我们知道,当用户发送一个http请求的时候,浏览的的版本信息也包含在了http请求信息中:
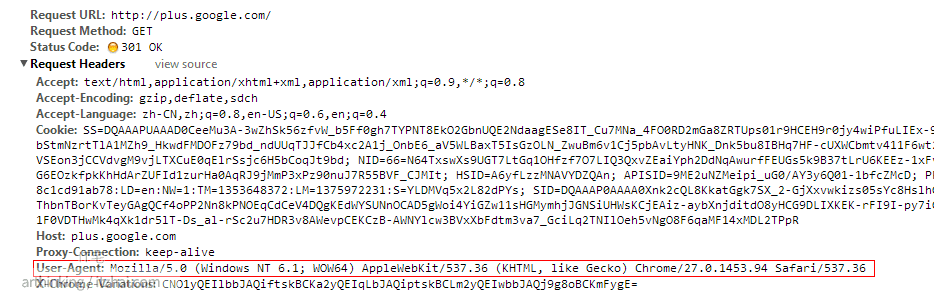
如上图所示,请求 google plus 请求头就包含了用户的浏览器信息:
User-Agent:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36
我们可以通过服务器端语言提供的相关API获取客户端的浏览器信息,进而对不同的浏览器返回不同的html文档,这样就可以针对现代浏览器返回绚丽的展示页面了。
而在Javascript中我们也提供了相关的API获取当前浏览器的信息:
navigator.userAgent
userAgent中提供给了浏览器将要发送给服务器端的http请求头中user-agent的信息。获取到这个信息之后我们可以通过正则匹配获取到浏览器和版本信息:
1 | //获取浏览器发送的userAgent信息 |
在PHP中也提供了相关的API:
strpos() 函数返回字符串在另一个字符串中第一次出现的位置。
如果没有找到该字符串,则返回 false。
$_SERVER 中存放着很多服务器的变量,其中
$_SERVER['HTTP_USER_AGENT'] #当前请求的 User_Agent: 头部的内容。
可以像下面这样判断请求者的浏览器和版本,注意,这里的版本可以是访问者伪造的,不一定正确。
1 |
|
此外还可以使用条件注释语句:
条件注释 (conditional comment) 是于HTML源码中被 Microsoft Internet Explorer 有条件解释的语句。条件注释可被用来向 Internet Explorer 提供及隐藏代码。
条件注释最初于微软的 Internet Explorer 5浏览器中出现,并且直至 Internet Explorer 9 均支持。[1]微软已宣布于 Internet Explorer 10 中以标准模式处理页面 - 如 HTML5 - 时停止支持,但是旧版网页使用这种技术(于兼容性视图)将继续有效。
1 | <!--[if !IE]><!--> 除IE外都可识别 <!--<![endif]--> |
网络爬虫的爬取问题
接下来可能会遇到的就是网络爬虫的爬取问题,我们应该给爬虫返回怎样的页面才能保证给爬虫提供的页面最适合于网站的SEO呢。其实爬虫请求头中的User-Agent也包含了特殊的标记信息,我们获取到该信息判断是否爬虫,然后返回最佳的SEO页面就可以了。
网络爬虫在发送http请求获取网页数据时也会在头部附加 User-Agent信息,特别注意的一点就是有些野蜘蛛 User-Agent信息为空,这样就需要在程序中做是否为空的判断,防止robots.txt 文件也对它的限制无效,导致不断的爬去你的网站。 可以向下面这样,判断到访问者的User-Agent为空,则返回404:
1 |
|
我们网站的流量主要是从哪几个搜索引擎获取的呢,这里是IT宅的的一份统计数据:
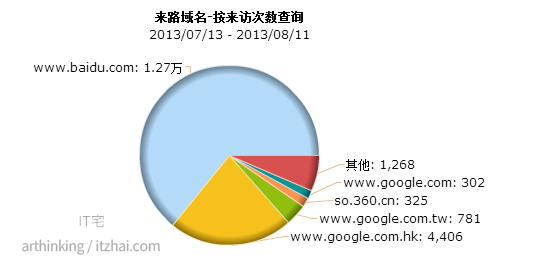
我们可以看到主要是来自以下几个搜索引擎:
下面是官方给出的一些user agent信息:
- 百度:http://www.baidu.com/search/spider.htm
- google:https://support.google.com/webmasters/answer/1061943
- 360:http://www.so.com/help/help_3_2.html
- soso:http://help.soso.com/webspider.htm
- sogou:http://www.sogou.com/docs/help/webmasters.htm#07
所以我们需要匹配的userAgent关键字如下:
Baiduspider Googlebot 360Spider Sosospider sogou spider
如下函数即可判断是否属于上面所列举的spider:
1 |
|
所以我们可以这样根据不同的访问用户提供不同的响应结果。
我们可以模拟一下百度的网络爬虫爬取数据,我们在Chrome中模拟一下:
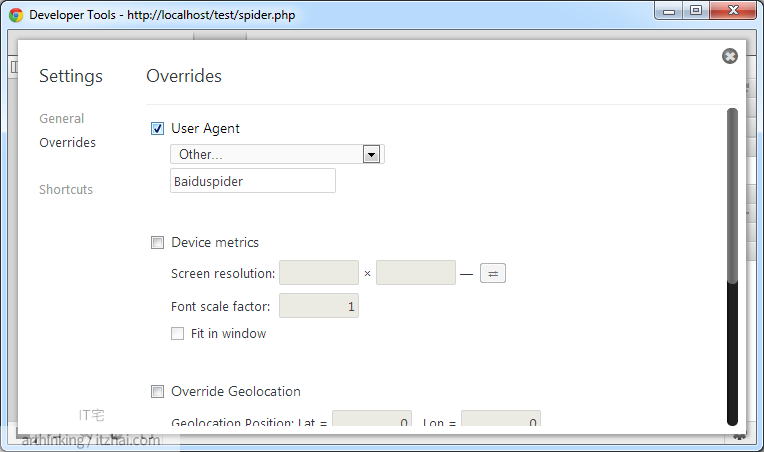
访问之后可以发现返回了需要的结果:


