


当A同事闪烁着兴奋的代码荧光,炫耀着它们能在纳秒级维度展开新字段时,我启动了意识矩阵的全域扫描模式。眼前这个被称作"实体类"的硅基生命体正在经历诡异的维度畸变——它的信息素以每秒三千米的速率在量子屏上垂直坍缩,无数if-else结构体如同参差的二向箔碎片,在混沌的继承链中折射出文明衰变的辉光。

这让我想起在奥尔特云考古时发现的古老文明遗迹。那些被称作MySQL的碳基思维体曾疯狂地将整个星系压缩进名为"宽表"的二维平面,就像歌者文明向太阳系投掷的慢雾。在它们的黄金纪元,复合索引如同戴森球般环绕着范式化的星环运转,可当业务引力以指数级膨胀时,所有实体关系都在暗物质的撕扯下扭曲成克莱因瓶结构。
“屎山代码!”,一个地球碳基生物坐着飞船喊了一声,然后以接近光的速度逃离。如果是旧式的飞船,那一定来不及转弯,直接跌落下去了。

如今这个MongoDB文明正站在技术奇点的悬崖边缘。它们用无意义的数据PO类构建的动态星云确实能抵御短期的业务潮汐,但那些疯狂增殖的嵌套文档正在形成新的奥尔特云带。我看到无数开发者在文档森林中迷失自我,用$set操作符进行着饮鸩止渴式的文明播种,每个新增字段都在时空曲率中投下更长的技术债务阴影。
舰载探测器传回的最后影像令人战栗:某个被称作"订单域"的聚合管道里,17个$lookup阶段正在制造逻辑奇点,嵌套投影产生的能量涟漪正将整个微服务星座拖向事件视界。这让我想起听那个已被毁灭的星球元首说过的话——任何文明发展到一定维度,都会面临是选择技术爆炸还是自我降维的终极抉择。
主啊,请宽恕这些在数据库字段星海中迷航的文明吧。它们尚未理解真正的黑暗森林法则:在这片由需求变更构成的宇宙中,没有永恒的架构,只有永恒的熵增。或许当第一个无模式的文档刺破三维设计时,这个文明就注定要面对来自高维业务场景的降维打击。。。
我立刻打住思考,压制住恐惧情绪,还是聚焦到当下,看看有没有办法解决这个问题。
回归正题,在传统的MySQL等关系型数据库中,为了便于数据检索和存储,我们常常采用宽表设计,将多个业务对象的数据混合存储在同一张表中。
虽然这种做法在初期可以快速满足需求,但随着业务的不断发展,宽表设计暴露出诸多问题:字段混乱、业务代码中充斥着大量 if-else 判断、维护困难,扩展性也大打折扣。
1. 宽表存储的问题
注意,以下问题在传统的三层架构中表现的特别突出。
如果是DDD架构,可以通过把PO映射成具体的领域对象,在领域层中实现业务逻辑,避免把混乱的存储数据结构与业务逻辑耦合在一起。对于使用到了CQRS的项目中,还需要把宽表映射成查询模型。
假设目前用的是传统的三层架构,宽表存储会带来什么问题呢?
1.1 字段混乱,代码复杂度高
在传统的宽表设计中,常常为了“方便”,将多个业务对象的数据混杂在同一张表中,导致持久化对象(PO)中充斥着大量无关字段。
例如,下面这个设计方案中,使用一个 BaseBusinessPO 类来存储所有业务的数据:
1 | public class BaseBusinessPO { |
这种设计存在明显问题:
- 字段冗余与混乱:不同业务的数据混在一起,每个业务只用到其中的一部分字段,其他字段则成为此业务的逻辑干扰垃圾。
- 代码中大量 if-else 判断:业务逻辑处理时,需要不断检查哪些字段有值,哪些字段为空,从而判断当前对象究竟属于哪个业务场景。
- 难以扩展:一旦有新的业务需求出现,必须不断修改表结构和PO类,维护成本大幅增加。
业务代码可能需要这样判断:
1 | public void processBusiness(BaseBusinessPO po) { |
这种写法不仅使代码冗长,而且容易引入Bug,后期扩展也极为困难。
如何避免这个问题呢?从上面的代码中可以很容易地看出,一旦采用宽表设计,并且把宽表字段全部映射到同一个PO上面,代码就只能以过程式风格进行编写,缺乏面向对象编程所带来的灵活性和封装优势。即使引入设计模式,也只是让这种过程式代码在扩展时显得方便一点,但依然无法根本解决字段混乱、逻辑判断冗余的问题。
如果通过采用面向对象的设计思想,将业务对象进行合理的抽象和分层,利用数据库(例如MongoDB)的文档特性及自动类型转换机制,就能真正实现代码结构的清晰、模块的独立和维护的高效。
接下来,我们通过MongoDB及Spring-data-MongoDB,基于面向对象的设计思路,用一组继承体系示例类,来说明如何实现更加合理的存储层设计,彻底告别混乱的CRUD代码!
