

集群的扩容可以通过垂直扩容(增加集群硬件配置),或者通过水平扩容(分散数据到各个节点)来实现。切片集群属于水平扩容。
1、Redis Cluster方案
从Redis 3.0开始引入了Redis Cluster方案来搭建切片集群。
1.1、Redis Cluster原理
Redis Cluster集群的实现原理如下图所示:
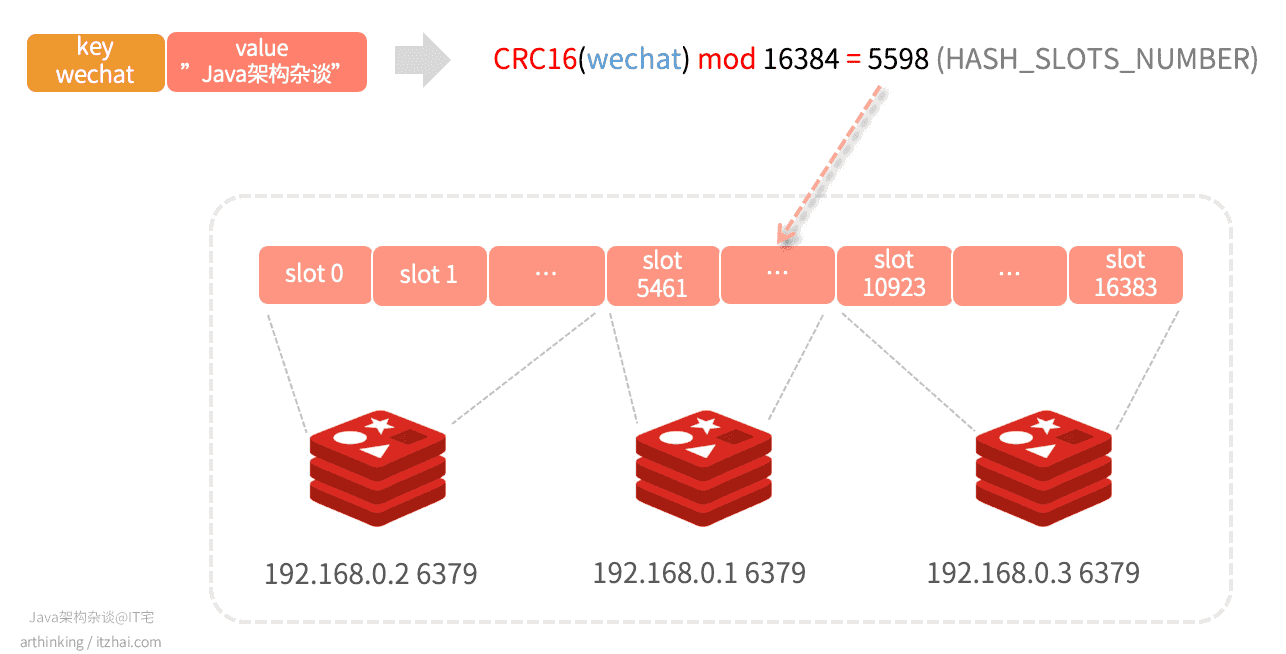
Redis Cluster不使用一致哈希,而是使用一种不同形式的分片,其中每个key从概念上讲都是我们称为哈希槽的一部分。
Redis集群中有16384个哈希槽,要计算给定key的哈希槽,我们只需对key的CRC16取模16384就可以了。
如上图,key为wechat,value为”Java架构杂谈“的键值对,经过计算后,最终得到5598,那么就会把数据落在编号为5598的这个slot,对应为 192.168.0.1 这个节点。
1.2、可以按预期工作的最小集群配置
以下是redis.conf最小的Redis群集配置:
1 | port 7000 # Redis实例端口 |
除此之外,最少需要配置3个Redis主节点,最少3个Redis从节点,每个主节点一个从节点,以实现最小的故障转移机制。
Redis的
utils/create-cluster文件是一个Bash脚本,可以运行直接帮我们在本地启动具有3个主节点和3个从节点的6节点群集。
