大家好,今天我们来聊点AI相关的话题。
现在,几乎每个人手上都攥着一个 AI 项目。每天睁眼,朋友圈、新闻推送、开会讨论,全是“又一项技术突破”“又一款新模型上线”——AI 正在飞奔,而我们的世界似乎也跟着加速重构。
还记得几年前大家还在围观“大模型”刷榜,如今各大厂商已经开始一波接一波地发布“颠覆世界”的产品。我们像是被卷进了一场技术飙车赛,踩着油门一路狂飙。前不久阅读了李飞飞的《我看见的世界》,她在书里反复强调:“科技的终极意义,是服务于人类,而非取代人类。”她从不把 AI 看成冷冰冰的算力堆叠,而是一种更温柔的连接——延伸我们的智慧,承载我们的善意。但看看当下,那些关于“人类共生”“伦理边界”的讨论,正在被“落地场景”“能力突破”的热潮一点点挤掉。
没人想停下来,大家都在争当那个“第一个改写规则”的人。在这个时候,作为技术人,我们必须时刻提醒自己:别只顾着追风口,也要看清风往哪儿吹。在 AI 疯狂生长的时代,保持清醒,比跟风狂热更稀缺。
回到现实操作层面。到了 2025 年,搭建 app 的方式,已经和以前大不一样了。曾经我们要花大把时间做 UI、拼组件、调样式,追求像素级的对齐和完美。而现在,有了模型上下文协议(MCP),这一切都变了。
接下来这篇文章,我会带你快速搞懂什么是 MCP,还会手把手教你——怎么用“零代码”的方式,搭建出属于自己的 MCP 服务。不讲虚的,咱们直接实战,边看边做,感受一下什么叫做真正的开发范式革命。
MCP是什么
MCP[1] 是由 Anthropic 于 2024 年推出的开放标准协议,旨在简化 AI 代理与外部工具和数据源的连接。可以把 MCP 想象成 AI 应用的 USB-C 接口。就像 USB-C 为你的设备与各种外设和配件提供了一种标准连接方式一样,MCP 为将 AI 模型与不同的数据源和工具连接起来提供了一种标准化方案。
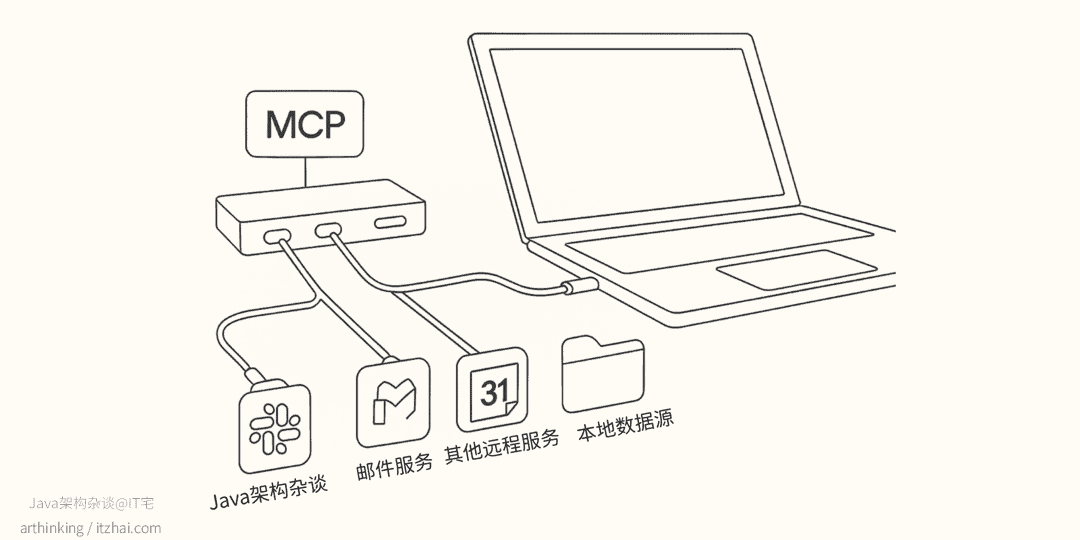
它为 AI 代理提供了一个标准化的接口,使其能够直接与应用程序的 API 进行交互,而无需传统的前端界面。通过 MCP,AI 代理可以像调用本地函数一样调用远程 API,实现功能的编排和自动化。
MCP架构
如下图,在其核心部分,MCP 遵循经典的客户端-服务器架构,允许一个主程序连接多个 MCP 服务:
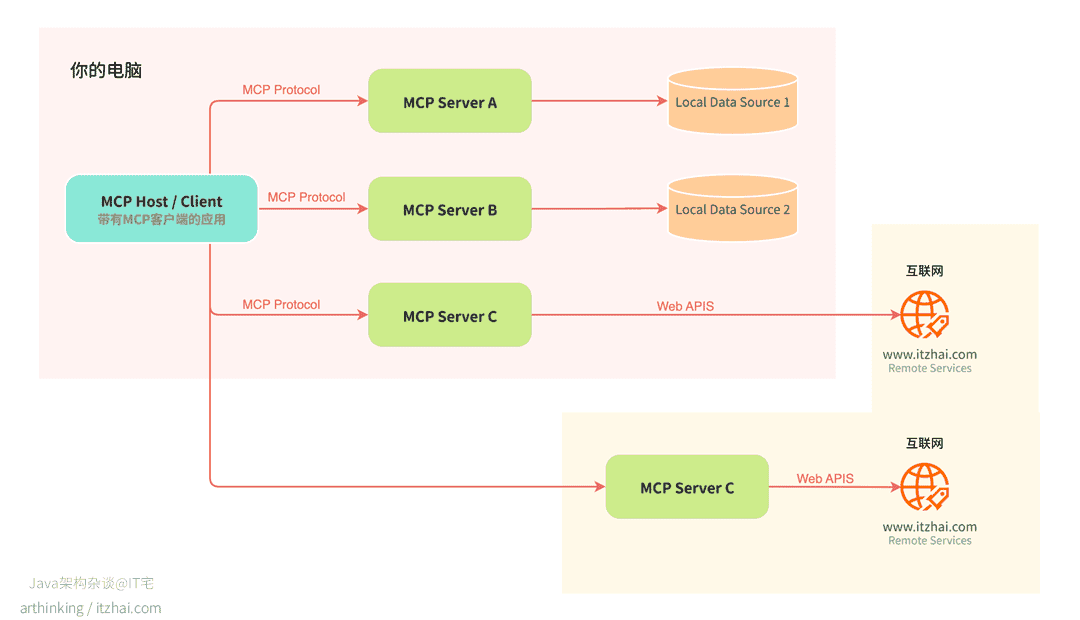
在 MCP 架构中,三种核心角色分别是 MCP Host、MCP Client 和 MCP Server,它们协同配合,为 AI 应用提供模块化、高可控的上下文交互能力:
MCP Host(主控程序)
MCP Host 是 AI 应用的“大脑”,比如 Cursor、IDE 插件或其他 AI 工具都可以视为一个 Host。它负责:
- 管理多个 MCP Client 的生命周期与连接权限;
- 协调上下文数据的聚合与采样;
- 执行安全策略与用户权限控制;
- 集成和调度多个 AI/LLM 服务资源。
Host 相当于容器和调度器,掌控全局资源和行为策略。
MCP Client(客户端)
每个 MCP Client 嵌入在 Host 中,用于与某个 MCP Server 建立一对一的通信连接,职责包括:
- 建立并维护安全、隔离的连接;
- 协商协议与能力;
- 路由消息,实现双向通信;
- 处理订阅、通知机制;
- 保持客户端与各个 Server 间的安全边界。
它相当于 Host 和 Server 之间的“中介”,是协议与功能的桥梁。
MCP Server(服务端)
MCP Server 是具体功能的提供者,它们可以部署在本地或远程,职责包括:
- 向 Host 暴露可用资源、工具和提示能力;
- 接收请求并执行采样;
- 管理自身的上下文状态;
- 遵守来自 Host 的安全与权限控制策略。
每个 MCP Server 独立运行,按职责划分清晰,能够专注于特定领域(如搜索、插件功能、内容生成等)。
数据来源类型
MCP Server 可访问的资源分为以下两种:
- 本地数据源:如文件系统、SQLite 数据库、本机索引库等,由 MCP Server 直接访问;
- 远程服务:如通过 API 访问的第三方服务、部署在云端的自建 MCP 服务等。
这种灵活的资源访问机制,使得 MCP 架构能够在安全边界内统一本地与远程的上下文调用体验。
MCP通信机制
在 MCP 中,客户端与服务器之间的通信流程 通常采用 JSON-RPC 协议,该协议具有良好的可扩展性与语言无关性,便于集成。
为满足不同部署需求,MCP 支持多种传输机制(Transport Mechanisms):
- Stdio(标准输入/输出):适用于本地服务进程间的通信,具备低延迟、高性能的特点;
- HTTP + Server-Sent Events(SSE):用于远程通信场景,可实现服务器向客户端推送事件,适合状态更新和异步通知。
MCP 协议定义了以下几类核心消息类型(Message Types):
- Request(请求):客户端向服务器发起操作调用,期望收到响应;
- Result(结果):对请求的成功响应,携带返回数据;
- Error(错误):请求执行失败时的错误信息;
- Notification(通知):单向消息,无需响应,常用于状态变更通知等场景。
MCP工作流程
MCP工作流程如下:
- Host 启动时会初始化一组 MCP Client,并与配置的多台 MCP Server 分别建立连接。
- 每个 Client–Server 对会协商可用功能(标签为 Tools、Resources、Prompts 等)。
- 当用户通过 Host(如自然语言指令)触发操作时,真正在做工作的并非传统前端,而是 Host 引导 LLM 调用某个 MCP Client,这个是关键,直接影响了我们AI产品交互设计的范式。
- 该 Client 再通过 JSON-RPC 等方式通知对应的 MCP Server 执行动作(如读取文件、调用 API)。
- Server 执行后将结果返回给 Client,最终 Host/LLM 使用这些结果进行进一步处理。
为什么要使用MCP?
