

Redis的性能跟CPU也有关?没错。接下来看看NUMA陷阱对Redis性能的影响。
1、NUMA
NUMA(Non-Uniform Memory Access),非统一内存访问架构,为多处理器的电脑设计的内存架构,内存访问时间取决于内存相对于处理器的位置。
在NUMA下,处理器访问它自己的本地内存的速度比非本地内存(内存位于另一个处理器,或者是处理器之间共享的内存)快一些。
诞生背景
现代 CPU 的运行速度比它们使用的主内存快得多。在计算和数据处理的早期,CPU 通常比自己的内存运行得慢。
随着第一台超级计算机的出现,处理器和内存的性能线在 1960 年代出现了转折点。从那时起,CPU 越来越多地发现自己“数据匮乏”,不得不在等待数据从内存中到达时停止运行。1980 年代和 1990 年代的许多超级计算机设计专注于提供高速内存访问,而不是更快的处理器,使计算机能够以其他系统无法接近的速度处理大型数据集。
NUMA 尝试通过为每个处理器提供单独的内存来解决这个问题,避免在多个处理器尝试寻址同一内存。
NUMA架构解析
以下是NUMA架构图示:(图片来源:NUMA Deep Dive Part 2: System Architecture[1])
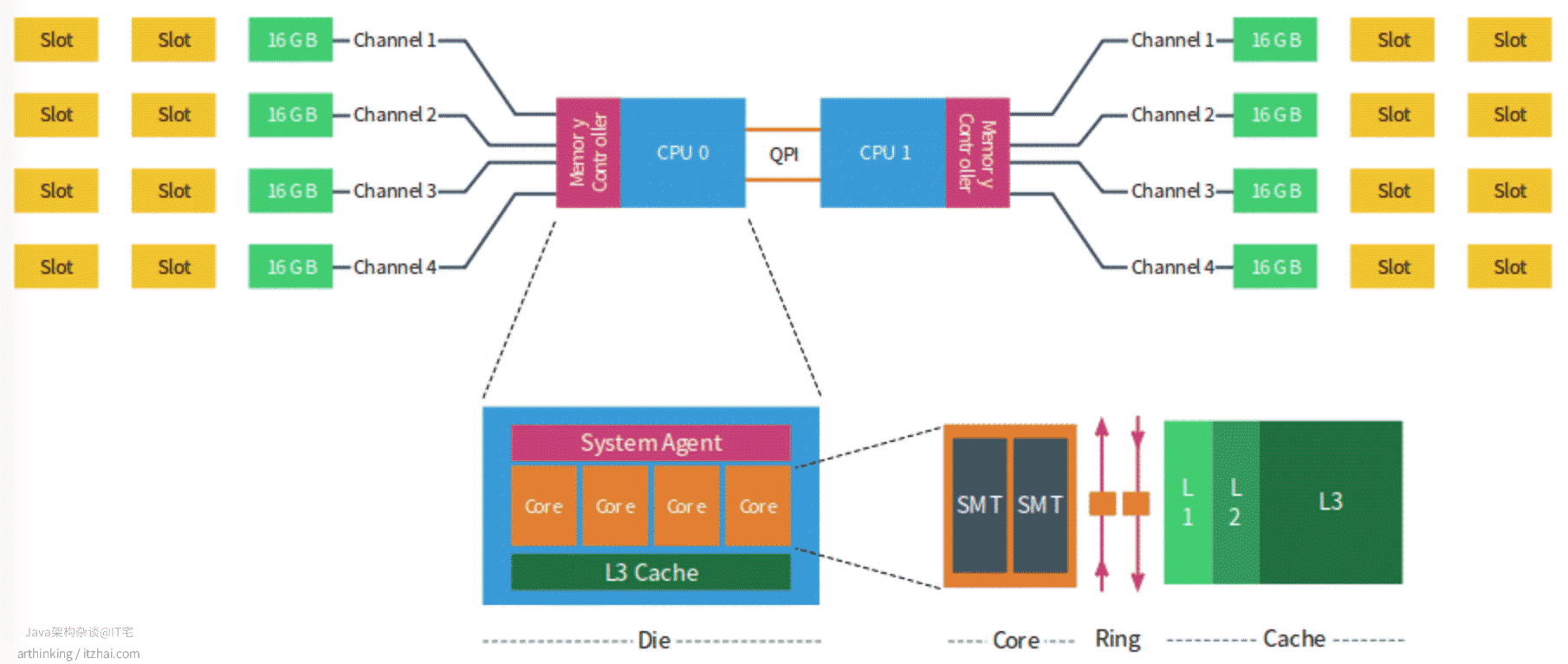
每个CPU有自己的物理核、L3缓存,以及连接的内存,每个物理核包括L1、L2缓存。不同处理器之间通过QPI总线连接。
每个CPU可以访问本地内存和系统中其他CPU控制的内存,由其他CPU管理的内存被视为远程内存,远程内存通过QPI访问。
在上图中,包含两个CPU,每个CPU包含4个核,每个CPU包含4个通道,每个通道最多3个DIMM,每个通道都填充了一个16 GB的内存,每个CPU用64GB内存,系统总共有128GB内存。
2、NUMA对Redis性能有何影响?
读取远程内存导致的问题
在NUMA架构上,程序可以在不同的CPU上运行,假设一个程序现在CPU 0上面运行,并把数据保存到了CPU 0的内存中,然后继续在CPU 1上面运行,这个时候需要通过QPI访问远程内存,导致增加数据读取的时间,从而导致性能变差。
另外,每次切换CPU,就需要从L3缓存重新加载相关的指令和数据到L1、L2缓存中,如果L3缓存也找不到,则会从内存中加载,导致增加CPU的处理时间。
如何解决?
linux 操作系统提供了一个名为 NUMACTL 的函数,NUMACTL 提供了控制的能力:
- NUMA 调度策略,例如,我想在哪些内核上运行这些任务
- 内存放置策略,在哪里分配数据
为了解决这个问题,我们可以把我们的程序绑定到某一个CPU上面来调度执行,相关命令:
1 | # 查看CPU信息 |
当然,也可以通过Taskset,进行设置,更详细的相关操作说明,参考:NUMACTL, taskset and other tools for controlling NUMA accesses notes[2]
如果我们的网络中断处理程序也做了绑核操作,建议把Redis和网络中断成本绑定到同一个CPU上。
切记:Redis是需要用到多线程能力的(RDB、AOF文件生成、惰性删除…),我们不能把Redis只绑定到某一个内核中,否则就失去了多线程的能力。
References
NUMA Deep Dive Part 2: System Architecture. Retrieved from http://www.staroceans.org/system_architecture.htm ↩︎
NUMACTL, taskset and other tools for controlling NUMA accesses notes. Retrieved from https://yunmingzhang.wordpress.com/2015/07/22/numactl-notes-and-tutorialnumactl-localalloc-physcpubind04812162024283236404448525660646872768084889296100104108112116120124/
[^ 20]: Caching Strategies and How to Choose the Right One. Retrieved from https://codeahoy.com/2017/08/11/caching-strategies-and-how-to-choose-the-right-one/ ↩︎

