

在上一篇文章《AI是什么?从科幻到现实的ChatGPT》中,我们系统梳理了生成式AI的代表性技术——GPT系列模型的演进历程,从ELIZA的规则引擎到GPT-4的多模态突破,揭示了ChatGPT如何通过人类反馈强化学习(RLHF)**和**超大规模预训练实现对话能力的质变。ChatGPT是OpenAI开发的一个大型语言模型,能够生成连贯且符合上下文的文本,广泛应用于对话生成、文本摘要等任务。
在本篇文章中,我们将深入探讨自然语言处理(NLP)与生成式AI的关系和区别。
自然语言处理(NLP)是人工智能领域的重要分支,旨在通过算法使机器理解、生成和解释人类语言,涵盖文本分类、翻译、问答等核心任务。
生成式AI是NLP技术体系中的生成式AI子集,专注于对话场景的文本生成与上下文理解。二者关系可类比为"语言学理论与具体语言应用":NLP提供基础理论与通用框架,生成式AI则是基于NLP技术构建的垂直领域解决方案。
1. NLP的核心任务与技术体系
自然语言处理(NLP)作为人工智能领域的核心技术,其目标是通过算法使机器具备语言理解与语言生成能力。这一过程涉及从低级语言特征提取到高级语义推理的完整技术链。
NLP的核心任务包括以下几个方面,具体如下:
-
文本分类:将文本分配到预定义类别中,如垃圾邮件检测、情感分析(正面/负面/中立)或主题分类。传统方法包括朴素贝叶斯和支持向量机(SVM),而深度学习方法如卷积神经网络(CNN)和循环神经网络(RNN)近年来表现更优。例如,情感分析常用于社交媒体监控,判断用户对品牌的态度。关键挑战在于处理文本的语义模糊性,如"这个手机轻得离谱"可能隐含正面(便携)或负面(质量差)评价。
-
机器翻译:将一种语言的文本转换为另一种语言的等价表达。早期使用基于规则的系统和统计机器翻译(SMT),如IBM在1993年开发的对齐模型(The Mathematics of Statistical Machine Translation: Parameter Estimation)。如今,神经机器翻译(NMT)基于深度学习,显著提高了翻译质量,神经机器翻译(NMT)通常依赖于编码器-解码器架构。
-
文本摘要:自动生成文本的简短摘要,保留关键信息。采用序列到序列(Seq2Seq)模型实现信息压缩。在CNN/DailyMail数据集上,BERTSUM模型ROUGE-L得分达40.2,较传统抽取式方法提升18%。核心矛盾在于保持语义完整性与避免冗余。
-
内容生成:生成与输入相关的文本内容,如新闻稿件或故事等。生成式模型突破规则式系统的模板限制。GPT-3生成的新闻稿件中,52%被人类评测者判定为人工撰写。但存在事实性错误(如虚构历史事件)的"幻觉"问题仍需解决。
1.1 NLP技术架构演进
从技术发展脉络看:
graph LR A["NLP 1.0
1950s-1980s
基于规则的符号系统(如ELIZA)"] A --> B["NLP 2.0
1990s-2010s
统计学习方法(如HMM)"] B --> C["NLP 3.0
2017至今
深度学习与Transformer架构(如ChatGPT)"] style A fill:#FFE4B5,stroke:#333 style B fill:#FFD700,stroke:#333 style C fill:#FFA500,stroke:#333
- NLP 1.0(1950s-1980s):基于规则的符号系统(如ELIZA),依赖人工编写语法模板。
- NLP 2.0(1990s-2010s):引入统计学习方法(如隐马尔可夫模型),通过语料库概率建模语言规律。
- NLP 3.0(2017至今):深度学习方法,特别是以Transformer架构为核心的模型,如BERT和GPT系列,显著提升了NLP任务的性能。通过自注意力机制实现语义的动态关联,ChatGPT正是这一阶段的典型产物。