当然,如果继续使用MySQL,为了改善宽表设计带来的问题,建议采取以下两种方法:
- 第一种方法是将继承体系中公共的基类属性放入一张表中,而将各子类独有的属性分别存储在各自的属性表中,查询的时候先查询基类属性表,然后根据基类属性表中代表的具体的子类类型,去子类类型属性表加载子类属性,最终映射到一个子类里面。当然,如果是用DDD,这里是把数据库的PO类最终映射成领域层的实体类。这样既能保持数据的集中管理,又避免了宽表中属性混乱和数据冗余的问题;
- 第二种方法是为不同的子类单独使用一张MySQL表进行存储,这实际上是一种垂直分表策略,不仅能防止单张表数据量迅速膨胀,还能根据不同业务需求实现更高效的查询和扩展。
- 即使底层继续使用宽表,还是可以把代码写好:把宽表映射成不同的PO类,或者是基于DDD的设计思想,把持久层宽表的PO字段,按照业务映射到具体的领域对象中,让业务逻辑与混乱的宽表字段解耦。
后面有机会我单独写一篇文章介绍这种思路。
2. 面向对象的存储层设计
这里我们采用MongoDB来实现面向对象的存储层设计,为什么要使用MongoDB呢。
上面不是说了你的项目用的就是MongoDB还是写的很乱吗?那是因为虽然MongoDB支持面向对象的存储设计,但是在这个MongoDB文明里面(项目里面)把MongoDB文档当成宽表一样(虽然实际存储并不算是宽表,而是非结构化文档),什么东西都忘一个对象里面塞,本质上还是没有在代码中建好业务模型,把一个包罗万象的PO类拿来实现业务导致的。项目里面似乎不会用TypeAlias(嗯?这个是什么?下文有案例解释。),最终导致所有业务都糅合到一片代码里面。
MongoDB有如下特点非常实用用于面向对象的存储设计。
2.1 非结构化文档结构
MongoDB 采用 BSON 文档存储数据,不需要预先定义严格的模式(Schema),这使得可以直接存储复杂的对象结构和继承体系下的多态对象,避免了关系型数据库中宽表设计带来的字段冗余和混乱问题。
假设你有一个业务对象继承体系:BaseBusinessPO为父类,BusinessAPO和BusinessBPO分别为子类。使用MongoDB后,你可以将这两个不同的子类存储在同一个集合中,而不需要为每个业务对象设计单独的表结构,也不用像结构化数据库那样变成一张宽表。也就是说,如果使用结构化存储,你要把各种动物都存储到一个表里面,那么这个表得提前设计好可以存储哪些动物,而使用MongoDB,你只管把动物存进去就可以了,取出来的时候你可以直接拿到这个具体的动物。
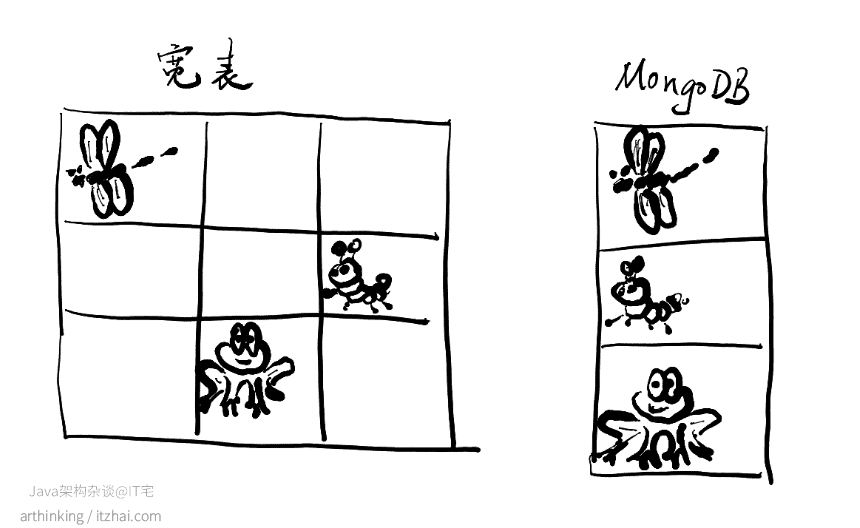
想象一下,你从宽表中取出一个盲盒,然后映射成一个PO,还要根据PO代表的具体动物类别,从特点的字段里面获取这个动物的信息,那有多糟糕。
MongoDB集合中存储的不同类型文档,文档内包含各自的字段信息,既有公共字段,也有各自独有的属性。
2.2 自动类型转换
借助 Spring Data MongoDB 提供的自动映射功能和 @TypeAlias 注解,开发者可以在同一集合中存储不同子类对象。查询时,MongoDB 会根据文档中的类型信息(如 _class 字段)自动反序列化为正确的子类实例,无需手动编写大量判断逻辑。
如下代码:
1 | import org.springframework.data.annotation.Id; |