注意:如果cluster-node-timeout设置的过小,每次主从切换的时候花的时间又比较长,那么就会导致主从切换不过来,最终导致集群挂掉。为此,cluster-node-timeout不能设置的过小。
如下图,是一个最小切片集群:
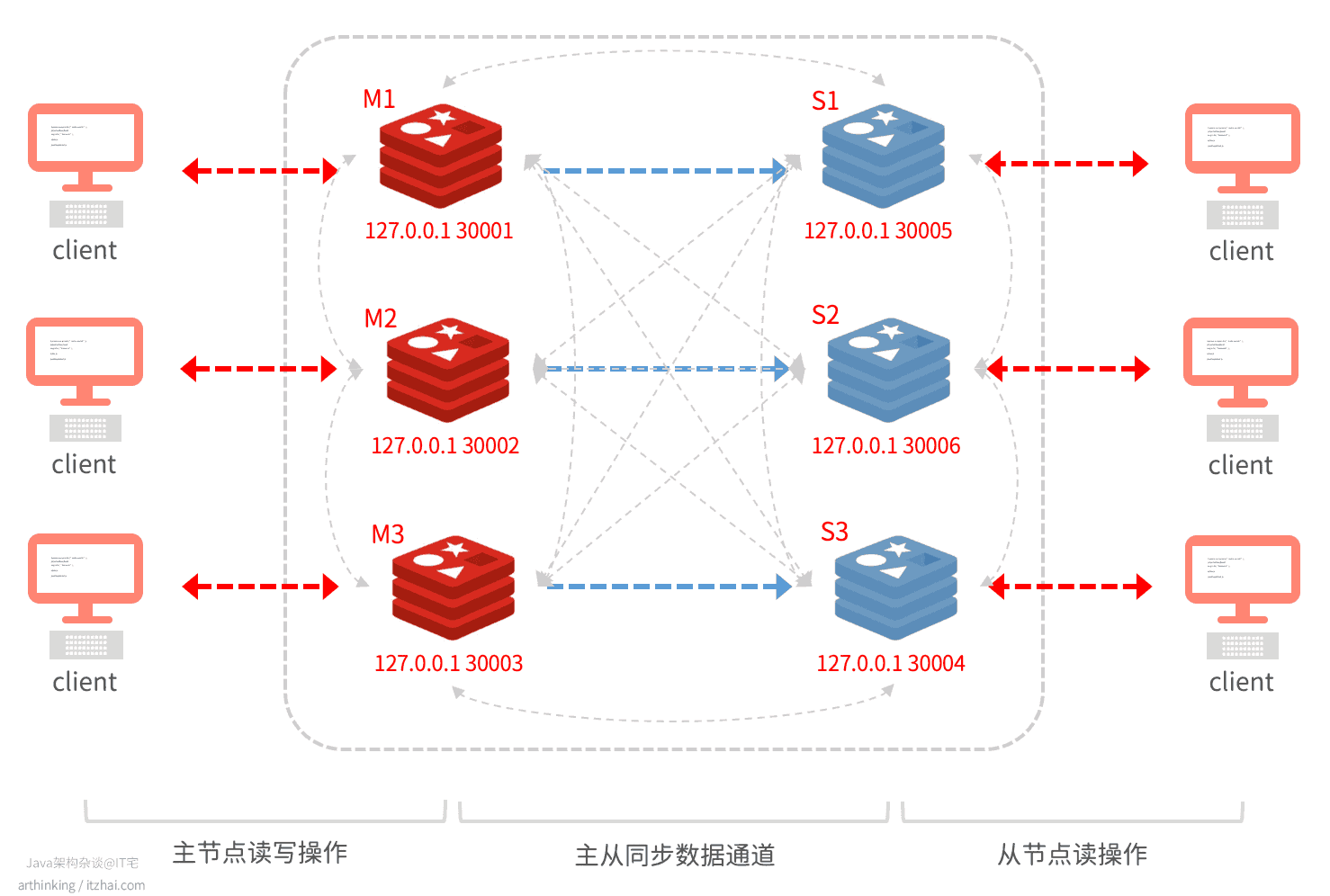
有三个主节点,三个从节点。
其中灰色虚线为节点间的通信,采用gossip协议。
可以通过create-cluster脚本在本地创建一个这样的集群:
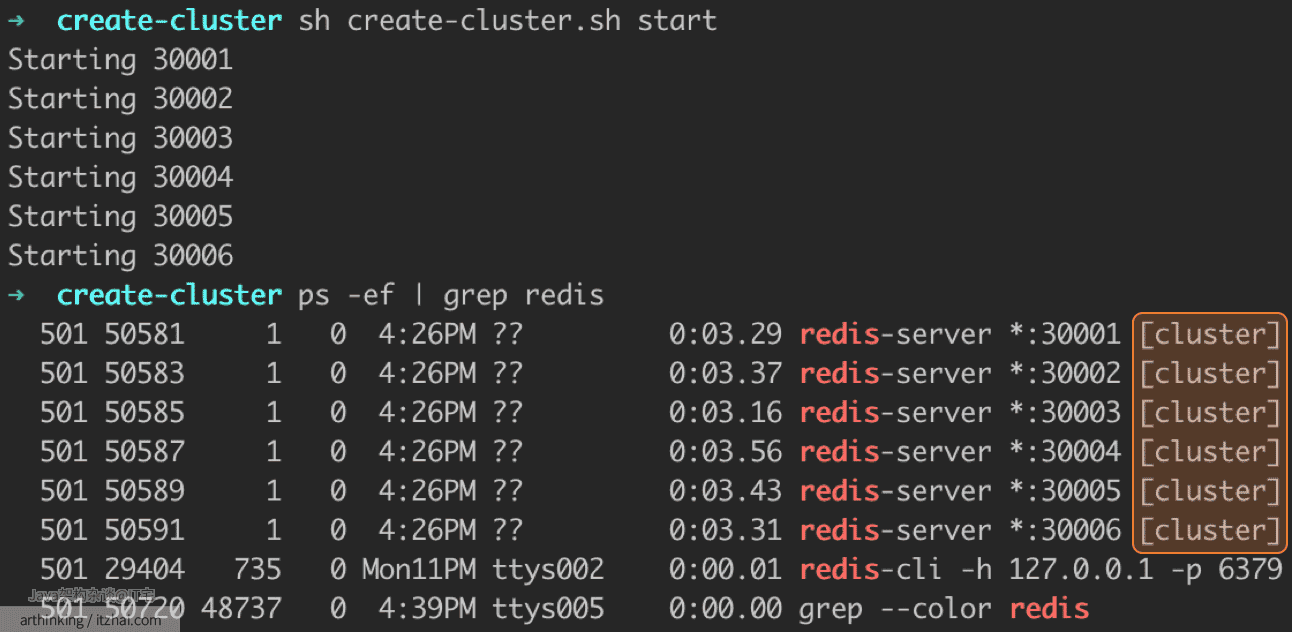
如上图,已经创建了6个以集群模式运行的节点。
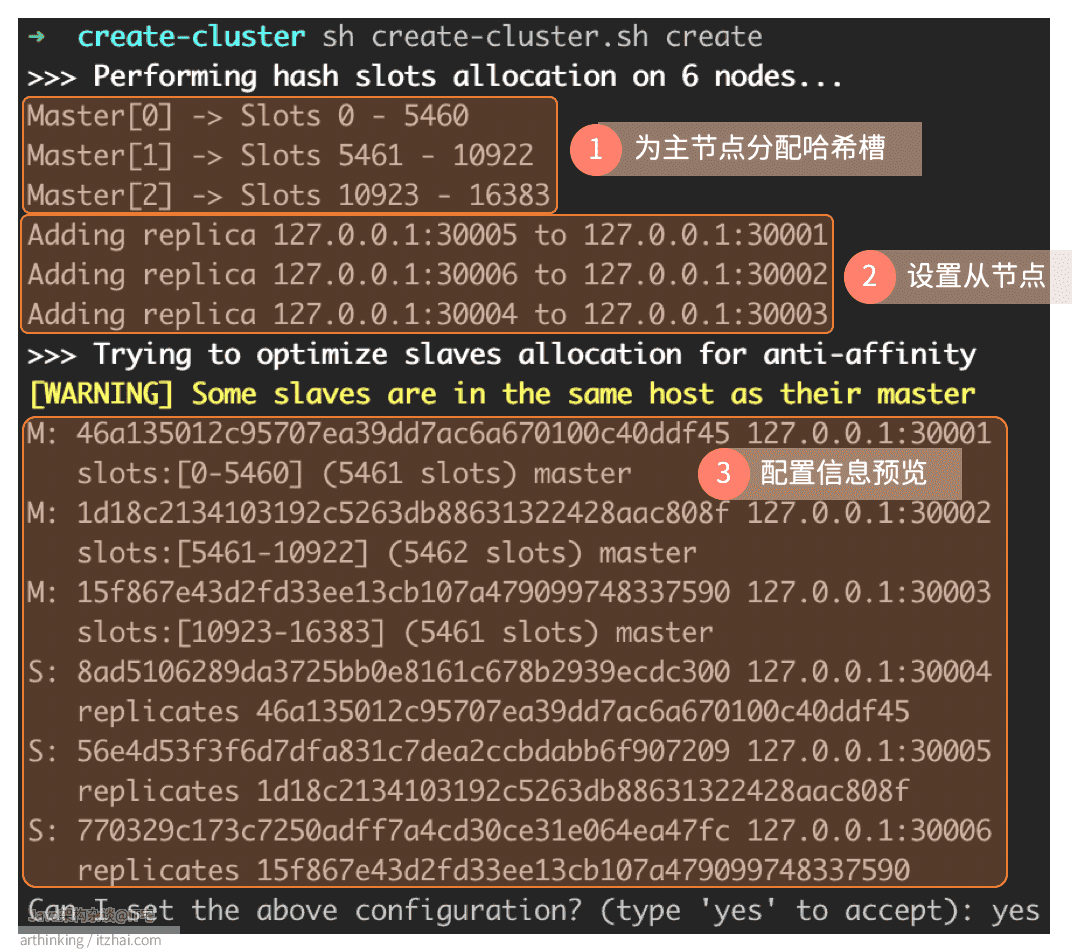
继续输入yes,就会按照配置信息进行集群的构建分配:
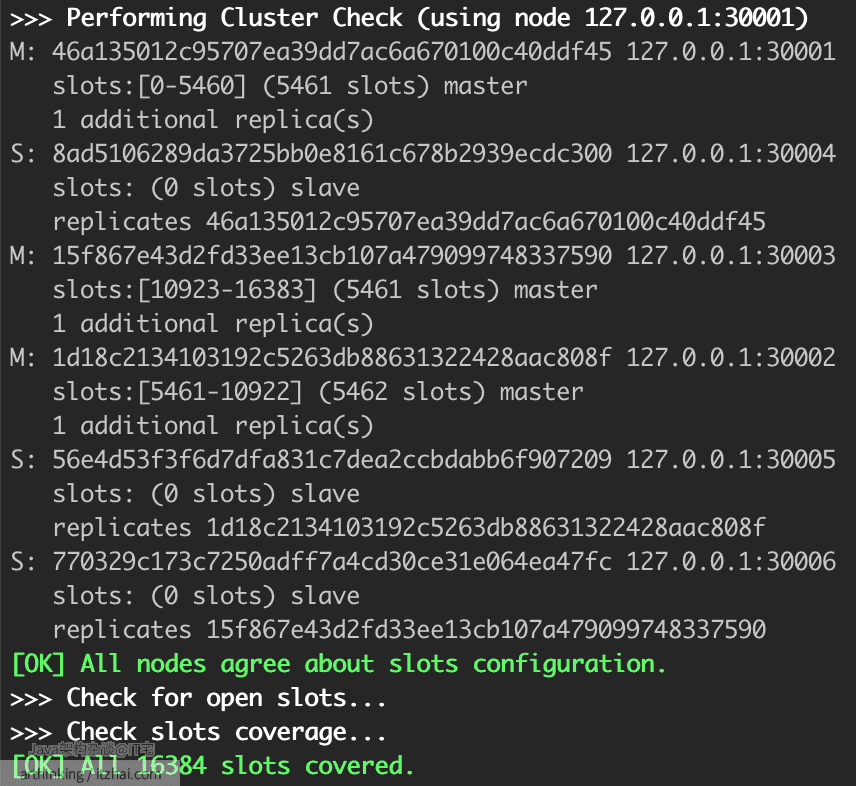
一切准备就绪,现在客户端就可以连上集群进行数据读写了:
1 | ➜ create-cluster redis-cli -p 30001 -c --raw # 连接到Redis集群 |
注意:-c,开启reidis cluster模式,连接redis cluster节点时候使用。
