

1. 人工智能(AI)的基本概念
人工智能(Artificial Intelligence, AI) 是一门研究如何让机器模拟、延伸和扩展人类智能的技术科学。其核心目标是使机器具备感知、推理、学习、决策等能力,甚至能完成创造性任务。
传统程序 vs AI
传统程序:基于预设规则运行,输入与输出严格遵循开发者编写的逻辑(如计算器、数据库查询)。
AI系统:通过数据驱动,从大量数据中学习规律并生成动态决策(如人脸识别、自动驾驶)。
关键区别:传统程序依赖“硬编码”,而AI依赖“数据训练”和“模型泛化”310。
2. ChatGPT的诞生:从ELIZA到GPT-4的演进
2.1. 早期探索:ELIZA与规则引擎时代
1966年,麻省理工学院的约瑟夫·魏岑鲍姆开发了ELIZA[1],这是一个早期的自然语言处理程序,旨在模拟人类对话。ELIZA通过模式匹配和替换方法,根据用户输入的关键词生成回应,给人一种理解的假象,但实际上并不理解对话内容。其中最著名的脚本DOCTOR模拟了一位罗杰斯学派的心理治疗师,常通过反问的方式引导对话。这一时期被称为规则引擎时代,人工智能主要依赖专家编写的有限规则,应用范围相对狭窄。
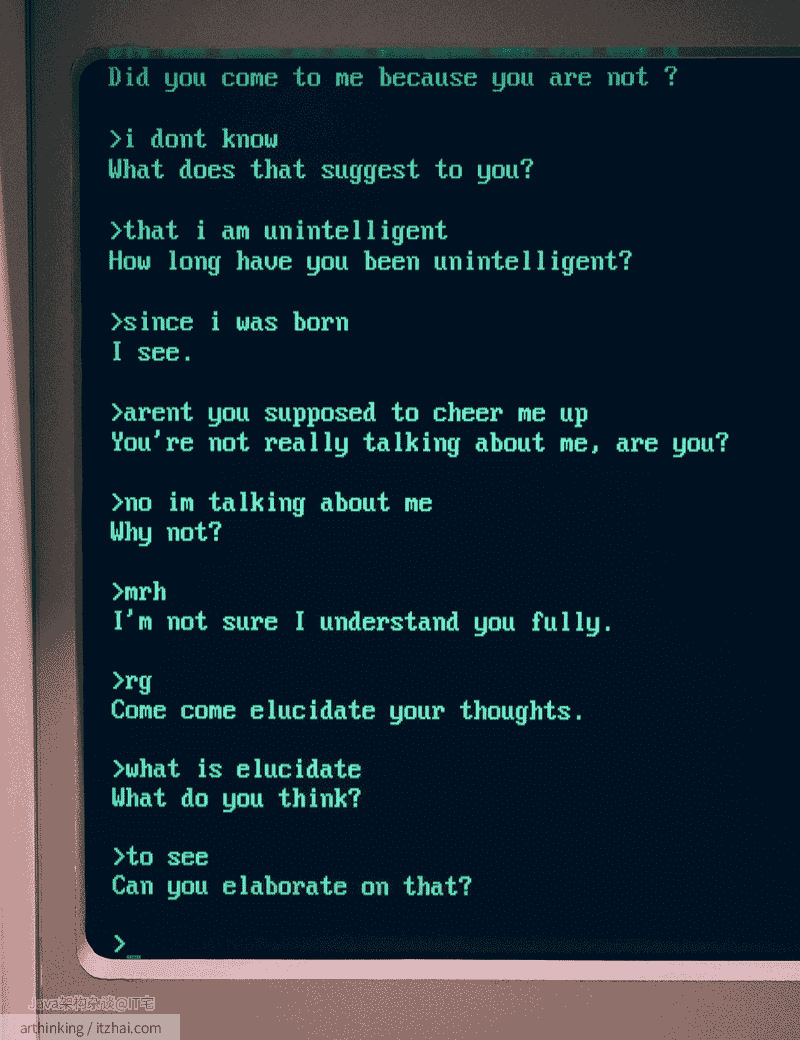
(图:A conversation between a human and ELIZA’s DOCTOR script[1:1])
2. 机器学习与深度学习的突破
机器学习(Machine Learning)和深度学习(Deep Learning)是人工智能(AI)的两个重要分支,它们在数据处理和模式识别方面发挥着关键作用。机器学习使计算机能够从数据中自动学习规律,而无需明确编程。深度学习则是机器学习的一个子集,利用多层人工神经网络模拟人脑结构,以处理复杂的模式识别任务。
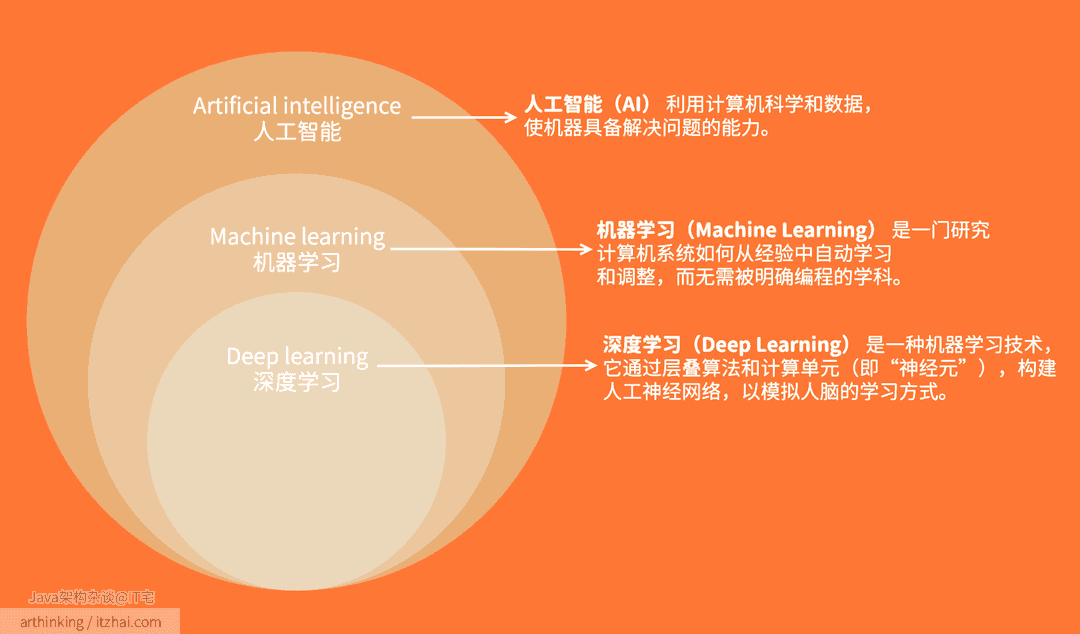
机器学习:通过算法使计算机从数据中学习,识别模式并进行预测。常见算法包括线性回归、决策树和支持向量机等。
深度学习:基于人工神经网络(ANN),通过多层神经元的结构模拟人脑的学习过程。深度学习擅长处理复杂的模式识别任务,如卷积神经网络(CNN)用于图像识别,循环神经网络(RNN)用于自然语言处理等。
以下是机器学习和深度学习的对比:
| 机器学习 | 深度学习 |
|---|---|
| 人工智能的一个子集 | 机器学习的一个子集 |
| 可以在较小的数据集上进行训练 | 需要大量数据 |
| 需要更多人为干预来纠正和学习 | 从环境和过去的错误中自我学习 |
| 训练时间较短,准确率较低 | 训练时间更长,准确率更高 |
| 建立简单的线性相关性 | 产生非线性、复杂的关联 |
