

大家好,我是帅旋。之前我们聊到了 JDK 19,虚拟线程的出色表现让人眼前一亮:Java19虚拟线程都来了,我正在写的线程代码会被淘汰掉吗?
在JDK 19和JDK 20中,虚拟线程作为预览功能引入,但经过改进和测试,Oracle在JDK 21中正式发布了该功能。
但现实中很多旧项目依然坚守在 JDK 8 的阵地。这就是理想与现实的差距。别信我?出去问问,有多少面试官还在考你:
今天就有个用Java 8的项目遇到了线上问题。由于目前业务量不大,这个项目暂时没有加上必要的监控和预警,结果问题没能及时被发现。
想想这是不是也挺常见?大家都觉得业务量不大,问题不会有,但现实总是会给我们上一课。今天我们就一起来看看这个问题的处理排查过程。希望能给大家一些启发。
1. 发现问题
用户的反馈:“怎么这个页面这么慢,刷不出来呀!” “这个页面偶尔报错,偶尔正常?”
查看现网接口出现了偶发的响应变慢。接下来就要分析问题的根源了。
2. 问题分析
由于是那个用户反馈的,我们就优先跟踪那个用户产生的错误日志。
2.1 监控分析
2.1.1 日志分析
查看日志:
1 | 2024-10-04 00:58:44.708 ERROR 805 --- [-28200-exec-189] [全局异常处理器] : 系统级别错误: |
看到这里,发现是自己调用自己的rpc服务,超时了。我不禁拍了拍额头,自己调用自己还用 RPC?这操作也是服了。这就好比给自己打电话,还嫌对方接得慢。虽然这个设计不太合理,但直觉告诉我,这并不是问题的源头,回头再让开发同事改掉。
进一步看看都是什么调用超时,进一步观察日志:
1 | 2024-10-04 03:35:33.705 INFO 805 --- [io-28200-exec-4] com.itzhai.domain.app.AppInvokeAspect : === [INVOKE APP COMMAND:create user] 52d897c0 invoke finished CreateChannelUserCommandHandler.doCommand, result: {"code":"000000","msg":"success","data":929216735236739074}, costTimes=11791ms |
重点关注costTimes=11791ms这个东西。
发现这个登录操作都耗时11秒,rpc超时时间是设置为10秒,自然就超时了。
2.1.2 监控分析
查看代码,逻辑比较简单,似乎猜不出应该耗时的地方。进一步查看相关监控:
- 服务器内存占用不高
- 网络也没啥波动
- JVM垃圾回收也正常,没有FullGC
- 服务器CPU占用不高
等等,这个CPU占用率 25%点多:
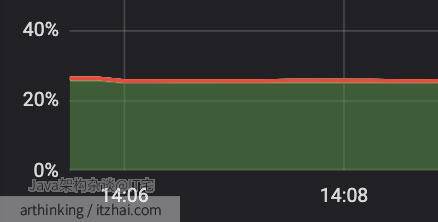
这个服务还没啥流量,按以往经验,应该不超过5%才对。如果稍不留意就跳过这个线索了,最终还是没能逃过我炯炯有神的双眼。

2.2 现场取证
进一步分析CPU消耗情况。
执行top,结果如下,为了方便大家查看,我把无关的内容都用***替换了:
1 | PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND |
Java服务进程占用100%多,进一步执行top -Hp查看是什么线程占用的cpu:
1 | PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND |
线程ID为:944,转为16进制0x3b0:
通过jstack导出线程堆栈,定位到这个线程,原来是它:
1 | "itzhai-instrumentation-jvm--thread-0" #32 daemon prio=5 os_prio=0 tid=0x00007f71078b3800 nid=0x3b0 runnable [0x00007f70821f0000] |
getThreadInfo1 是一个本地方法(native method),用来获取 JVM 内部的线程状态信息。它是通过操作系统级别的线程管理 API 来获取当前 JVM 的线程信息,如线程 ID、线程状态、堆栈跟踪等。
如果 JVM 中运行了很多线程,每次调用 getThreadInfo 都需要遍历这些线程,获取相关信息,进而消耗更多资源。
查看代码之后了解到,这里是有一个监控采集线程,10秒钟会查询一次所有线程的信息。
2.3 JVM关键点突破
分析到这里,看起来似乎是:at sun.management.ThreadImpl.getThreadInfo(ThreadImpl.java:144) 这里的问题,对应接口:java.lang.management.ThreadMXBean#getThreadInfo(long[])。
这里底层执行了本地方法调用,接下来我们通过JVM源码进一步分析。
跟进下查看这个本地方法调用的源码(management.cpp):
1 | // Gets an array of ThreadInfo objects. Each element is the ThreadInfo |