为了能让客户端能够在检索数据时通过Redis服务器返回的提示,跳转到正确的的节点,需要在redis-cli命令中添加-c参数。
1.3、客户端获取集群数据?
上一节的实例,可以知道,我们在客户端只是连接到了集群中的某一个Redis节点,然后就可以通信了。
但是想要访问的key,可能并不在当前连接的节点,于是,Redis提供了两个用于实现客户端定位数据的命令:
MOVED和ASK命令
这两个命令都实现了重定向功能,告知客户端要访问的key在哪个Redis节点,客户端可以通过命令信息进行重定向访问。
MOVED命令
我们先来看看MOVED命令,我们做如下操作:
1 | ➜ create-cluster redis-cli -p 30001--raw |
可以发现,终端打印了MOVED命令,比提供了重定向的IP和端口,这个是key对应的slot所在的Redis节点地址。我们只要通过集群模式连接Redis服务器,就可以看到重定向信息了:
1 | 127.0.0.1:30001> set qq "Java架构杂谈" |
MOVED命令的重定向流程如下:
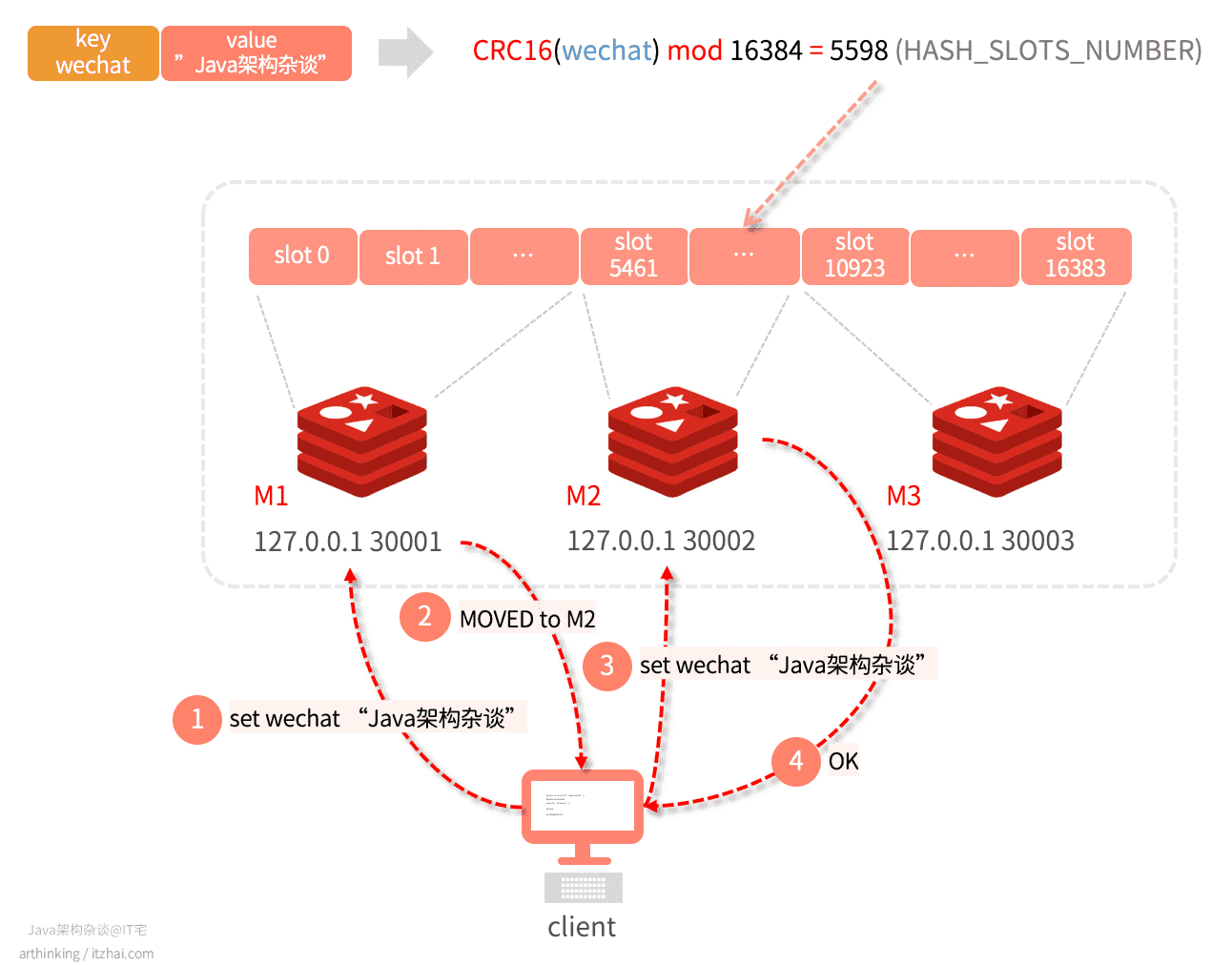
- 客户端连接到M1,准备执行:
set wechat "Java架构杂谈"; - wechat key执行CRC16取模后,为5598,M1响应MOVED命令,告知客户端,对应的slot在M2节点;