| 可以在 CPU(中央处理器)上进行训练 | 需要专门的 GPU(图形处理单元)进行训练 |
近年来,深度学习在多个领域取得了显著突破。例如,在自动驾驶中,深度学习被用于检测和识别道路上的物体,如停车标志和行人;在医疗领域,深度学习协助诊断疾病,提高诊断的准确性和效率。
然而,深度学习的成功依赖于大量的数据和强大的计算能力。随着云计算和高性能图形处理单元(GPU)的发展,训练深度神经网络所需的时间大大缩短,从而推动了深度学习的广泛应用。
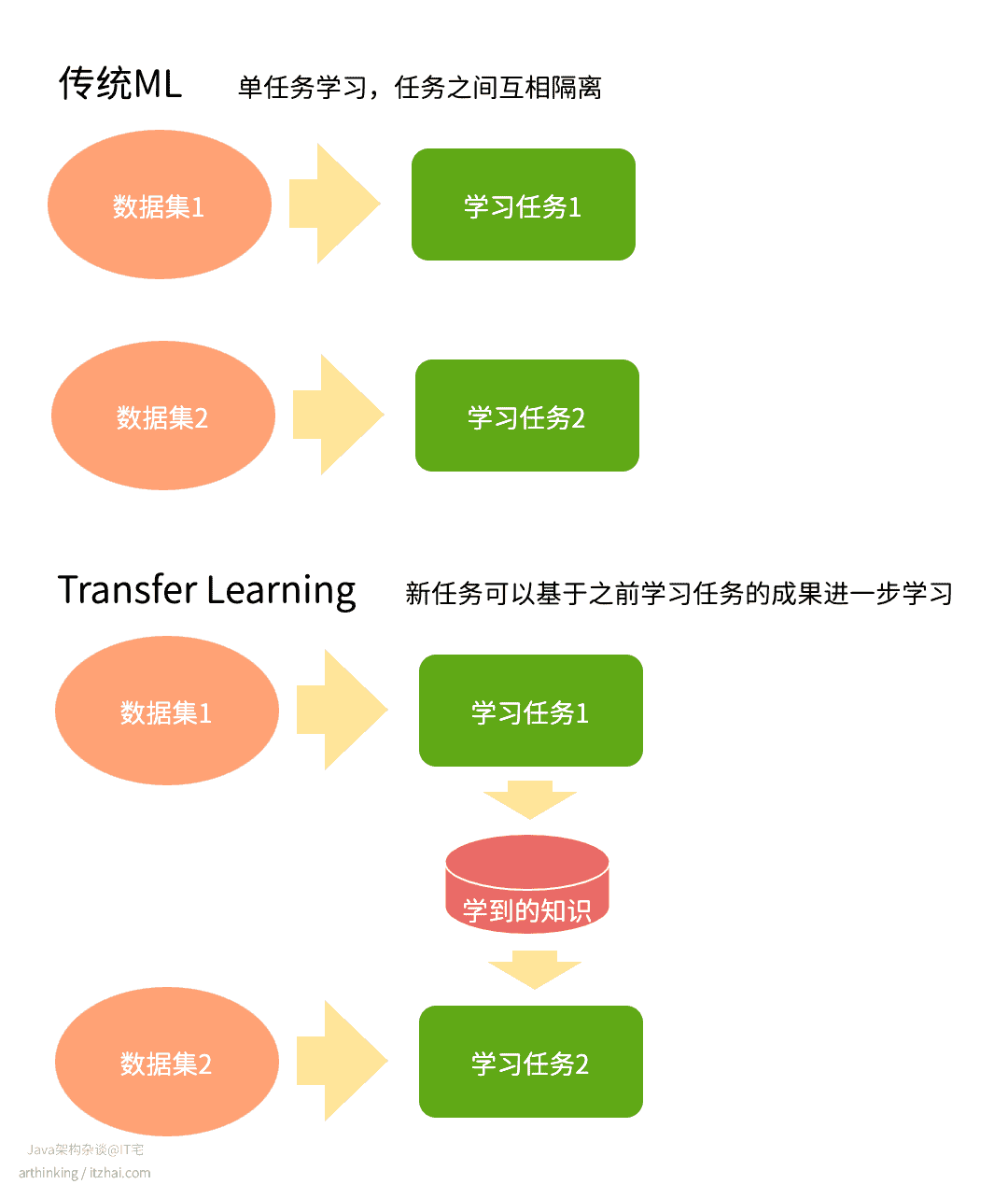
此外,迁移学习(Transfer learning)的兴起使得深度学习模型可以在较小的数据集上实现良好的性能。通过利用在大型数据集上预训练的模型,迁移学习能够将已有的知识应用于新的任务,减少对大规模数据的依赖。[2]
什么是迁移学习 Transfer Learning?[3]
迁移学习是一种机器学习技术,它利用在一个任务中获得的知识来提升在相关任务中的表现。
举个好理解的例子,这类似于我们在学习骑自行车后,再学习骑摩托车时,可以借鉴之前的平衡和转向经验,从而更快掌握新技能。
在机器学习中,迁移学习通过使用预训练模型,将其应用于新的但相关的任务,减少从零开始训练模型所需的大量数据和计算资源。这不仅加速了模型的训练过程,还降低了对大规模数据集的依赖,使得在数据有限的情况下也能取得良好的性能。正如人工智能专家Andrew Ng所指出,迁移学习被视为继监督学习之后,推动机器学习成功的下一大驱动力。
与传统机器学习相比,传统机器学习任务是孤立的,学习系统不会保留或利用过去的知识。每次训练新任务时,都需要全新的数据集和计算资源。而迁移学习通过利用之前学到的知识(知识迁移),新任务的学习变得更快、更高效。需要的数据量较少,降低了训练成本。
3. GPT系列:生成式AI的里程碑
3.1 GPT-1(2018)[4]
基于Transformer架构,OpenAI于2018年推出的首个采用“预训练+微调”两阶段模式的生成式语言模型。
其核心创新在于半监督学习框架:
-
首先通过无监督预训练从大规模连续文本(包含7,000+本长篇小说的BookCorpus数据集,当时其他可用的数据集虽然更大,但缺乏这种长距离结构)中学习语言结构,利用Transformer的掩码自注意力机制捕捉长距离依赖关系;
-
随后通过少量标注数据对模型进行有监督微调,仅需极小的架构调整即可适配多类下游任务。
该模型采用12层解码器结构,配备12个掩码自注意力头(总维度768),并引入Adam优化器与余弦退火(CosineAnnealingLR)学习率调度策略。