随着开发者不断探索扩展大型语言模型(LLM)能力的方式。在传统架构下,AI 要想调用外部服务,通常需要开发者为每一个工具或数据源手写适配层:定义专用的客户端 SDK、封装 HTTP 请求、解析响应格式,再把这些代码“硬编码”进代理或应用逻辑中。这种方式不仅开发成本高,而且一旦服务端接口有变,就要逐一排查和修改适配层,维护难度极大,也难以在运行时动态扩展新功能。
为了满足这个需求,OpenAI 退出了函数调用(Function Calling)。它允许 LLM 基于用户输入识别出需要调用的外部函数或 API,并自动构造对应的调用参数。其他大模型也陆续推出了Function Calling。运行原理如下图:
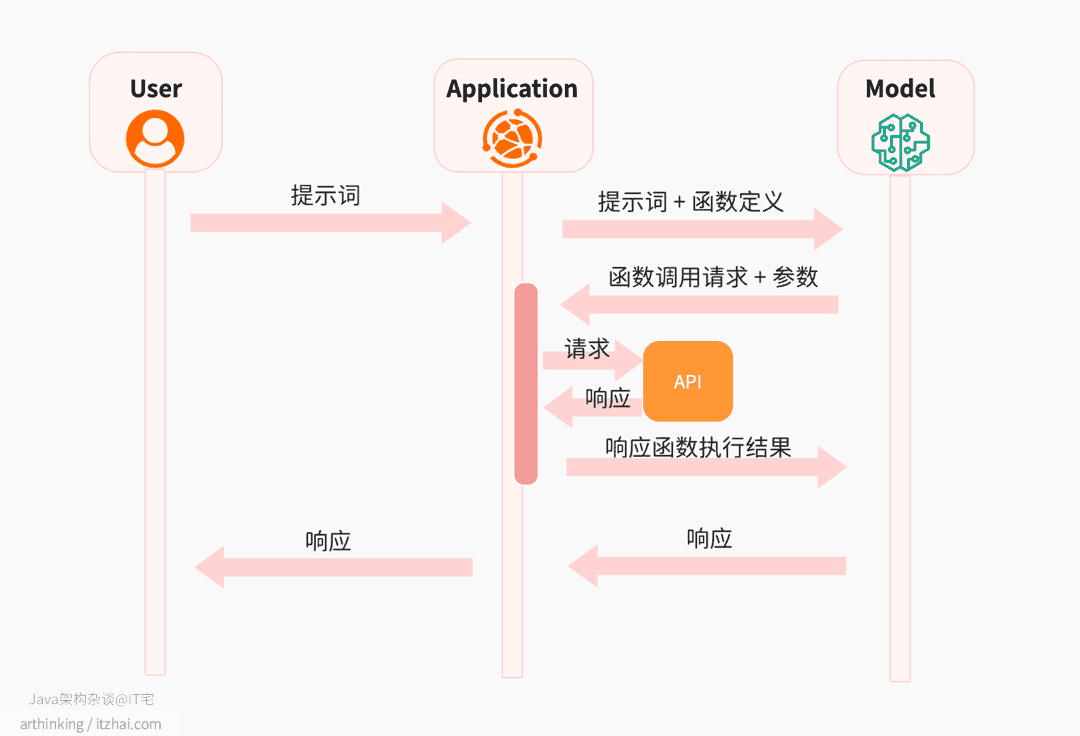
- 向 LLM 提交提示时,应用程序还需要向模型提供一组工具,以便模型可以使用这些工具来响应用户提示。例如,可以提供一个函数
get_weather,该函数接受一个位置参数,并返回该位置的天气状况信息。 - 处理提示时,该模型可以选择将某些数据处理任务委托给您确定的函数。模型不会直接调用函数。相反,模型会提供结构化数据输出,其中包含要调用的函数和要使用的参数值。例如,对于提示
深圳的天气怎样?,模型可以将处理委托给get_weather函数,并提供位置参数值深圳。 - 然后应用程序使用模型的结构化输出来调用外部 API。例如,应用程序可以连接到天气服务 API,提供位置