- 客户端拿到MOVED信息之后,可以重定向连接到M2节点,在发起set写命令;
- M2写成功,返回OK。
如果我们使用客户端的集群模式,就可以看到这个重定向过程了:
1 | 127.0.0.1:30001> set qq "Java架构杂谈" |
一般在实现客户端的时候,可以在客户端缓存slot与Redis节点的映射关系,当收到MOVED响应的时候,修改缓存中的映射关系。这样,客户端就可以基于已保存的映射关系,把请求发送到正确的节点上了,避免了重定向,提升请求效率。
ASK命令
如果M2节点的slot a中的key正在迁移到M1节点的slot中,但是还没有迁移完,这个时候我们的客户端连接M2节点,请求已经迁移到了M1节点部分的key,M2节点就会响应ASK命令,告知我们这些key已经移走了。如下图:

- slot 5642 正在从M2迁移到M1,其中
site:{info}:domain已经迁移到M1了; - 这个时候连接M2,尝试执行
get site:{info}:domain,则响应ASK,并提示key已经迁移到了M1; - 客户端收到ASK,则连接M1,尝试获取数据。
下面可以通过 hash_tag 演示一下迁移一个slot过程中,尝试get迁移的key,Redis服务器的响应内容:
1 | # 先通过hash_tag往M2节点的5642 slot写入三个key |