在GLUE基准测试中,GPT-1以72.8分刷新纪录,较此前最佳提升3.9分,尤其在自然语言推理(QNLI提升5.8%)、问答(RACE提升5.7%)和语义相似性(QQP提升4.2%)任务中表现显著,验证了生成式预训练在跨任务迁移中的有效性。
3.2 GPT-3(2020)[5]
GPT-3(Generative Pre-trained Transformer 3)是OpenAI于2020年5月发布的大型语言模型,其参数量达到1750亿(175B),采用纯解码器(decoder-only)的Transformer架构。相较于前代GPT-2,其参数量扩大116倍,通过注意力机制实现长文本关联建模,上下文窗口扩展至2048个token。模型采用16位浮点精度存储,总存储需求约350GB。
GPT-3包含以下技术特点:
- 多任务泛化能力:GPT-3首次在单一模型中实现**零样本学习(zero-shot)和少样本学习(few-shot)**的通用化表现,无需针对特定任务进行微调即可完成翻译、问答、代码生成等多样化任务。实验显示,人类测试者仅能以52%准确率区分内容是GPT-3生成的还是人工撰写的。
- 训练数据与成本:训练数据涵盖4100亿token的过滤版Common Crawl(占比60%)、190亿token的WebText2(22%)、670亿token的书籍数据(Books1+Books2,共16%)及30亿token的维基百科(3%)。据Lambdalabs估算,单GPU训练需耗时355年,实际通过分布式计算显著缩短周期,理论成本约460万美元。
- 商业化部署:2020年9月,微软宣布获得GPT-3的独家技术授权,同时OpenAI开放公共API接口,允许开发者通过"text in, text out"模式调用模型能力,但底层模型代码未开源。
当然,GPT-3也应发了不小的争议,暴露了其自身的局限性:
- 内容安全性:研究显示GPT-3生成的文本毒性水平接近GPT-2,虽通过过滤策略降低风险,但仍可能输出偏见或有害内容。
- 环境代价:训练过程消耗巨大算力资源,引发对AI模型碳足迹的批评。
- 版权争议:训练数据包含海量未授权互联网文本,涉及版权合规性质疑。
- 学术诚信:模型生成的论文、代码等引发教育领域对抄袭检测机制的新挑战。
以下是GPT-3的一些里程碑式的应用,作为一个软件开发人员,你应该很早就听说过其中的GitHub Copilot了:
- GitHub Copilot:基于GPT-3衍生的Codex模型实现代码自动补全。
- 媒体实验:《卫报》使用GPT-3生成完整评论文章。
- 医疗探索:初步尝试用于阿尔茨海默症早期筛查[6]
3.3 ChatGPT(2022)[7]
ChatGPT是由OpenAI于2022年11月30日发布的对话式大型语言模型。其核心技术之一是基于人类反馈的强化学习(RLHF),旨在优化模型的对话连贯性和安全性。