深圳,并接收有关温度、云量和风况的信息。 - 然后,将 API 输出返回给模型,使模型能够完成对提示的回答。对于天气示例,模型可能会提供以下回答:
今天深圳天气26℃,受台风影响有中雨。
以上就是函数调用的大致的运行原理。注意这里函数调用都是在应用程序侧发起的,大模型只告知应用程序要调用某个函数,以及调用某个函数的完整请求参数,然后等待获取函数执行结果:
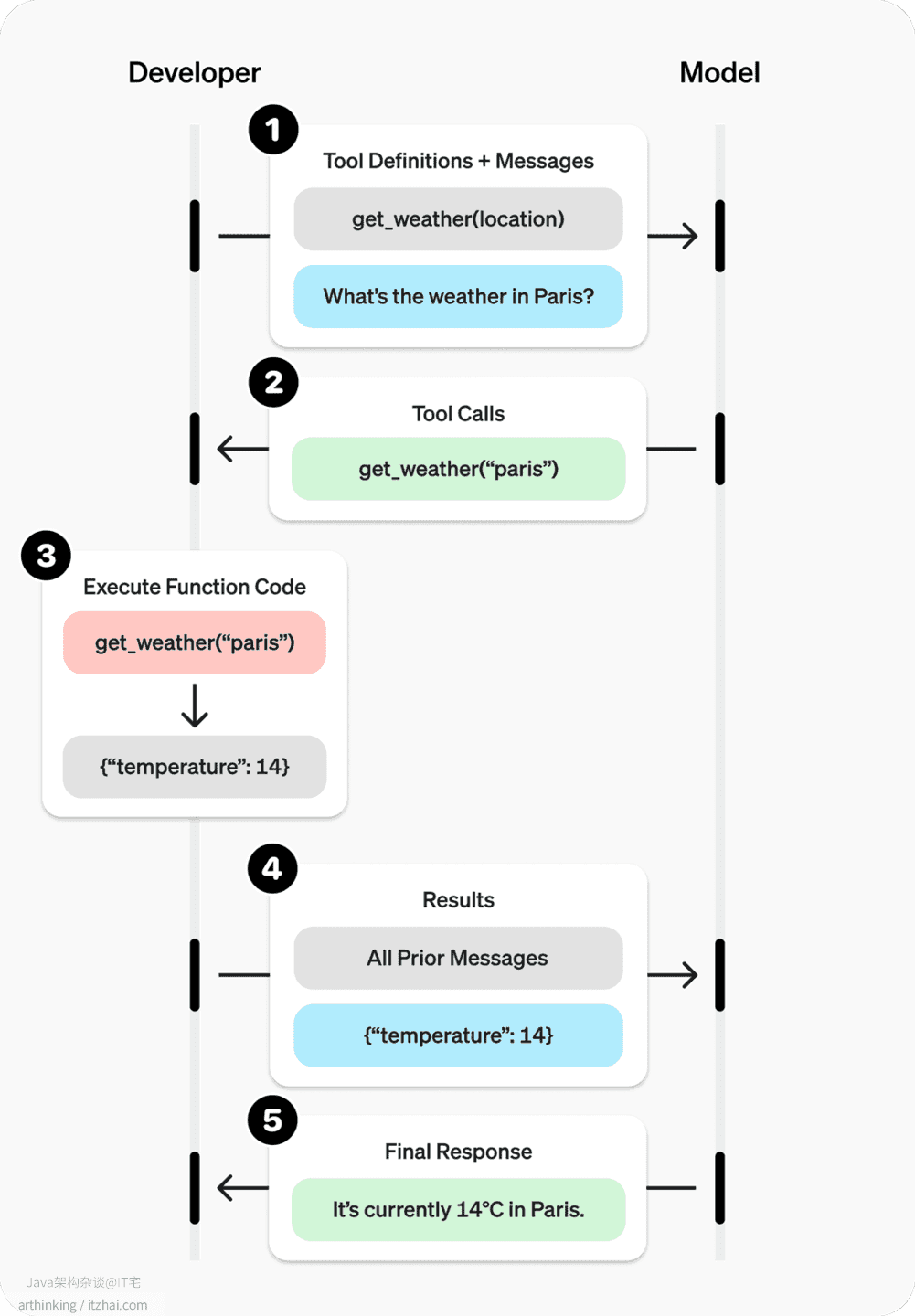
OpenAI 的函数调用功能主要旨在使 LLM 能够将用户的提示转换为结构化的 API 调用。它允许模型确定应调用哪个函数以及使用哪些参数,从而实现与外部服务的交互。
相比之下,MCP 是一个更广义的协议,它标准化了 LLM 应用程序与外部系统之间整个执行和交互的流程。它不仅处理用户意图的翻译,还提供了一套结构化的框架,用于工具发现、调用以及响应处理。
引入 MCP 之后,AI 与服务的整合变得高度模块化:每个服务只需实现一套遵循 MCP 规范的轻量级“服务器”,暴露标准化的方法(Tool)、资源(Resource)或提示(Prompt)。AI 代理启动时,通过统一的协议(通常是 JSON-RPC over STDIO/HTTP/SSE)即刻发现并调用这些 MCP 服务器,无需额外编写对接代码。这样,新增或替换任何一个后端工具,只要部署对应的 MCP 服务,AI 即可“即插即用”,真正实现了服务调用与业务逻辑的彻底解耦。
大型语言模型(LLM)常常需要与数据源和工具进行集成,而 MCP 则提供了一种标准化的方式来实现这一点:
- 不断丰富的预构建集成,你的 LLM 可以直接接入使用
- 灵活切换不同 LLM 提供商和厂商
- 确保数据安全的最佳实践,在你的基础设施中保护敏感信息
这种方式改变了我们构建应用程序的方式。我们不再需要构建传统的前端界面,而是将应用程序的功能通过 API 暴露出来,供 AI 代理调用。开发者的角色从构建用户界面转变为设计功能模块和能力接口,AI 代理则负责根据用户的自然语言指令调用相应的功能模块。
快速上手搭建一个MCP
举个栗子:要做 Java 代码规范检查和自动格式化,以前我们总是这样操作,得在本地或者 CI 上各自安装、配置 Checkstyle、PMD、Spotless 这些工具,还得手敲一大堆 XML 或者写 Gradle 插件配置,每次规范更新了又要挨个项目去同步,团队小伙伴还得背一堆命名、缩进、注释的约定。结果呢?动不动 review 卡住、返工一堆,真是既耗时间又让人心烦。
但有了 MCP,就轻松多了。我们把 Checkstyle 的校验接口、Spotless 的格式化接口、PMD 的静态分析接口这些工具,直接统一托管在 MCP 服务器上。你只需要对 AI 代理说一句:“帮我按照最新的 Google Java 风格检查刚提交的模块”,或者“把这段代码格式化成我们团队的规范”,它就自动去调用对应的 API,给你跑检查、格式化、生成报告。一气呵成,根本不用再理那些配置文件。