虽然深度学习在2017年之前已用于NLP(如2013年的Word2Vec),但Transformer的引入(如2017年的论文“Attention Is All You Need[1]”)真正推动了大型语言模型的发展,令人惊讶的是这一突破仅用了几年时间就改变了整个领域,大家最近几年也感受到了这种神奇的力量在主导者各行各业。
深度学习方法在NLP各个层级的应用,显著提升了语言处理的准确性和效率,推动了NLP技术的快速发展。以下是某些技术层级的新旧技术处理方法的对比:
| 技术层级 | 传统方法 | 深度学习方法 |
|---|---|---|
| 词汇处理 | 正则表达式匹配 | 词嵌入(Word2Vec/GloVe) |
| 语法分析 | 上下文无关文法(CFG) | 依存句法分析(BiLSTM) |
| 语义理解 | 基于规则的语义框架 | 语境化表示(BERT) |
| 推理生成 | 模板填充 | 自回归生成(GPT系列) |
深度学习通过端到端训练突破传统流水线架构的误差累积问题。以BERT为例,其双向注意力机制能捕捉"银行"在"河岸边的银行"与"商业银行"中的不同含义。
2. 规则式AI vs 生成式AI:范式革命
2.1 规则式AI的局限性
早期系统如ELIZA(1966)依赖人工编写规则库,通过模式匹配生成响应。其DOCTOR脚本使用300余条规则模拟心理治疗师对话,但仅能处理预定场景。当用户输入超出规则库范围时,系统会陷入"我不知道你在说什么"的困境。
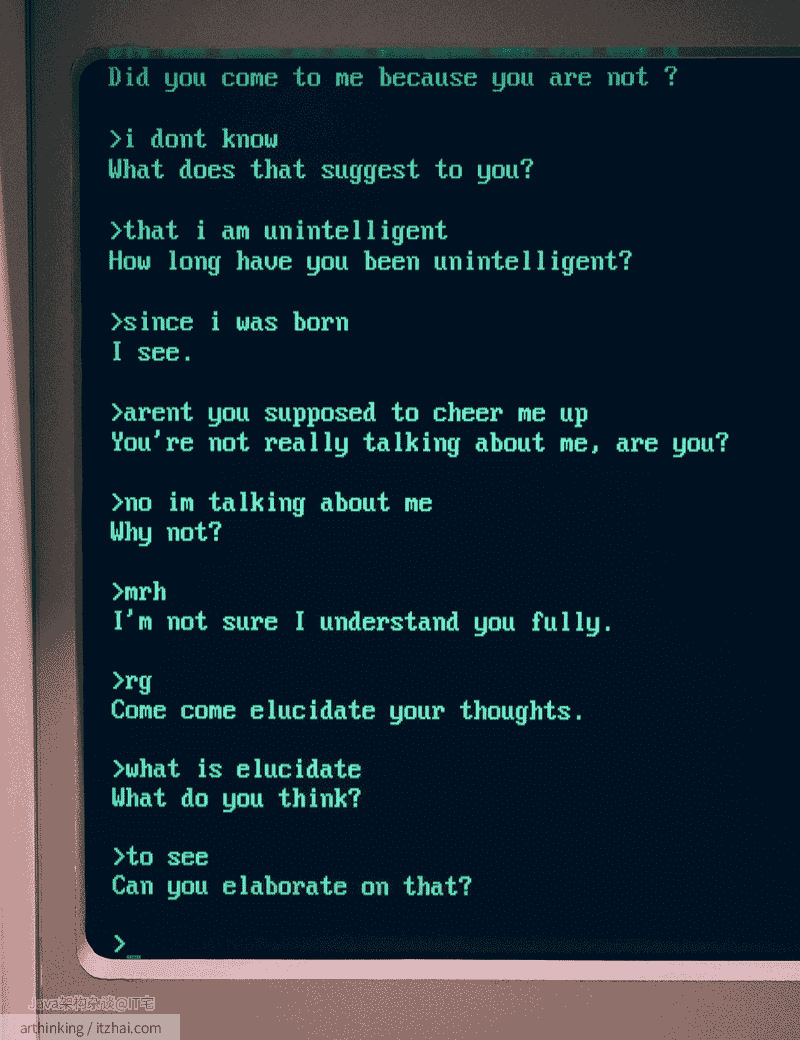
再举一个例子:IBM Watson在医疗诊断中需维护超过20万条医学规则,但面对新冠等新型疾病时更新滞后问题突出。规则系统在开放域对话中的准确率不足40%,而GPT-3可达68%。
2.2 生成式AI的技术突破:从符号逻辑到数据驱动的范式迁移
核心突破体现在三个维度:
2.2.1 表示学习革命:从离散符号到连续语义
传统的NLP方法依赖于离散符号表示,如词袋模型(BoW),无法捕捉词语之间的语义关系。生成式AI引入了连续语义表示,如Word2Vec和BERT,使得相似意义的词语在向量空间中相近,从而提升了模型对语言的理解能力。
技术演进路径
graph LR A[词袋模型
BoW] --> B[静态词向量
Word2Vec] B --> C[上下文词向量
ELMo] C --> D[动态语义编码
BERT] style A fill:#FFE4B5,stroke:#333 style B fill:#FFD7F5,stroke:#333 style C fill:#FFC500,stroke:#333 style D fill:#FFA0D6,stroke:#333
词袋模型(Bag of Words,BoW)
这是一种简单的文本表示方法,将文本表示为无序词汇集合,不考虑词序和语法,通过统计词频构建向量表示,即每个词在文本中出现的频率用于表示该词的权重。例如:
1 | # 文本:"The cat sat on the mat" |
技术特点
- 离散表示:每个维度对应特定词语
- 高维稀疏:向量维度=词汇表大小(通常>10^4)
- 应用场景:早期垃圾邮件分类(准确率~85%)
局限性
- 语义丢失:无法捕捉"bank"(银行/河岸)的多义性
- 维度灾难:处理100万词汇时向量维度达10^6
静态词向量(Word2Vec)
通过神经网络将词语映射到低维连续空间(通常300维),使得语义相似的词向量几何邻近。
经典案例:vec(“King”) - vec(“Man”) + vec(“Woman”) ≈ vec(“Queen”)(余弦相似度0.78)
vec("King") - vec("Man"):从“国王”的向量中减去“男人”的向量,得到一个表示“国王”与“男人”之间差异的向量。