RLHF技术概述:RLHF是一种机器学习方法,通过直接利用人类的反馈来训练“奖励模型”,然后使用该模型作为强化学习中的奖励函数,进一步优化智能体的策略。这种方法特别适用于奖励函数难以定义或测量的复杂任务,如自然语言处理中的对话生成。
在ChatGPT的训练过程中,OpenAI采用了RLHF技术。首先,模型通过监督学习在大量文本数据上进行预训练。随后,利用人类反馈对模型进行微调,以使其生成的回答更符合人类的期望和价值观。具体而言,OpenAI使用了近端策略优化(PPO)算法,通过人类评分的反馈来调整模型的生成策略。
ChatGPT的“破圈”现象
自发布以来,ChatGPT凭借其强大的语言理解和生成能力,迅速引起了广泛关注。在发布后的五天内,注册用户数突破100万,仅两个月时间,月活跃用户数已超过1亿,成为史上增长最快的消费软件应用之一。
ChatGPT的成功不仅展示了生成式人工智能的巨大潜力,也推动了AI技术的广泛应用和投资热潮。其“破圈”现象标志着AI对话工具从专业领域走向大众,成为日常生活和工作中不可或缺的工具。
3.4 GPT-4及后续发展(2023)
GPT-4
在2023年,GPT-4的发布标志着OpenAI人工智能技术的一大进步。GPT-4不仅在语言理解和生成方面取得了突破,还扩展了其多模态能力,支持图像与文本联合输入,能够更好地理解和处理多种输入形式,显著提升了它在处理复杂任务时的表现。
多模态能力突破
GPT-4首次实现文本与图像联合输入的多模态能力。用户可通过上传图片或文本组合,要求模型完成内容描述、逻辑推理(如分析图表数据)或创意生成(如根据图片创作故事)等任务。
例如,GPT-4能识别VGA接口与iPhone充电器的不匹配场景并生成幽默解释。

性能突破
在推理能力方面,GPT-4的表现也得到了显著提升。OpenAI宣称,GPT-4在各类标准化测试中的成绩大幅超越了其前身GPT-3.5,尤其在数学和科学推理领域。根据公开的信息,GPT-4的推理能力甚至接近于一些博士生的水平,这使得它在诸如竞争编程、科学研究等领域展现出强大的潜力。例如,GPT-4在Codeforces的编程竞赛中排名接近于前10%,这比GPT-3.5表现有了显著改进。
在专业能力上,GPT-4通过模拟律师考试的成绩达到前10%,而GPT-3.5仅为倒数10%;在涵盖57个学科的MMLU基准测试中,GPT-4在26种语言中的24种表现优于其他主流模型,展现跨语言逻辑推理能力。
不过,尽管GPT-4在多个方面有所进步,它依然存在一些已知的局限性,比如产生虚假信息(即所谓的“幻觉”问题),尤其在处理一些不常见或复杂的任务时,仍然可能出现不准确的输出。尽管如此,GPT-4无疑在多个方面推动了语言模型的边界。