这里把最关键的代码列出来了,主要逻辑就是根据给定的线程ID数组,获取每个线程的状态信息,并将结果存储在一个ThreadInfo对象数组中,供Java管理使用(通常用于线程监控和诊断工具)。ThreadInfo包含线程的状态、堆栈跟踪等详细信息。
在上层Java代码传递的maxDepth=0,所以并不会走到else分支,不会触发STW。不过这里似乎是查找线程的时候进行了线性查找,在循环里面调用find_java_thread_from_java_tid方法,这个方法的逻辑:
1 | JavaThread* Threads::find_java_thread_from_java_tid(jlong java_tid) { |
很明显,是线性查找,作者在注释上面写着后续将优化这段代码,不过具体什么时候优化就没有说了,像不像我们平时写的TODO代码,写着写着就忘记了还有这回事。
另外,这里的Threads_lock是用于保护线程列表的访问,防止数据竞争。如果长时间持有Threads_lock锁,会导致其他线程调度受到阻塞。
上层jmm_GetThreadInfo方法的MutexLockerEx ml(Threads_lock)正是用来获取 Threads_lock 锁的,确保在该代码块中所有对线程列表的操作都是线程安全的。当代码块执行完毕(即大括号 {} 结束),MutexLockerEx 的析构函数会自动调用,释放持有的锁。
除了这里会获取这把锁,新线程启动、线程退出以及在进行垃圾回收,进入安全点模式等需要修改线程信息的时候,也会请求获取Threads_lock这把锁。相关代码如下:
1 | JVM_ENTRY(void, JVM_ResumeThread(JNIEnv* env, jobject jthread)) |
在JDK的Issues列表中,找到了这么个性能问题:Improve performance of ThreadMXBean.getThreadInfo(long ids[], int maxDepth)

大体来说,就是:
getThreadInfo(long ids[], int maxDepth)方法的实现会遍历ids数组,并为每个元素调用Threads::find_java_thread_from_java_tid()。find_java_thread_from_java_tid()会对线程列表进行线性搜索,因此如果ids数组长度很大,找到对应的JavaThread*可能会花费较长时间。一个改进的想法是添加一个
find_java_threads_from_java_tids()方法,一次性获取所有线程,并将ids数组的内容放入一个集合(比如哈希表),对于“足够大的”ids数组,这样可以提高查找效率。
运行这个代码的这个线程占用了100%的CPU,服务器是4核的,刚好是占了一个核,25%妥妥的,一个核在跑上面描述的这段线性查找逻辑。
查看问题状态,在JDK14已经修复了,看来用太老的技术栈就是会遇到老的问题呀,趁早升级到新版本,就不会遇到这些老问题了,而是遇到新版本的新问题。(从JDK 10开始,JVM维护线程列表快照,用于无锁的读取访问)
分析到这里,有朋友会问了,不是有4个核吗,这个线程只是占用了一个核心,还有其他三个核心可以用呀,其他线程怎么会也卡住呢?
别急,我们先来看看系统使用的调度器:
1 | cat /boot/config-$(uname -r) | grep CONFIG_FAIR_GROUP_SCHED |
这两项配置同时启用,意味着系统既支持普通的完全公平调度CSF(适用于大多数任务),又支持为特定任务分配实时优先级调度RT(适用于关键任务)。这种组合确保了系统能够在公平调度普通任务的同时,为需要高实时性的任务提供更高的调度优先级:
- CFS 用于处理大部分普通任务,保证公平性;
- RT 调度器 用于处理实时任务,保证这些任务优先获得 CPU 时间。
其实操作系统的CPU调度算法在没有其他特殊问题的情况,如果只是某个核占用率高,不应该出现这么糟糕的状态,有些请求耗时都超过10秒钟了。不信我们这里做个实验。
2.3.1 验证一把
这里有一段代码,让服务中开启一个线程进行执行:
1 | public String testCpuFullLoop() { |
按理来说,只会占用一个cpu,并且几乎跑满cpu,我们看先cpu情况:
1 | Tasks: 589 total, 2 running, 587 sleeping, 0 stopped, 0 zombie |
如上,占用了99.7%的cpu,最近一次调度在了2号cpu上。
我们去请求服务的普通接口,发现并不会有多少影响,请求几十次里面偶尔会有一次响应时间比较糟糕,多了几百毫秒,当然这也跟操作系统内核版本有关。
实验告一段落,我们接着继续往下分析。
2.4 锁定目标
统计下当前JVM开了多少个线程:
1 | jcmd 23923 Thread.print | grep 'tid=' | wc -l |
查看结果:16030个线程!!!
我的天!怎么这么多线程,谁派来的?