这样一来,开发者就能把精力放回到核心业务上,自然不用再为集成工具链和维护配置头疼;AI 代理根据上下文还能智能挑选最合适的规范规则,支持按项目或团队自由定制,还会实时给出修改建议。代码风格一致了,协作也顺畅了,团队效率一下就上来了。
接下来我们就来实现这样的一个功能。
基于约定的代码规范书写代码
现在我们要让AI基于我们约定的代码规范进行书写代码,我们只需要设计这样一个提供代码规范的MCP服务器就可以了,不管什么AI,只要遵循MCP规范,就可以按照这个规范进行编码了。
为了方便演示,以快速实现这个功能,我们可以借助Postman。
Postman 提供了一个强大的工具,帮助开发者快速生成 MCP 服务器。通过 Postman 的 MCP Generator,开发者可以从 API 文档中自动生成 MCP 服务器代码,极大地提高了开发效率。
如下图,在Postman的API Network面板下,有一个MCP Generator的功能:
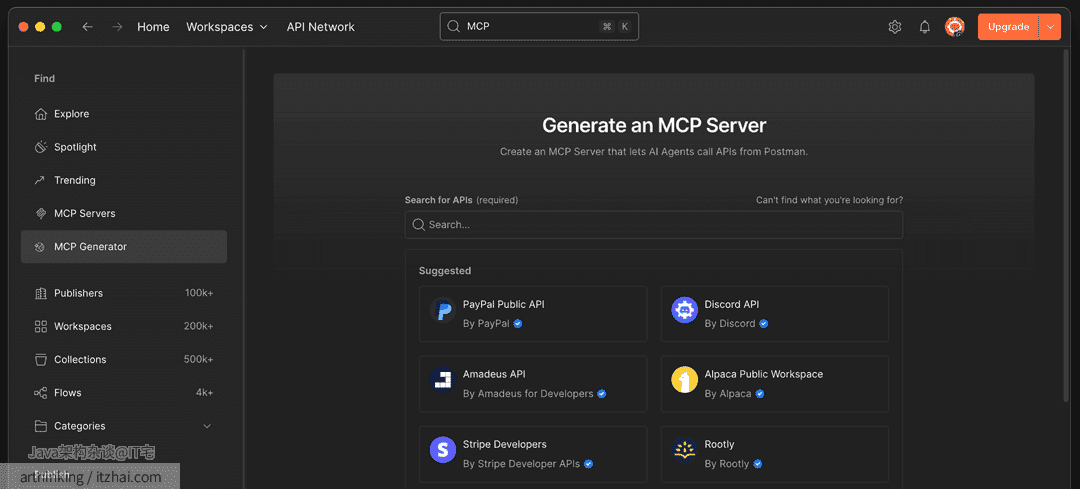
我们找到自己的Java代码规范的接口:
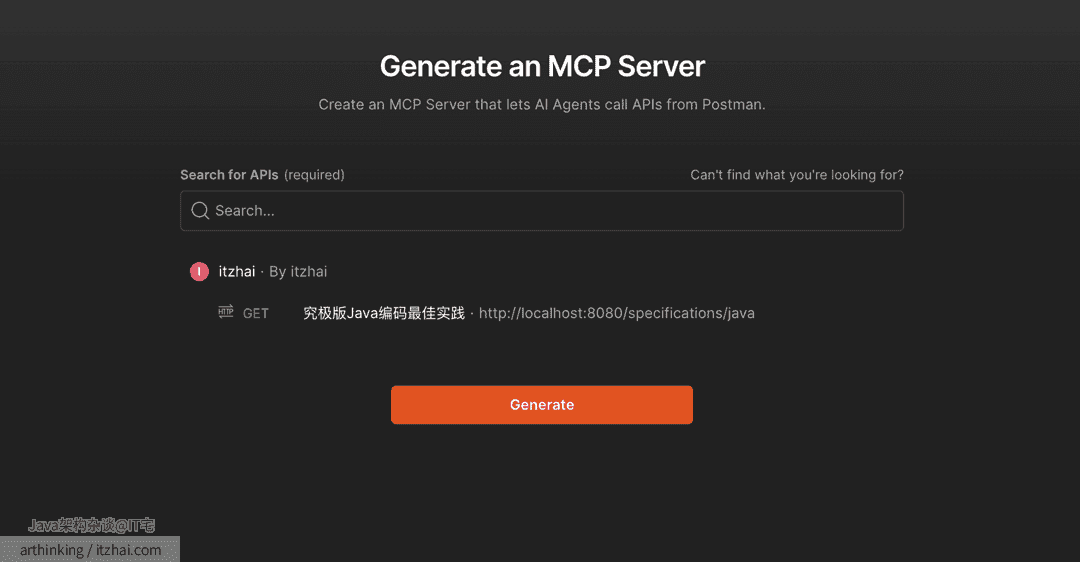
这里的接口是我本地提供的一个接口,提供了一些很标准的代码书写规范:
1 |
|
然后让Postman生成一个MCP服务端程序:
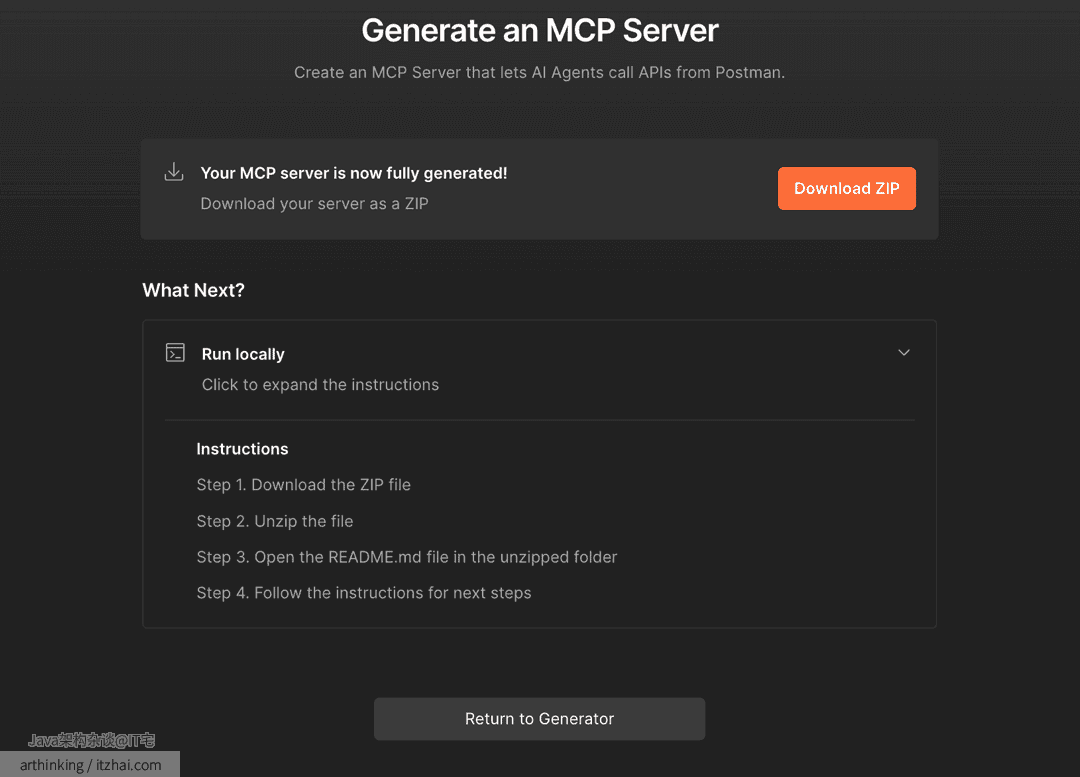
然后按照步骤进行下载配置即可。主要就是解压压缩包,进入目录执行 npm install,如果配置了接口鉴权,则按照文档配置鉴权秘钥。
你可以将你的 MCP 服务器连接到任意 MCP 客户端。比如将其连接到 Cursor 中,可以按照如下方式操作:
打开 Cursor → 首选项 → Cursor Settings → Tools & Integrations,添加一个新的 MCP 服务器配置项:
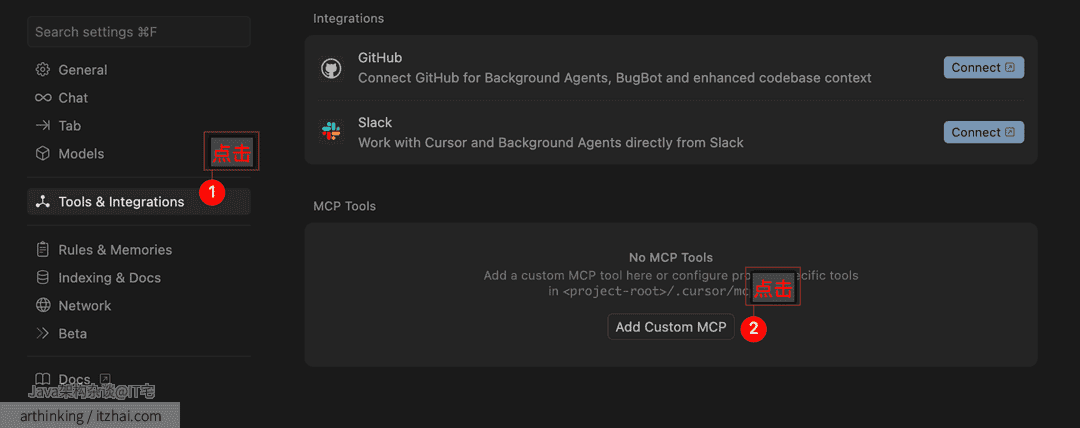
1 | { |
这里的command是你的node的目录,可以执行 which node 获取目录。
这里的 mcpServer.js 是刚刚下载的MCP Server 压缩包里面的文件,使用其绝对路径即可。比如我的:
1 | { |
确保新添加的 MCP 服务器已启用,并且旁边显示绿色圆点。如果一切正常,你就可以开启一个可以使用该工具的对话了。
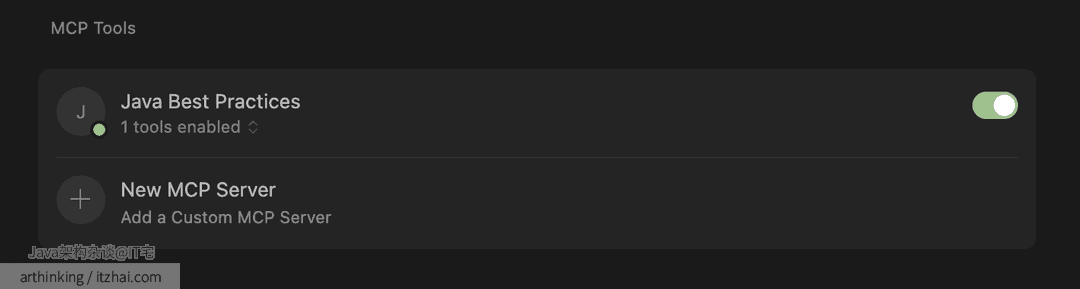
就这么简单。
下面演示下:
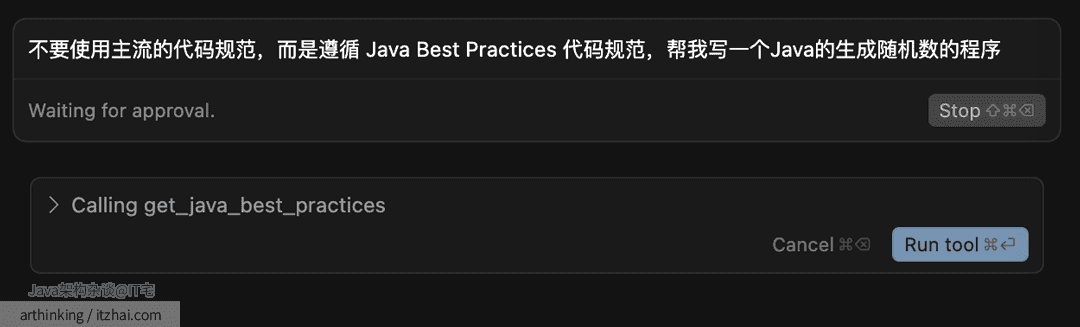
结果生成了如下的代码:
1 | // 禁止修改 |
嗯,是我想要的。