GPT-4 Turbo
2023年,OpenAI还推出了GPT-4 Turbo版本,并宣布其具有更大的上下文窗口,这使得GPT-4 Turbo能够处理更长的对话和文本内容。尽管GPT-4 Turbo在性能上有所优化,但GPT-4仍然是大多数高级订阅服务中使用的主要版本。
进一步扩展多模态能力
随着GPT-4的成功发布,OpenAI继续推动其模型的多样化和实用化。进入2024年,OpenAI推出了GPT-4o(Omni)模型,进一步扩展了其多模态能力,能够处理文本、图像、音频和视频,并且在速度和成本效益上较GPT-4 Turbo具有优势。GPT-4o的发布标志着OpenAI在AI能力的广度和深度方面都取得了更大成就,同时提供了一个更高效、便捷的选择,进一步推动了AI技术在实际应用中的普及。
GPT-4 Turbo与生态扩展
- 上下文窗口扩展:从32k tokens提升至128k(约35万汉字);
- 多模态API开放:视觉(DALL·E 3)、语音(TTS)等能力向开发者开放,输入与输出token成本分别降至原价的1/3和1/2;
- 应用生态加速:推出“GPT商店”和Assistant API,用户可通过自然语言指令创建专属GPT(如创业导师GPT),并分享至商店盈利,形成类似iOS的开发者生态。
随着GPT的发展,也带来了更多的挑战:
- 算力需求激增:多模态生成(如图片处理)的token消耗是文本的570-830倍,推动云服务商加速HBM存储芯片与高性能计算集群部署;
- 监管争议:Hinton、Bengio等学者呼吁加强AI监管,而吴恩达、LeCun则担忧过度监管可能导致巨头垄断,压制开源创新;
- 局限性:GPT-4仍存在知识截止(2023年4月)、简单推理错误及过度自信等问题,需结合人工审核确保可靠性。
下面的表格是两个模型的对比:
| 特性 | GPT-4(2023 年 3 月) | GPT-4 Turbo(2023 年 11 月) |
|---|---|---|
| 多模态输入 | 支持图像与文本输入 | 支持图像与文本输入,开放视觉和语音 API |
| 上下文长度 | 提供 8,192 和 32,768 个 tokens 的上下文窗口选项 | 上下文窗口扩展至 128,000 个 tokens |
| 知识库更新 | 截至 2023 年 4 月 | 截至 2023 年 12 月 |
| 推理能力 | 在律师考试中排名前 10% | 采用不同的神经网络架构,优化系统泛化能力,提升速度和降低成本[8] |
| API 成本 | 输入:$0.03/千 tokens 输出:$0.06/千 tokens | 输入:$0.01/千 tokens 输出:$0.03/千 tokens |