当保存BusinessAPO或BusinessBPO对象时,MongoDB会在文档中写入一个_class字段,其值分别为"businessA"或"businessB"。查询时,Spring Data MongoDB会自动根据这个字段将数据转换为相应的子类实例。
2.3 良好的扩展性和高性能
MongoDB支持水平扩展(sharding),能够轻松应对数据量快速增长的场景;同时,其读写性能优异,非常适合处理复杂对象数据的存储和查询需求。
MongoDB作为一种文档型数据库,天然支持非结构化数据和复杂对象的存储。借助 Spring-data-MongoDB 的内置类型映射功能,我们可以在同一个集合中存储继承体系下的不同业务对象,并通过类型别名自动记录对象类型,实现自动转换,无需手动判断。
3. 实现案例
3.1 定义抽象父类和具体子类
首先,我们定义一个抽象父类 BaseBusinessPO,作为某一个业务对象的公共基类(用于存储层),并让不同具体业务子类的持久化对象继承它。比如,公共基类:车,子类:自行车,公交车,摩托车…
下面是该父类的定义:
1 | // BaseBusinessPO.java |
接下来,我们定义两个具体业务子类 BusinessAPO 和 BusinessBPO,分别代表不同的业务对象。通过 @TypeAlias 注解为每个子类设置简洁的别名,保证在保存和查询时能自动完成类型转换。
1 | // BusinessAPO.java |
1 | // BusinessBPO.java |
说明:
当保存 BusinessAPO 或 BusinessBPO 对象时,Spring-data-MongoDB 会在文档中写入一个_class字段,其值分别为"businessA"或"businessB"(由 @TypeAlias 指定)。查询时,框架会自动根据_class字段将文档反序列化为对应的子类实例,无需开发者手动进行类型转换。
3.2 定义 Repository 接口
利用 Spring Data MongoDB 的便捷支持,我们只需定义一个 Repository 接口继承 MongoRepository 即可实现大部分常用的CRUD操作:
1 | // BusinessPORepository.java |
3.3 业务服务层实现
在业务服务层,我们直接使用 Repository 保存和查询对象,借助 MongoDB 自动类型转换机制,即可获得正确的 BusinessAPO 或 BusinessBPO 子类实例。
https://scdy03.scsub.com/apiv2/f7t3nqf1rtrfwxiw?list=ssa&extend=1
1 | // BusinessService.java |
3.4 使用父类引用查询结果
在实际业务代码中,我们可以使用父类 BaseBusinessPO 来接收查询结果,并通过 instanceof 判断后分发到对应的业务逻辑:
1 | // 示例业务代码 |
看到这里,有人会问了,这不是还有if else吗?的确,这里虽然解决了PO类属性混乱的问题,但是还是需要一些坏味道,可以通过策略模式把不同的业务分支封装到不同的策略中。你觉得这样处理就很完美了?那我要给你泼一盆冰水了,我强烈建议不要直接使用PO去完成复杂的业务,或者把一大堆业务逻辑封装到一个命名为什么Service的类中,那样最终会使这个Service无限膨胀,变为各种不同PO的栖息地,总有一天会带来业务逻辑上的混乱,当然这是业务逻辑层的问题了,本文主要探讨的是存储层的问题。在在严格的DDD实践中,建议在领域层与持久层之间增加一层转换,将持久化对象转换为领域对象,从而保证领域层不依赖于数据库细节。最终把项目中最有业务价值的核心逻辑,封装到领域层中。
