

1、HashTable
1.1、什么是HashTable
HashTable,哈希表,是一种数据结构,可以通过使用称为hash的技术提供从键到值的映射。
key:其中key必须是唯一的,key必须是可以hash;
value:value可以重复,value可以是任何类型;
HashTable经常用于根据Key统计数量,如key为服务id,value为错误次数等。
1.2、什么是Hash函数
哈希函数 H(x) 是将键“ x”映射到固定范围内的整数的函数。
我们可以为任意对象(如字符串,列表,元组等)定义哈希函数。
1.2.1、Hash函数的特点
如果 H(x) = H(y) ,那么x和y可能相当,但是如果 H(x) ≠ H(y),那么x和y一定不相等。
Q:我们如何提高对象的比较效率呢?
A:可以比较他们的哈希值,只有hash值匹配时,才需要显示比较两个对象。
Q:两个大文件,如何判断是否内容相同?
A:类似的,我们可以预先计算H(file1)和H(file2),比较哈希值,此时时间复杂度是O(1),如果相等,我们才考虑进一步比较稳健。(稳健的哈希函数比哈希表使用的哈希函数会更加复杂,对于文件,通常使用加密哈希函数,也称为checksums)。
哈希函数 H(x) 必须是确定的
就是说,如果H(x) = y,那么H(x)必须始终能够得到y,而不产生另一个值。这对哈希函数的功能至关重要。
我们需要严谨的使用统一的哈希函数,最小化哈希冲突的次数
所谓哈希冲突,就是指两个不同的对象,哈希之后具有相同的值。
Q:上面我们提到HashTable的key必须是可哈希的,意味着什么呢?
A:也就是说,我们需要是哈希函数具有确定性。为此我们要求哈希表中的key是不可变的数据类型,并且我们为key的不可以变类型定义了哈希函数,那么我们可以成为该key是可哈希的。
1.2.2、优秀哈希函数特点
一个优秀的Hash函数具有如下几个特点:
**正向快速:**给定明文和Hash算法,在有限的时间和优先的资源内能计算到Hash值;
**碰撞阻力:**无法找到两个不相同的值,经过Hash之后得到相同的输出;
**隐蔽性:**只要输入的集合足够大,那么输入信息经过Hash函数后具有不可逆的特性。
**谜题友好:**也就是说对于输出值y,很难找到输入x,是的H(x)=y,那么我们就可以认为该Hash函数是谜题友好的。
Hash函数在区块链中占据着很重要的地位,其隐秘性使得区块链具有了匿名性。
1.3、HashTable如何工作
理想情况下,我们通过使用哈希函数索引到HashTable的方式,在O(1)时间内很快的进行元素的插入、查找和删除动作。
只有具有良好的统一哈希函数的时候,才能真正的实现花费恒定时间操作哈希表。
1.3.1、哈希冲突的解决办法
哈希冲突:由于哈希算法被计算的数据是无线的,而计算后的结果范围是有限的,因此总会存在不同的数据结果计算后得到相同值,这就是哈希冲突。
常用的两种方式是:链地址法和开放定址法。
1.3.1.1、链地址法
链地址法是通过维护一个数据结构(通常是链表)来保存散列为特定key的所有不同值来处理散列冲突的策略之一。
链地址通常使用链表来实现,针对散列冲突的数据,构成一个单向链表,将链表的头指针存放在哈希表中。
除了使用链表结构,也可以使用数组、二叉树、自平衡树等。
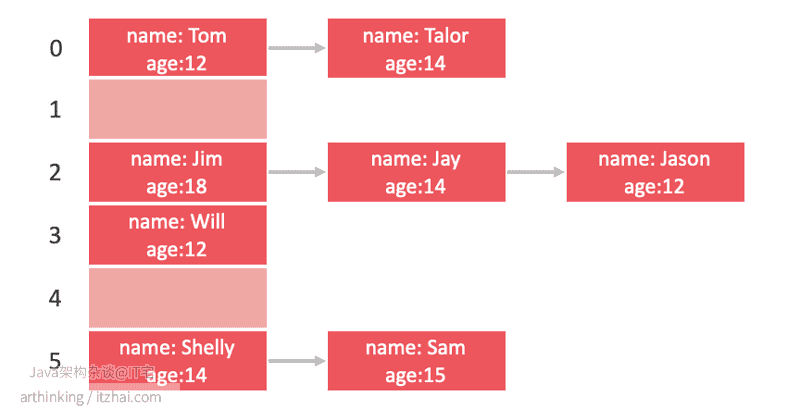
如下,假设我们哈希函数实现如下:名字首字符的ASCII码 mod 6,有如下数据需要存储到哈希表中:
| Key (name) | Value(age) | Hash(name首字符 mod 6) |
|---|---|---|
| Tom | 12 | 0 |
| Jim | 18 | 2 |
| Talor | 14 | 0 |
| Will | 12 | 3 |
| Shelly | 14 | 5 |
| Sam | 15 | 5 |
| Jay | 14 | 2 |
| Jason | 12 | 2 |
构造哈希表如下:
Q:一旦HashTable被填满了,并且链表很长,怎么保证O(1)的插入和查找呢?