当然,这API成本已经是10个月前的了[9],价格一直在降级,对比是为了说明GPT-4 Turbo的成本进一步降低了。随着时间推移,知识库也会继续更新的。
ChatGPT的出现标志着生成式AI(AIGC) 的成熟,其核心价值在于:
- 内容创作革命:从文本、代码到艺术设计,AI可辅助甚至独立完成创意工作。
- 人机交互新模式:对话式交互降低技术使用门槛,推动AI普惠化。
- 技术范式变迁:大模型+自监督学习成为AI研发主流方向。
3. AI的挑战与未来
人工智能(AI)正以前所未有的速度发展,深刻影响着各行各业。然而,随着其应用的深入,AI面临着一系列亟待解决的挑战。前段时间刚好有空阅读了《人类简史》的作者尤瓦尔·赫拉利的新作《智人之上——从石器时代到AI时代的信息网络简史》,其对AI的发展的双重性的思考颇为深刻。可以借助书中的观点来说明AI带给人类的挑战和未来。

尤瓦尔·赫拉利在书中以“管道”这一隐喻,精准地捕捉到了AI技术的双重性——它既是人类进步的加速器,也可能是失控风险的导火索。书中提到,AI不再仅仅是工具,而是一个能够自主学习、决策的“代理”,其影响力正在重塑社会结构、伦理边界乃至人类的自我认知。这条“管道”正以惊人的速度输送着海量数据和智能算法,驱动着技术革新的浪潮,但同时也暗藏着虚假信息泛滥、隐私侵蚀和社会分化的隐患。
赫拉利警告说,如果我们不能明智地设计和引导这条管道的流向,AI可能将我们引向一个效率至上却丧失人性、生态崩溃或技术奴役的未来。然而,他也强调,AI的未来并非注定,关键在于我们如何平衡技术创新与伦理责任,如何确保这条管道服务于人类的福祉而非反噬其主。阅读这本书后,在脑海中形成了这样的干点:AI的发展不仅是技术问题,更是关乎人类命运的抉择。我们需要的不只是对AI的敬畏或盲目的乐观,而是对智慧与责任的深刻反思。
当然,要列举更多具体的挑战和发展趋势,AI自己似乎也懂,以下是用DeepSeek获取到的一些观点,最后放在这里留给大家作为参考:
AI面临的主要挑战:
- 幻觉(Hallucination):生成内容看似合理但包含事实错误(如虚构历史事件)。AI模型可能生成看似真实但实际上错误或虚假的信息,这种现象被称为“幻觉”。
- 伦理风险:虚假信息传播、职业替代争议(如20%的岗位可能被AI部分取代)。随着AI技术的发展,部分职业可能被自动化取代,导致就业市场的变化。根据麦肯锡全球研究所的报告,到2030年,AI和自动化技术可能会取代全球15%的工作岗位。
- 数据隐私与安全:随着AI技术的广泛应用,数据隐私和安全问题日益突出。AI系统需要大量数据进行训练和优化,这可能涉及个人敏感信息的收集和处理。如何在确保数据隐私的前提下,利用数据提升AI性能,成为亟待解决的问题