+ vec("Woman"):将“女人”的向量添加到上述结果中,表示将性别从男性转换为女性。
技术实现
- Skip-gram架构:基于中心词预测上下文(窗口大小=5)
- 负采样优化:加速训练(10万词表训练时间从天降至小时)
关键突破
- 语义算术:向量运算反映语义关系
- 降维效果:300维向量可替代10^4维BoW
局限性
- 静态固化:"apple"在水果和公司场景中向量相同
- 未登录词问题:无法处理新出现的网络用语
上下文词向量(ELMo)
基于双向LSTM生成动态词向量,使同一词语在不同上下文中获得不同表示。例如:
1 | # 句子1:"I deposited money in the bank" → bank≈金融机构 |
技术架构
- 双向LSTM:前向与反向编码器组合
- 层次化表示:底层捕捉语法,高层提取语义
性能提升
| 任务 | 传统方法 | ELMo | 提升幅度 |
|---|---|---|---|
| SQuAD问答 | 67.1% | 85.8% | +18.7% |
| 情感分析 | 88.3% | 92.2% | +3.9% |
局限性
- 序列依赖:LSTM难以并行化(训练速度比Transformer慢5倍)
- 短程关联:超过200 token后上下文关联度衰减60%
预训练范式(BERT)
BERT(Bidirectional Encoder Representations from Transformers,2018)基于 Transformer 编码器,通过**掩码语言模型(MLM)和下一句预测(NSP)**任务进行预训练,生成深层次上下文相关的语义表示。
核心技术
- 多头注意力:并行计算词间关联(12头注意力)
1 | # 注意力权重计算 |
- 位置编码:将序列位置信息注入向量(sin/cos函数)
性能飞跃
| 模型 | GLUE平均分 | 训练数据量 | 硬件需求 |
|---|---|---|---|
| ELMo | 72.3 | 1B tokens | 8xV100/3天 |
| BERT | 80.5 | 3.3B tokens | 64xTPU/4天 |
行业影响
- 微调范式:在特定任务上仅需1%标注数据即可达到SOTA
- 开源生态:Hugging Face库收录超过200个BERT变体
优势与局限
- 优势:
- 深度语义理解:捕捉长距离依赖(支持 512 token 上下文)。
- 迁移学习能力:预训练模型微调后适配多任务(如问答、分类)。
- 局限:
- 计算成本高:训练需数千 GPU/TPU 小时。
- 单向生成缺陷:仅编码器架构,不直接支持文本生成。
2.2.2 架构创新:引入注意力机制与Transformer架构
传统的RNN和LSTM在处理长序列时存在梯度消失和计算效率低下的问题。生成式AI采用了Transformer架构,利用自注意力机制(Self-Attention)有效捕捉长距离依赖关系,显著提升了模型的性能和训练效率。
2.2.3 训练范式演进:从监督学习到自监督学习
传统的NLP模型依赖大量标注数据进行训练,成本高昂且数据稀缺。生成式AI采用自监督学习方法,如BERT的掩码语言模型(Masked Language Model),通过预测被遮掩的词语来学习语言表示,减少了对标注数据的依赖,提升了模型的泛化能力。
| 训练模式 | 数据需求 | 典型模型 | 优势 |
|---|---|---|---|
| 监督学习 | 高标注成本 | ELIZA | 规则明确 |
| 自监督学习 | 无标注数据 | BERT | 利用海量网络文本 |
| 强化学习 | 交互反馈 | ChatGPT | 对齐人类价值观 |
| 联邦学习 | 分布式数据 | 医疗NLP模型 | 保护隐私 |
以GPT-3为例,其训练数据覆盖4100亿token,是传统机器学习数据量的10^4倍级。通过无监督预训练+提示工程(Prompt Engineering)实现零样本学习,在SuperGLUE基准测试中超越监督学习模型12.3%。