hash_tag:如果键中包含{},那么集群在计算哈希槽的时候只会使用{}中的内容,而不是整个键,{}内的内容称为hash_tag,这样就保证了不同的键都映射到相同的solot中,这通常用于Redis IO优化。
MOVED和ASK的区别
- MOVED相当于永久重定向,表示槽已经从一个节点转移到了另一个节点;
- ASK表示临时重定向,表示槽还在迁移过程中,但是要找的key已经迁移到了新节点,可以尝试到ASK提示的新节点中获取键值对。
1.4、Redis Cluster是如何实现故障转移的
Redis单机模式下是不支持自动故障转移的,需要Sentinel辅助。而Redis Cluster提供了内置的高可用支持,这一节我们就来看看Redis Cluster是如何通过内置的高可用特性来实现故障转移的。
我们再来回顾下这张图:
Redis节点之间的通信是通过Gossip算法实现的,Gossip是一个带冗余的容错,最终一致性的算法。节点之间完全对等,去中心化,而冗余通信会对网络带宽和CPU造成负载,所以也是有一定限制的。如上图的集群图灰色线条所示,各个节点都可以互相发送信息。
Redis在启动之后,会每间隔100ms执行一次集群的周期性函数clusterCron(),该函数里面又会调用clusterSendPing函数,用于将随机选择的节点信息加入到ping消息体中并发送出去。
如何判断主库下线了?