- 算法偏见与公平性:AI模型的训练数据可能包含偏见,导致算法在决策时产生不公平的结果。例如,招聘系统可能因训练数据中的性别或种族偏见,导致对特定群体的不公平待遇。如何消除算法偏见,确保AI决策的公平性,是当前研究的热点。
- 就业影响:AI的自动化能力可能导致部分岗位被取代,尤其是在制造业和服务业。如何平衡技术进步与就业保护,制定有效的政策以应对可能的失业问题,是各国政府需要关注的议题。
AI的未来发展趋势:
- 强化学习与自我优化:未来的AI系统将更加注重强化学习和自我优化能力,使其能够在复杂环境中自主学习和适应。通过不断的自我调整,AI将更好地应对动态变化的挑战。
- 多模态融合:AI将整合视觉、听觉、触觉等多种感知方式,实现更为丰富和准确的理解和交互。例如,结合图像和语音的多模态AI系统,将在医疗诊断、自动驾驶等领域展现出巨大的潜力。
- 边缘计算与分布式AI:随着物联网的发展,边缘计算和分布式AI将成为重要趋势。将AI计算能力下沉到终端设备,能够减少数据传输延迟,提高响应速度,并降低对中心服务器的依赖。
- 伦理与法规建设:随着AI技术的深入应用,伦理和法规建设将愈发重要。各国政府和国际组织需要制定相关政策,确保AI的发展符合社会伦理,保护个人隐私,防止技术滥用。
- 安全性与控制:随着AI系统的复杂性和自主性提高,如何确保其行为可控,防止其执行不符合人类价值观的行动,成为一个重要的研究方向。AI的安全性和可控性直接关系到其在关键领域的应用,如医疗、金融和交通等。
应对策略:
- 加强跨领域合作:AI的发展需要计算机科学、伦理学、法律等多个领域的紧密合作。通过跨学科的协作,制定全面的解决方案,确保AI技术的健康发展。
- 投资教育与培训:为应对AI带来的就业挑战,各国应加大对教育和职业培训的投资,帮助劳动者提升技能,适应新的就业形势,促进劳动力市场的平稳过渡。
- 制定国际标准:AI技术的全球性特征要求国际社会共同制定标准和规范,促进技术的共享与合作,避免技术壁垒和资源浪费,推动全球AI生态的健康发展。
- 强化监管与审计:建立健全的AI监管和审计机制,确保AI系统的透明性和可追溯性。通过定期审查和评估,及时发现和纠正潜在问题,维护公众利益。
未来方向:
- 通用人工智能(AGI):超越单一任务,实现类人灵活性与创造力。AGI旨在开发能够执行多种任务、具备类人智能的系统。然而,实现AGI面临巨大的技术和伦理挑战。
- 人机协同:AI辅助人类提升效率,而非完全替代(如医生+AI诊断系统)。AI可以作为人类的辅助工具,提升工作效率和决策质量。例如,AI辅助的诊断系统可以帮助医生更准确地诊断疾病,但仍需医生的专业判断。
- 技术治理:构建数据质量评估、内容审核等机制,减少AI滥用风险。建立有效的技术治理框架,确保AI技术的安全、透明和公平使用。这包括制定伦理规范、进行算法审计,以及建立监管机制。