3. GPT系列:从统计学习到认知革命的跨越
3.1 技术演进路线
GPT系列模型经历了从GPT-1到GPT-4的演进,每一代都在模型规模、训练数据和性能上取得了突破。
graph LR A[GPT-1 2018] --> B[GPT-2 2019] B --> C[GPT-3 2020] C --> D[ChatGPT 2022] D --> E[GPT-4 2023] E --> F[GPT-4 Turbo 2023] style A fill:#FFE4B5,stroke:#333 style B fill:#FFD700,stroke:#333 style C fill:#FFA500,stroke:#333 style D fill:#FF6347,stroke:#333 style E fill:#DC143C,stroke:#333 style F fill:#8B0000,stroke:#333
关键里程碑
- GPT-1(2018)
OpenAI发布了首个GPT模型,采用了“预训练+微调”的架构,使用了12层Transformer解码器,在GLUE基准测试中提升了8.4%。 - GPT-2(2019年):在GPT-1的基础上,GPT-2的参数规模扩大到15亿,使用了大规模网页数据集WebText进行预训练。
- GPT-3(2020)
GPT-3的参数规模进一步扩大,达到了1750亿,能够处理更复杂的任务,如代码生成等。 - ChatGPT(2022)
基于GPT-3.5,ChatGPT引入了基于人类反馈的强化学习(RLHF),使模型在对话生成和文本理解方面表现出色。 - GPT-4(2023)
GPT-4在参数规模和多模态能力上都有所提升,能够处理图文联合输入,并在多个基准测试中表现出色。在BAR考试中超越90%考生,MMLU综合测试准确率达86.4%。
3.2 核心技术创新
3.2.1 注意力机制优化
GPT-4采用稀疏注意力(Sparse Attention),将计算复杂度从O(n²)降至O(n√n)。在处理32k tokens长文本时,推理速度提升3倍10。
3.2.2 训练数据工程
GPT-4在训练数据的质量和多样性上进行了优化,包括质量过滤、多语言平衡和知识时效性更新,解决了GPT-3知识截止的问题。
3.3.3 安全对齐机制
GPT-4引入了红队测试、可解释性工具和输出校准等安全对齐机制,确保模型输出符合人类价值观,减少有害内容的生成。
4. 挑战与未来方向
4.1 现存技术瓶颈
尽管生成式AI取得了显著进展,但仍面临语义鸿沟、推理局限性和能耗问题等挑战。GPT-4在多步逻辑推理方面取得了显著进展,但在处理更复杂的任务时仍面临挑战。随着技术的不断发展,未来的模型有望在这些领域取得更大的突破。
4.2 前沿探索方向
未来的研究方向包括神经符号结合、世界模型构建和绿色AI技术等。神经符号结合(Neuro-Symbolic AI)旨在将深度学习的强大表示学习能力与符号推理的逻辑性相结合,以提升模型的推理能力和可解释性。这一方法通过融合神经网络和符号逻辑,旨在弥补两者各自的不足,推动人工智能向更高层次的认知能力发展。
例如,神经符号学方法尝试将符号和深度学习方法结合起来,通过神经网络连接感官处理非结构化数据,通过符号方法实现推理,最终向高级认知功能推进。
此外,神经符号结合的研究方向包括:
- 神经符号集成:将神经网络和符号推理机制有效结合,实现更强大的推理能力。
- 知识表示与嵌入:通过神经网络学习符号知识的表示,提升模型对复杂知识的理解和推理能力。
- 功能性:开发能够处理多种任务的神经符号系统,如视觉推理、语言理解等。
这些研究方向旨在克服传统神经网络在推理和可解释性方面的局限性,推动人工智能向更高层次的认知能力发展。