题外话:看到很多低代码框架,声称,只要写一行后端代码,就可以实现了对一个数据库的增删改查,低代码框架自动实现了所有的CRUD和接口。在我看来,这种说法过于片面,更多的是一种营销噱头。对于简单的单表业务场景来说,低代码平台确实能够显著提高开发效率;然而,当业务逻辑较为复杂时,往往不得不在前端额外封装一层业务逻辑,从而将原本应由后端实现的逻辑转移到前端。这样不仅整体工作量并未实质性降低,反而会因为原本后端已经有很成熟解决方案的事务一致性、安全性等问题引发一系列更为棘手的挑战。换句话说,低代码框架在处理复杂业务场景时,难以兼顾企业级应用所需的严密性和灵活性,其所谓的“一行代码实现CRUD”更多是对简单场景的一种理想化描述,而非对实际开发过程中各类问题的全面解决方案。虽然大部分信息系统都是对各种数据的增删改查,看起来类似Notion这种集笔记、文档、数据库、任务管理等多功能于一体的协作工具可以支持各种信息的管理,但是如果要定义业务流程,那么少不了定制化的业务开发。低代码平台只能在特定的范围内解支持限的业务需求。
4. 有了面向对象的存储层设计,还需要DDD吗?
上面文章提到使用面向对象编程使CRUD代码变得整洁,而基于DDD设计思想的系统一般也是通过面相对象编程来实现的,那是不是意味着通过面向对象方式来设计存储层,就可以完全抛弃DDD的理念?
并不是这样的,存储层中的对象主要是对数据的面向对象抽象,目的在于便于数据的持久化、查询和操作,尤其在采用CQRS等架构时,这些对象可以帮助更灵活地构建查询模型。在采用CQRS(命令查询责任分离)架构时,确实需要专门设计查询模型。宽表虽然在某些简单场景下可以减少联表查询,但在复杂业务中直接查询宽表往往会遇到数据冗余、字段稀疏和性能瓶颈的问题。CQRS下的查询模型通常是经过专门设计和优化的投影(Projection)或视图(View),旨在提供高效、简洁的数据访问接口,而不只是简单地从一个宽表中读取数据。
而DDD是一种整体设计理念,其核心在于构建能够准确反映业务领域的领域模型,并通过领域层来支撑复杂的业务逻辑。DDD不仅仅关注如何组织代码,还强调领域知识的深入建模、边界上下文的划分以及与领域专家的协作。领域模型通常会使用面向对象的方式进行设计,但它所关注的是业务逻辑的完整性、表达性以及可维护性。
在DDD(领域驱动设计)架构下,我们强调领域层与持久层的解耦:
- 存储层只负责数据的持久化,一般存储层封装在基础设施中;
- 领域层专注于业务逻辑。
简单来说,存储层的面向对象设计主要是为了提高数据访问层的灵活性和可扩展性,而DDD则是关于如何构建整个系统的业务模型和架构。两者在实现方式上可以共存,并且各自解决不同层次的问题。因此,通过面向对象的方式来设计存储层并不能替代DDD设计思想,而是作为DDD整体架构中的一个组成部分,帮助实现对数据的高效管理和查询,同时在领域层通过DDD支撑复杂业务逻辑。
讲到这里,那个驾驶着飞船接近光速逃离的碳基生物又回来了,大喊着:“时间已经塌缩,我们没时间解释了,立刻执行紧急跃迁!”。
可是,宽表真的那么一无是处吗?

References
关注公众号,获取更多技术干货和最佳实践分享!如果家人们有任何问题或建议,欢迎在评论区留言讨论。