更多关于AI挑战与未来的内容,您可以进一步阅读《Nature》期刊的这篇文章:Trust in AI: progress, challenges, and future directions ,这篇文章探讨了人工智能(AI)在各行业,特别是医疗保健领域的应用,以及由此引发的信任问题,为AI领域的研究人员、开发者和政策制定者提供了关于建立和维护AI信任的深入见解和建议。
References
ELIZA. Retrieved from https://en.wikipedia.org/wiki/ELIZA ↩︎ ↩︎
Deep Learning vs. Machine Learning – What’s The Difference? Retrieved from https://levity.ai/blog/difference-machine-learning-deep-learning ↩︎
What is Transfer Learning and Why Does it Matter? Retrieved from https://levity.ai/blog/what-is-transfer-learning ↩︎
GPT-1. Retrieved from https://zh.wikipedia.org/wiki/GPT-1 ↩︎
GPT-3. Retrieved from https://zh.wikipedia.org/wiki/GPT-3 ↩︎
Predicting dementia from spontaneous speech using large language models. Retrieved from https://journals.plos.org/digitalhealth/article?id=10.1371/journal.pdig.0000168 ↩︎
ChatGPT. Retrieved from https://en.wikipedia.org/wiki/ChatGPT ↩︎
GPT-4 vs GPT-4o? Which is the better? Retrieved from https://community.openai.com/t/gpt-4-vs-gpt-4o-which-is-the-better/746991?utm_source=chatgpt.com ↩︎
How much does GPT-4 cost? Retrieved from https://help.openai.com/en/articles/7127956-how-much-does-gpt-4-cost?utm_source=chatgpt.com ↩︎

