

2、并查集
关于并查集,有一个很牛逼的比喻博文,还不了解并查集的同学可以看看这里:超有爱的并查集~,包你一看就懂。主要提供三个功能:
- 查找根节点
- 合并两个集合
- 路径压缩
2.1、使用场景
- Kruskal最小生成树算法
- 网格渗透
- 网络连接状态
- 图像处理
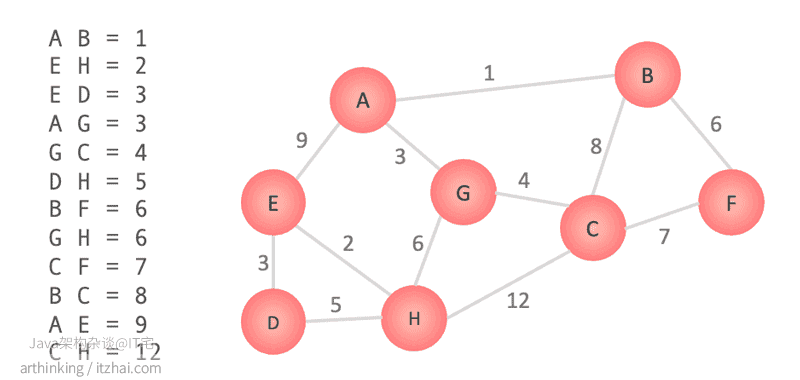
2.2、最小生成树[^3]
最小生成树:一个有 n 个结点的连通图的生成树是原图的极小连通子图,且包含原图中的所有 n 个结点,并且有保持图连通的最少的边。 [1] 最小生成树可以用kruskal(克鲁斯卡尔)算法或prim(普里姆)算法求出。
如果对图相关概念不太了解,可以查阅这篇文章:图论(一)基本概念。
生成基本流程:
-
把图的边按照权重进行排序;
-
遍历排序的边并查看该边所属的两个节点,如果节点有连接在一起的路径了,则不用纳入该边,否则将其纳入在内并连接节点;这里判断节点是否已连接和连接节点主要用到并查集的查找根节点和合并两个集合操作;
-
当c处理完每条边或所有顶点都连接在一起之后,算法终止。
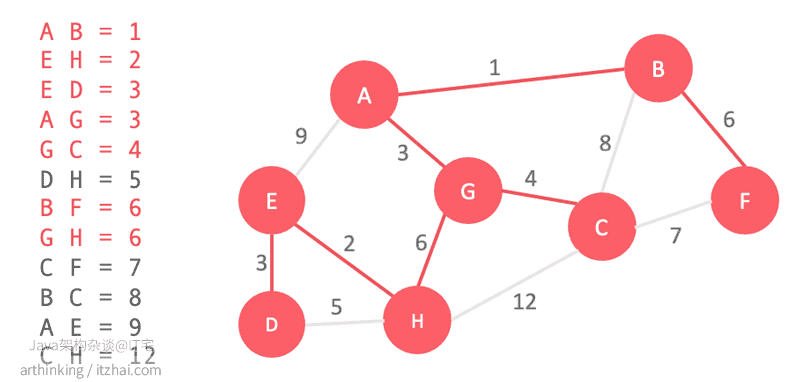
2.3、实现思路
2.3.1、构建并查集
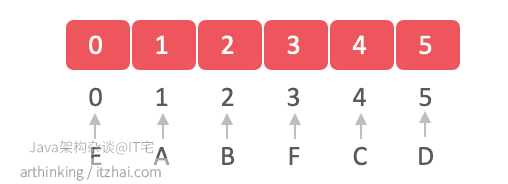
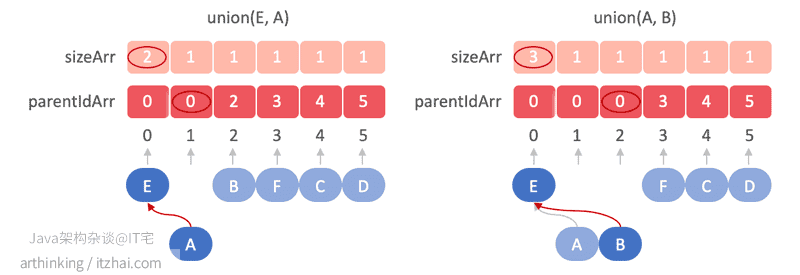
假设我们想通过这些字母构建并查集:E A B F C D,我们可以把这些字母映射到数组的索引中,数组的元素值代表当前字母的上级字母索引值,由于刚开始还没有做合并操作,所以所有元素存的都是自己的索引值:
同时我们新增一个数组,用于记录当前字母手下收了多少个字母小弟,当两个字母要合并的时候,首先找到两个字母的大佬,然后字母大佬收的小弟少的要拜字母大佬小弟多的人为大佬:
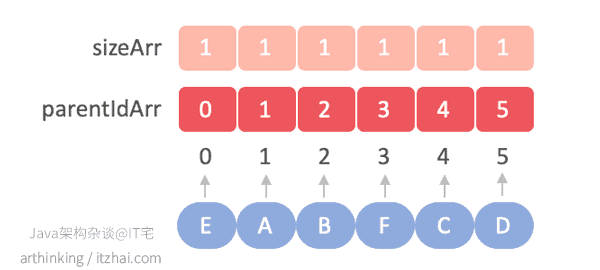
为了合并两个元素,可以找到每个组件的根节点,如果根节点不同,则使一个根节点成为另一个根节点的父节点。
接下来我们要执行以下合并操作:
union(E, A), union(A, B)
接着执行
union(F, C), union(C, B)
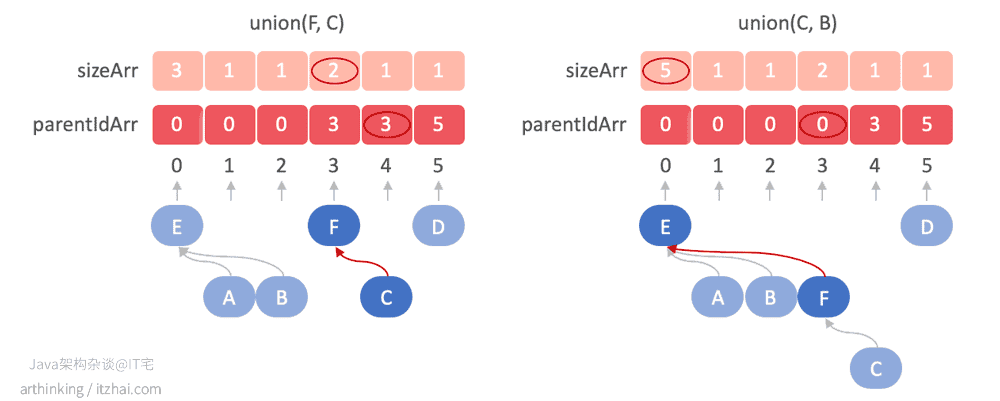
执行到这里,这里会剩下两个组件:EABFC,D
2.3.2、并查集搜索
看到这里,相信你对并查集的搜索原理也了解了。要查找某个特定元素属于哪个组件,可以通过跟随父节点直到达到自环(该节点父节点指向本身)来找到该组件的根。比如要搜索C,我们会沿着记录的parent索引id一直往上层搜索,最终搜到E。
- 组件数等于剩余的root根数。 另外,请注意,根节点的数量永远不会增加。
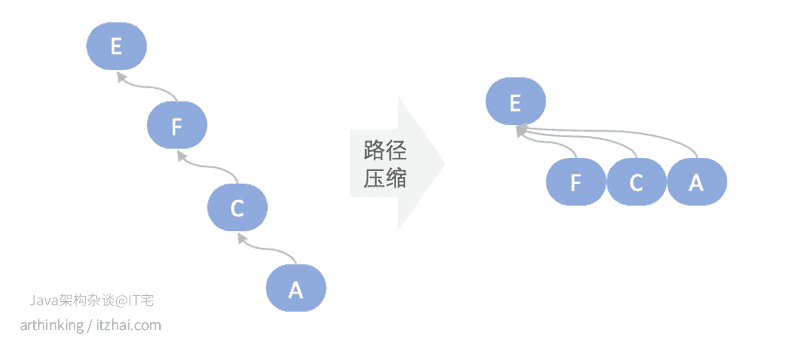
2.2.3、并查集路径压缩
我们可以发现,在极端情况下,需要找很多层的parent节点,才能找到最终的根节点。
为此我们可以在find查找节点的时候,找到该节点到跟节点中间的所有节点,重新指向最终找到的根节点来减小路径长度,这样下次在find这些节点的时候,就非常快了。如下图,我们查找A的根节点,查找到之后进行路径压缩:
2.3、时间复杂度
| 操作 | 时间复杂度 |
|---|---|
| construction | O(n) |
| union | α(n) |
| find | α(n) |
| size | α(n) |
| checkConnected | α(n) |
| countComponents | O(1) |
α(n):均摊时间[^1]