集群内部使用Gossip协议进行信息交换,常用的Gossip消息如下:
- MEET:用于邀请新节点加入集群,接收消息的节点会加入集群,然后新节点就会与集群中的其他节点进行周期性的ping pong消息交换;
- PING:每个节点都会频繁的给其他节点发送ping消息,其中包含了自己的状态和自己维护的集群元数据,和部分其他节点的元数据信息,用于检测节点是否在线,以及交换彼此状态信息;
- PONG:接收到meet和ping消息之后,则响应pong消息,结构类似PING消息;节点也可以向集群广播自己的pong消息,来通知整个集群自身运行状况;
- FAIL:节点PING不通某个节点,并且超过规定的时间后,会向集群广播一个fail消息,告知其他节点。
**疑似下线:**当节发现某个节没有在规定的时间内向发送PING消息的节点响应PONG,发送PING消息的节点就会把接收PING消息的节点标注为疑似下线状态(Probable Fail,Pfail)。
交换信息,判断下线状态:集群节点交换各自掌握的节点状态信息,交换之后,如果判断到超过半数的主节点都将某个主节点A判断为疑似下线,那么该主节点A就会标记为下线状态,并广播出去,所有接收到广播消息的节点都会立刻将主节点标记为fail。
疑似下线状态是有时效性的,如果超过了cluster-node-timeout *2的时间,疑似下线状态就会被忽略。
如何进行主从切换?
**拉票:**从节点发现自己所属的主节点已经下线时,就会向集群广播消息,请求其他具有投票权的主节点给自己投票;
最终,如果某个节点获得超过半数主节点的投票,就成功当选为新的主节点,这个时候会开始进行主从切换,
1.5、Redis Cluster能支持多大的集群?
我们知道Redis节点之间是通过Gossip来实现通信的,随着集群越来越大,内部的通信开销也会越来越大。Redis官方给出的Redis Cluster规模上限是1000个实例。更多关于Redis的集群规范:Redis Cluster Specification[1]
而在实际的业务场景中,建议根据业务模块不同,单独部署不同的Redis分片集群,方便管理。
如果我们把slot映射信息存储到第三方存储系统中,那么就可以避免Redis Cluster这样的集群内部网络通信开销了,而接下来介绍的Codis方案,则是采用这样的思路。
2、Codis方案
与Redis Cluster不同,Codis是一种中心化的Redis集群解决方案。