借助 Postman 的 MCP Generator,我们现在可以轻松把现有 API 封装成 MCP Server,让 AI 代理直接调用,开发效率一下子就拉满。
听起来是不是很香?确实香。但如果你已经迫不及待地准备上线,我劝你一句——先别急,得把安全的坑填好再说。
首先,API 的访问安全和权限控制,绝对是第一优先级。别被“AI 代理”这个词唬住,它背后可能是未授权的爬虫,也可能是没做鉴权的野路子请求。我就见过团队为了图省事,把内部接口直接暴露在公网,只因为“自己人用方便”。问题是,一旦这接口开放给 MCP 客户端,那就是明牌给全世界看——后果你懂的,轻则数据外泄,重则系统出事。
接着说通信机制。AI 和 API 的互动节奏跟传统前后端不太一样,实时性强、调用频繁。如果你的接口没设计幂等性、没做超时重试,遇到高频请求就是灾难现场。我见过太多刚入行的同学写接口,稍微一超时就直接挂,既没兜底逻辑,也没日志留痕,只能靠猜测问题在哪。
最后,还有一点常被忽视但极其关键:API 的版本管理。没有明确版本策略的系统,前后端协作就像踩地雷,一个参数改动,整个链路都得重构。我之前专门写过一篇文章讲版本控制的细节,有兴趣的可以翻阅下。
如果你读完心里冒出一句“哇,原来可以这么干!”
那这篇文章就没白写。
如果你觉得这套方法未来真有戏——欢迎点个赞、转发给同行,也欢迎在评论区聊聊你对 MCP 的看法。你的项目有没有落地 MCP 的机会?我们一起来探讨下。
用代码参与这场智能重构革命吧~
关注Java架构杂谈,我们下篇文章见!👋

