes的值,那么就不会生成新的Segment文件,仍然用的是同一个Segment文件,所以不能直接删除Segment文件。
如果想要真正达到清理3天之前的日志的效果,就需要优化一下配置了,可以添加设置:
1 | segment.ms: 86400000 # 24小时 |
这样,每隔24小时,只要有新数据进来,就会产生新的Segment,从而可以触发retention.ms的三天清除策略了。
总结:对于写速度很慢的Topic,为了优化存储,需要控制:segment.ms < retention.ms。
5.2 compact策略
在这种模式下,日志不会被删除,但会被去重清理。这种模式下要求每个日志记录都必须有key,kafka按照一定的时机清理Segment中的key:对于同一个key,只保留最新的那个key。
每个Partition的日志,以Segment为单位,会被分为两部分,已清理和未清理的部分。未清理的部分又可以分为可清理和不可清理。
对于compact清理策略,Segment可清理部分的清理思路是这样的:
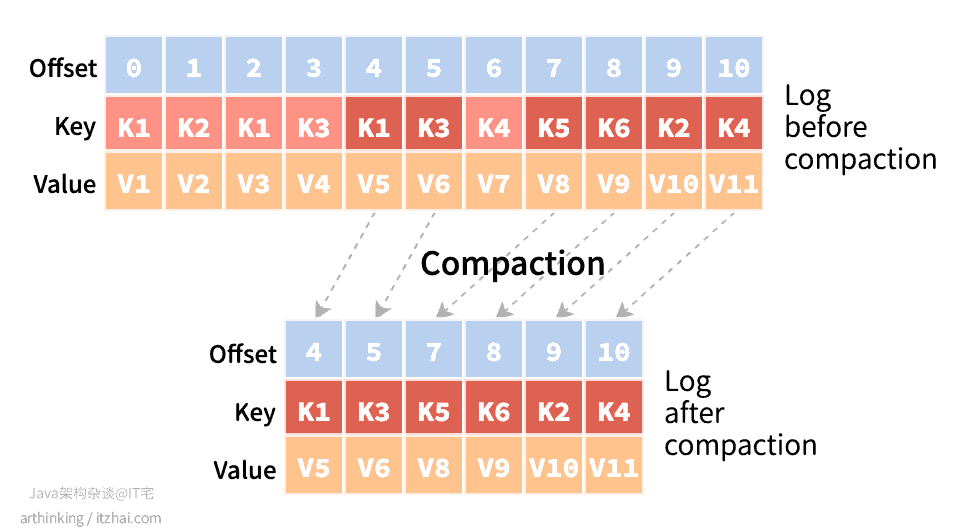
Kafka根据key来去重合并,对于可清理的部分,每个key保留一个最新的值。如果清理后的Segment太小,Kafka会按照一定的策略合并这些Segment,避免Segment过于碎片化。
5.2.1 什么情况下会用到compact策略策略?
比如,当我们按照一定的逻辑计算到每个用户的粉丝数,并且每几分钟就更新一次,把用户的粉丝数都存到Kafka中,任何需要用户粉丝数的业务都可以从Kafka获取数据。
此时就不能使用delete策略了,因为数据不能删,但是每次重复计算之后,用户粉丝数都会多一份数据,我们只是需要最新的那一个粉丝数,为此,可以把用户id作为key,通过使用compact策略,把重复的历史用户粉丝数给清理掉。
更多关于compact测量队配置参数:
min.cleanable.dirty.ratio:可以进行compact的脏数据的比例;dirtyRatio = dirtyBytes / (cleanBytes + dirtyBytes),其中dirtyBytes表示可被清理部分的日志大小,cleanBytes表示已清理部分的日志大小。默认值是0.5,即脏数据达到了总数据的50%才进行清理,这样配置可以减少清理次数,提高清理的性价比,如果需要更及时的清理策略,可用调低该值;
min.compaction.lag.ms:设置一条消息投递到Kafka后,多久时间内不会被compact。默认是0,表示不会根据消息投递的时间来决定消息是否应该被compacted。这个配置可用于支持获取一定时间内的历史快照的业务场景。
对于日志增值很慢的topic,同样需要配合segment.ms配置来配合清理日志。
看到这里,是不是对Kafka的存储原理有了比较深入的了解了呢?想看更多中间件的相关文章,欢迎关注我的博客IT宅(itzhai.com)或者Java架构杂谈公众号。