Codis是豌豆荚公司使用Go语言开发的一个分布式Redis解决方案。选用Go语言,同时保证了开发效率和应用性能。
对于Redis客户端来说,连接到Codis Proxy和连接原生的Redis没有太大的区别,Redis客户端请求统一由Codis Proxy转发给实际的Redis实例。
Codis实现了在线动态节点扩容缩容,不停机数据迁移,以及故障自动恢复功能。
中心化:通过一个中间层来访问目标节点
去中心化:客户端直接与目标节点进行访问。
以下是Codis的架构图:
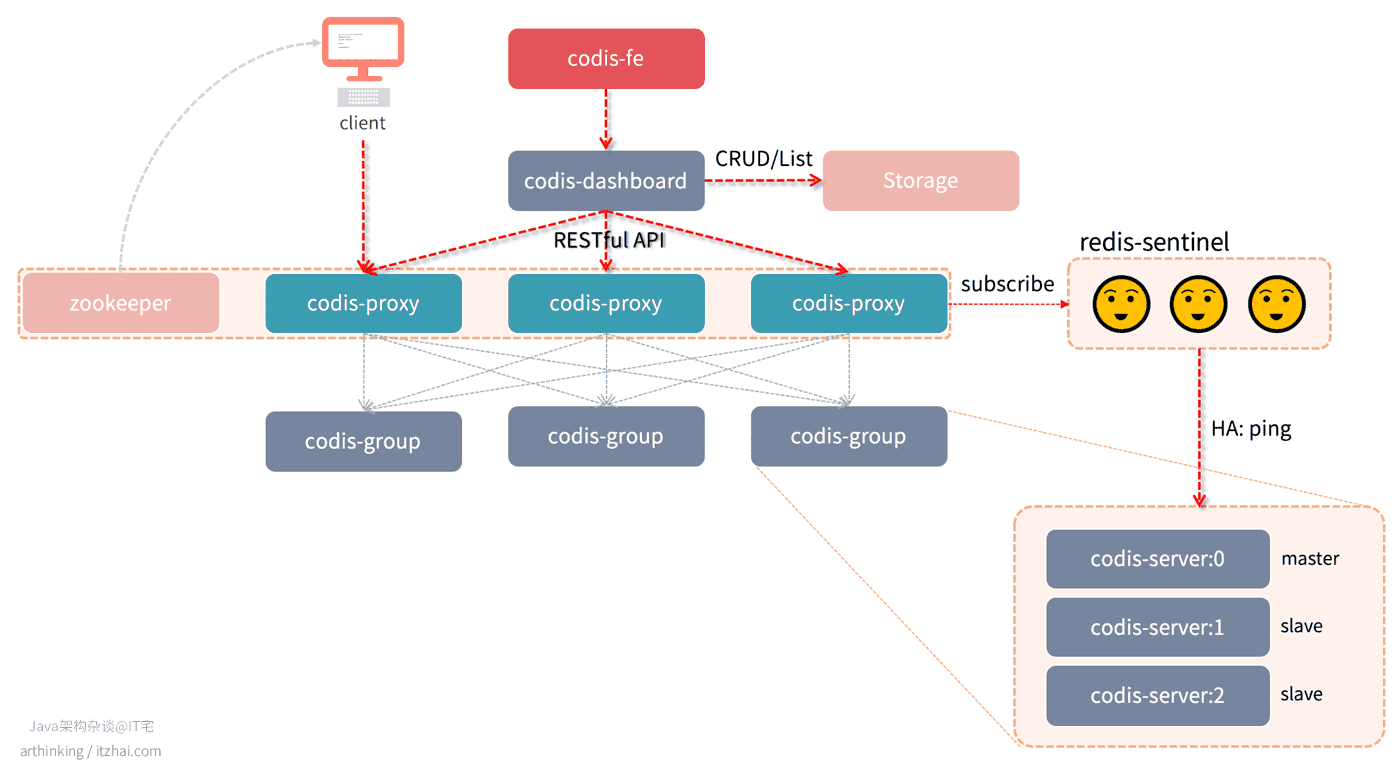
( 以下各个组件说明来自于Codis官方文档:Codis 使用文档[2] )
- Codis Server:基于 redis-3.2.8 分支开发。增加了额外的数据结构,以支持 slot 有关的操作以及数据迁移指令。具体的修改可以参考文档 redis 的修改。
- Codis Proxy:客户端连接的 Redis 代理服务, 实现了 Redis 协议。 客户端访问codis proxy时,和访问原生的Redis实例没有什么区别,方便原单机Redis快速迁移至Codis。除部分命令不支持以外(不支持的命令列表),表现的和原生的 Redis 没有区别(就像 Twemproxy)。
- 对于同一个业务集群而言,可以同时部署多个 codis-proxy 实例;
- 不同 codis-proxy 之间由 codis-dashboard 保证状态同步。
- Codis Dashboard:集群管理工具,支持 codis-proxy、codis-server 的添加、删除,以及据迁移等操作。在集群状态发生改变时,codis-dashboard 维护集群下所有 codis-proxy 的状态的一致性。
- 对于同一个业务集群而言,同一个时刻 codis-dashboard 只能有 0个或者1个;
- 所有对集群的修改都必须通过 codis-dashboard 完成。
- Codis Admin:集群管理的命令行工具。
- 可用于控制 codis-proxy、codis-dashboard 状态以及访问外部存储。
- Codis FE:集群管理界面。
- 多个集群实例共享可以共享同一个前端展示页面;
- 通过配置文件管理后端 codis-dashboard 列表,配置文件可自动更新。
- Storage:为集群状态提供外部存储。