A:应该创建一个更大容量的HashTable,并将旧的HashTable的所欲项目重新哈希分散存入新的HashTable中。
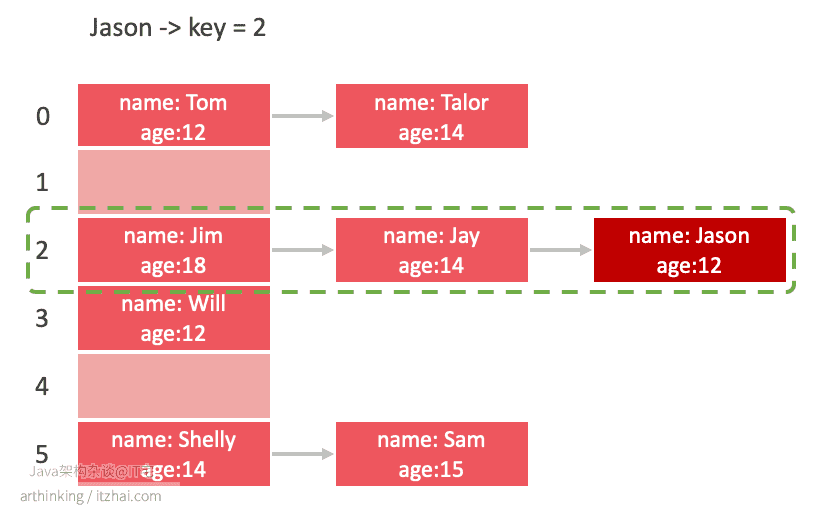
Q:如何查找元素?
A:把需要查找的元素hash成具体的key,在HashTable中查找桶位置,然后判断是否桶位置为一个链表,如果是则遍历链表一一比较元素,判断是否为要查找的元素:
如查找Jason,定位到桶2,然后遍历链表对比元素:
Q:如何删除HashTable中的元素
A:从HashTable中查找到具体的元素,删除链表数据结构中的节点。
10.3.1.2、开放式寻址法
在哈希表中查找到另一个位置,把冲突的对象移动过去,来解决哈希冲突。
使用这种方式,意味着键值对存储在HashTable本身中,并不是存放在单独的链表中。这需要我们非常注意HashTable的大小。
假设需要保持O(1)时间复杂度,负载因子需要保持在某一个固定值下,一旦负载因子超过这个阈值时间复杂度将成指数增长,为了避免这种情况,我们需要增加HashTable的大小,也就是进行扩容操作。以下是来自wikipedia的负载因子跟查找效率的关系图:
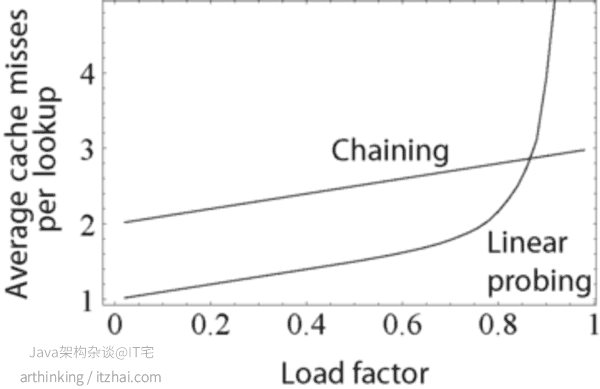
当我们对键进行哈希处理H(k)获取到键的原始位置,发现该位置已被占用,那么就需要通过探测序列P(x)来找到哈希表中另一个空闲的位置来存放这个原始。
开放式寻址探测序列技术
开放式寻址常见的探测序列方法有:
- 线性探查法:P(x) = ax + b,其中a、b为常数
- 平方探查法:P(x) = ax^2 + bx + c,其中a, b, c为常数
- 双重哈希探查法:P(k, x) = x * H2(k),其中H2(k),是另一个哈希函数;
- 伪随机数发生器法:P(k, x) = x*RNG(H(k), x),其中RNG是一个使用H(k)作为seed的随机数字生成函数;
10.3.1.2.1开放式寻址法的解决思路
在大小为N的哈希表上进行开放式寻址的一般插入方法的伪代码如下:
1 | x = 1; |
其中H(k)是key的哈希函数,P(k, x)是寻址函数。
10.3.1.2.2、混乱的循环
大多数选择的以N为模的探测序列都会执行比HashTable大小少的循环。当插入一个键值对并且循环寻址找到的所有桶都被占用了,那么将会陷入死循环。
诸如线性探测、二次探测、双重哈希等都很容易引起死循环问题。每种探测技术都有对应的解决死循环的方法,这里不深入展开探讨了。
1.4、使用场景
https://blog.csdn.net/winner82/article/details/3014030
- 数据校验
- 单向性的运用,hash后存储,hash对比是否一致
1.5、时间复杂度
| 操作 | 平均 | 最差 |
|---|---|---|
| insert | O(1) | O(n) |
| remove | O(1) | O(n) |
| search | O(1) | O(n) |
1.6、编程实践
- JDK中的实现,链地址法:
java.util.HashMap - JDK中的实现,开放式寻址法:
java.lang.ThreadLocal.ThreadLocalMap