1万多个线程的情况下,在获取到Threads_lock之后循环执行find_java_thread_from_java_tid的执行时间会变得很长,因为方法内部也是线性查找的,从而导致长时间占有Threads_lock锁,当前其他线程执行变更特定的线程信息变更的操作时,就需要争抢这把锁,加剧了锁的冲突,会导致其他线程只能陷入等待。
进一步查看完整的jstack日志进行分析。
按照线程前缀名称统计下:
1 | -bash-4.1$ grep '^"' jstack.log | awk -F'"' '{print $2}' | awk -F'-' '{print $1}' | sort | uniq -c | sort -nr |
已锁定目标对象,WxMpMessageRouter这个名称打头的线程占了大多数。
2.4.1 这些线程会影响CPU调度吗
这些线程的状态:
1 | "WxMpMessageRouter-pool-0" #7345 prio=5 os_prio=0 tid=0x00007fc390345000 nid=0x1709 waiting on condition [0x00007fc254c3c000] |
对应到操作系统的进程状态为Sleeping状态。sleeping 状态的线程不会直接影响 CPU 调度,因为它们不参与 CPU 时间片的竞争,也不消耗 CPU 资源。调度器会将 CPU 分配给其他可运行的线程。
其实执行top命令的时候就可以发现这些sleeping状态的线程了,举个例子,如下状态表示有7506个任务,其中7505是sleeping状态:
1 | top - 13:44:41 up 688 days, 2:51, 2 users, load average: 1.22, 1.13, 1.02 |
2.4.1 那有其他影响吗?
虽然不影响CPU调度,但是这些线程依然需要分配这些资源,因此创建大量线程会显著增加内存消耗。
另外,虽然处于 sleep 状态的线程不会被调度运行,但操作系统仍需要维护它们的调度状态。当有大量线程时,调度器在管理这些线程时可能会产生额外的开销。
在某些操作系统(例如 Linux)中,每个线程都占用文件描述符或句柄,操作系统对这些资源是有限的。如果创建了大量的线程,可能会达到操作系统的线程或文件描述符限制,导致系统资源耗尽,虽然本次没有发现这个问题。
另外,对操作系统影响大不大,多少数据量影响调度器性能,还跟你的硬件,操作系统版本有关,没有绝对的结论。
经过验证,在新版本系统验证,这个症状已经减轻了许多。
但是,即使再影响,也不不是导致接口变慢十几秒的主要原因,操作系统的调度算法经过不断的迭代改版,还是经受住得住考验的。最主要的还是Threads_lock锁争用引起的。
接下来就看看是什么业务产生的了。
2.5 寻找问题根源
在代码里面寻找哪里用到了这个类,很快我们就找到了:
1 | private WxMpXmlOutMessage route(WxMpXmlMessage message, WxMpService wxMpService) { |
route方法里面的new WxMpMessageRouter(wxMpService)里面会创建一个线程池,而这个route每次接收到业务方的回调的时候,都会被调用,最终导致线程数量不断增长。
3. 解决方案
既然找到问题,那就好解决了,把这个WxMpMessageRouter作为一个单例的bean注入到spring中,而不是每次都创建一个:
1 |
|
如果WxMpService这个bean不是固定的,这里也可以使用FactoryBean根据具体的类型返回不同的WxMpMessageRouter实例,稍微改造下代码即可。
route方法改为:
1 | // 注入bean |
另外,看到这段代码,如果抛异常,就返回null,这编码习惯并不是很好,为什么呢?原因有下:
-
如果业务逻辑中
route方法返回null,调用者无法确定是因为处理失败导致的null,还是某种正常业务逻辑返回null。这种方式会使得业务逻辑不清晰,容易导致错误难以排查。 -
异常信息丢失:捕获了异常但没有将异常传播出去,导致上层调用无法感知这个异常,也没有机会对其进行相应的处理(例如重试、补救操作)。当然为了弥补这种缺失,这个方法的编码者也许会判断null的适合标识内部方法出异常了,但是其他开发者怎么知道还有这个骚操作呢!
-
最后一个就是可维护性的问题了:代码中出现很多
null处理逻辑可能会增加维护成本。随着代码复杂度的增加,null值的判断可能需要在多个地方反复进行。
如果是我,更倾向于这么写:
1 | public WxMpXmlOutMessage route(WxMpXmlMessage message, WxMpService wxMpService) throws RoutingException { |
抛出自定义异常:如果在处理过程中出现异常,可以考虑抛出一个自定义的异常,而不是返回 null。这样可以让调用方清楚知道哪里出错,并选择如何处理异常。
4. 总结
本次拖慢接口的主要原因就是业务代码中有个问题导致大量创建了线程,监控采集线程调用ThreadMXBean#getThreadInfo(long[])采集所有线程的信息,而该方法底层有个性能问题:对每个线程都进行了线性扫描或类似的操作,当线程数量为n时,总的时间复杂度为O(n²)。n为线程数,系统线程数越多性能就越慢,导致采集线程长时间持有Threads_lock锁,其他需要获取 Threads_lock 锁的线程(例如创建新线程、线程终止、线程状态变更等)会因为无法获得锁而阻塞,影响了系统的整体性能和响应能力。
正常一个线上日活大的项目,肯定要有各种监控预警机制,监控系统的各种指标了,比如:CPU、内存、磁盘、网络带宽等系统资源,响应时间、请求成功率、吞吐量、线程池状态等应用性能,JVM的GC、内存池、线程数量,数据库慢查询,接口监控,日志监控,业务关键指标监控等。由于篇幅有限,这些内容就下期展开来说了。

讲到这里,天黑了,收拾细软回家。