- 提供 Namespace 概念,不同集群的会按照不同 product name 进行组织;
- 目前仅提供了 Zookeeper、Etcd、Fs 三种实现,但是提供了抽象的 interface 可自行扩展。
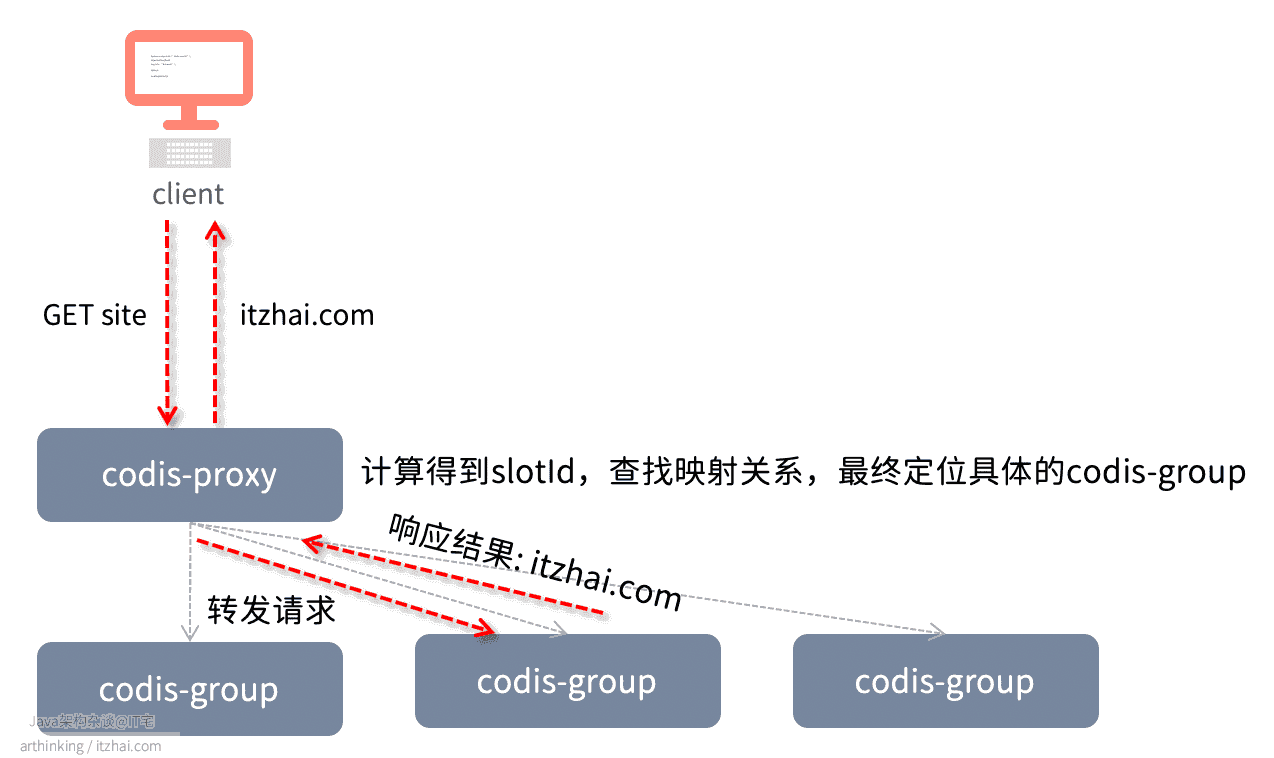
2.1、Codis如何分布与读写数据?
Codis采用Pre-sharding技术实现数据分片,默认分为1024个slot,通过crc32算法计算key的hash,然后对hash进行1024取模,得到slot,最终定位到具体的codis-server:
1 | slotId = crc32(key) % 1024 |
我们可以让dashboard自动分配这些slot到各个codis-server中,也可以手动分配。
slot和codis-server的映射关系最终会存储到Storage中,同时也会缓存在codis-proxy中。
以下是Codis执行一个GET请求的处理流程:
2.2、Codis如何保证可靠性
从以上架构图可以看出,codis-group中使用主从集群来保证codis-server的可靠性,通过哨兵监听,实现codis-server在codis-group内部的主从切换。
2.3、Codis如何实现在线扩容
扩容codis-proxy
我们直接启动新的codis-proxy,然后在codis-dashboard中把proxy加入集群就可以了。每当增加codis-proxy之后,zookeeper上就会有新的访问列表。客户端可以从zookeeper中读取proxy列表,通过特定的负载均衡算法,把请求发给proxy。
扩容codis-server
首先,启动新的codis-server,将新的server加入集群,然后把部分数据迁移到新的codis-server。
Codis会逐个迁移slot中的数据。
codis 2.0版本同步迁移性能差,不支持大key迁移。
不过codis 3.x版本中,做了优化,支持slot同步迁移、异步迁移和并发迁移,对key大小无任何限制,迁移性能大幅度提升。
同步迁移与异步迁移
-
同步迁移:数据从源server发送到目标server过程中,源server是阻塞的,无法处理新请求。
-
异步迁移:数据发送到目标server之后,就可以处理其他的请求了,并且迁移的数据会被设置为只读。
当目标server收到数据并保存到本地之后,会发送一个ACK给源server,此时源server才会把迁移的数据删除掉。

