

4、后缀数组 Suffix Array
后缀数组是后缀树的一种节省空间的替代方法,后缀树本身是trie的压缩版本。
后缀数组可以完成后缀树可以完成的所有工作,并且带有一些其他信息,例如最长公共前缀(LCP)数组
4.1、后缀数组格式
如下图,字符串:arthinking,所有的后缀,从长到短列出来:
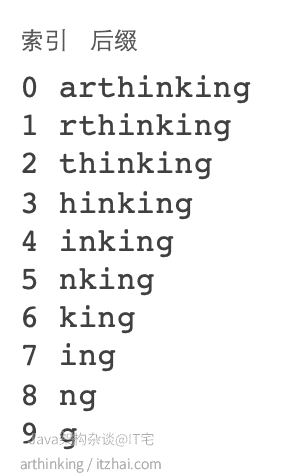
给后缀排序,排序后对应的索引构成的数组既是后缀数组:

后缀数组sa:后缀suffix列表排序后,suffix的下标构成的数组sa;
rank:suffix列表每个元素的排位权重(权重越大排越后面);
4.2、后缀数组构造过程
上面的后缀构造过程是怎样的呢?
这里我们介绍最常见的倍增算法来得到后缀数组。
我们获取每一个元素的权重rank,获取到之后,依次继续
- 第0轮:suffix[i] = suffix[i] + suffix[2^0],重新评估rank;
- 第1轮:suffix[i] = suffix[i] + suffix[2^1],重新评估rank;
- …
- 第n轮:suffix[i] = suffix[i] + suffix[2^n],重新评估rank;
- …
最终得到所有rank都不相等即可。如下图所示:
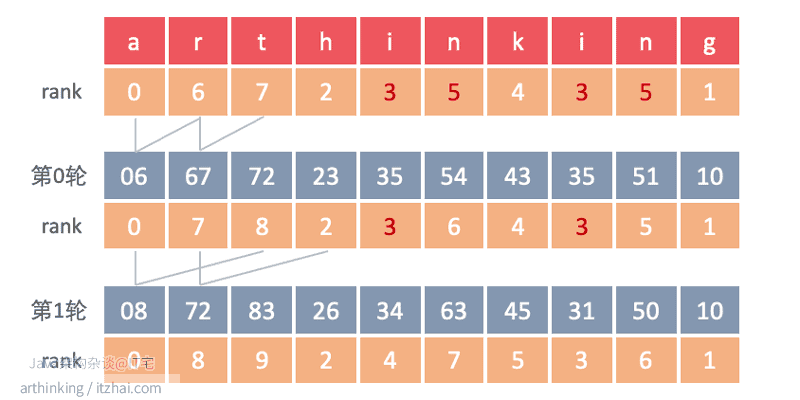
这样就得到rank了,我们可以根据rank很快推算出sa数组。
为什么可以这样倍增,跳过中间某些元素进行比较呢?
这是一种很巧妙的用法,因为每个后缀都与另一个后缀有一些共同之处,并不是随机字符串,迁移轮比较,为后续比较垫底了基础。
假设要处理
substr(i, len)子字符串。我们可以把第k轮substr(i, 2^k)看成是一个由substr(i, 2^k−1)和substr(i + 2^k−1, 2^k−1)拼起来的东西,而substr(i, 2^k−1)的字符串是上一轮比较过的并且得出了rank。
4.3、后缀数组使用场景
- 在较大的文本中查找子字符串的所有出现;
- 最长重复子串;
- 快速搜索确定子字符串是否出现在一段文本中;
- 多个字符串中最长的公共子字符串
- …
LCP数组
最长公共前缀(LCP longest common prefix)数组,是排好序的suffix数组,用来跟踪获取最长公共前缀(LCP longest common prefix)。

