

MySQL重做日志(Redo Log)主要适用于数据库的崩溃恢复,用于实现数据的完整性。
MySQL重做日志由两部分组成:
- 重做日志缓冲区 Log Buffer;
- 重做日志文件,重做日志文件在磁盘上由两个名为
ib_logfile0和ib_logfile1的物理文件表示。
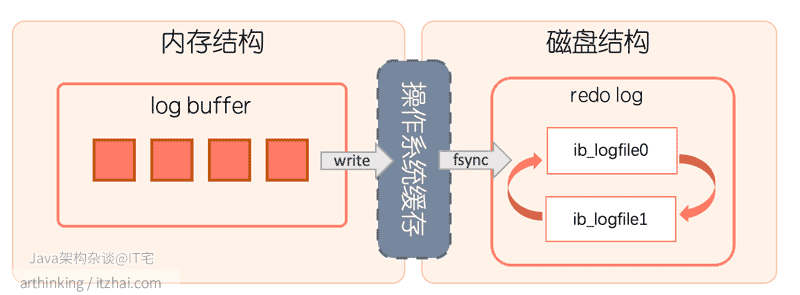
为了实现数据完整性,在脏页刷新到磁盘之前,必须先把重做日志写入到磁盘。除了数据页,聚集索引、辅助索引以及Undo Log都需要记录重做日志。
1、Redo Log在事务中的写入时机
在MySQL事务中,除了写Redo log,还需要写binlog,为此,我们先来简单介绍下binlog。
1.1、binlog
全写:Binary Log,二进制log。二进制日志是一组日志文件。其中包含有关对MySQL服务器实例进行的数据修改的信息。
Redo Log是InnoDB引擎特有的,而binlog是MySQL的Server层实现的,所有引擎都可以使用。
Redo Log的文件是循环写的,空间会用完,binlog日志是追加写的,不会覆盖以前的日志。
binlog主要的目的:
- 主从同步,主服务器将二进制日志中包含的事件发送到从服务器,从服务器执行这些事件,以保持和主服务器相同的数据更改;
- 某些数据恢复操作需要使用二进制日志,还原到某一个备份点。
binlog主要是用于主从同步和数据恢复,Redo Log主要是用于实现事务数据的完整性,让InnoDB具有不会丢失数据的能力,又称为crash-safe。
binlog日志的两种记录形式:
- 基于SQL的日志记录:事件包含产生数据更改(插入,新增,删除)的SQL语句;
- 基于行的日志记录:时间描述对单个行的更改。
混合日志记录默认情况下使用基于语句的日志记录,但根据需要自动切换到基于行的日志记录。
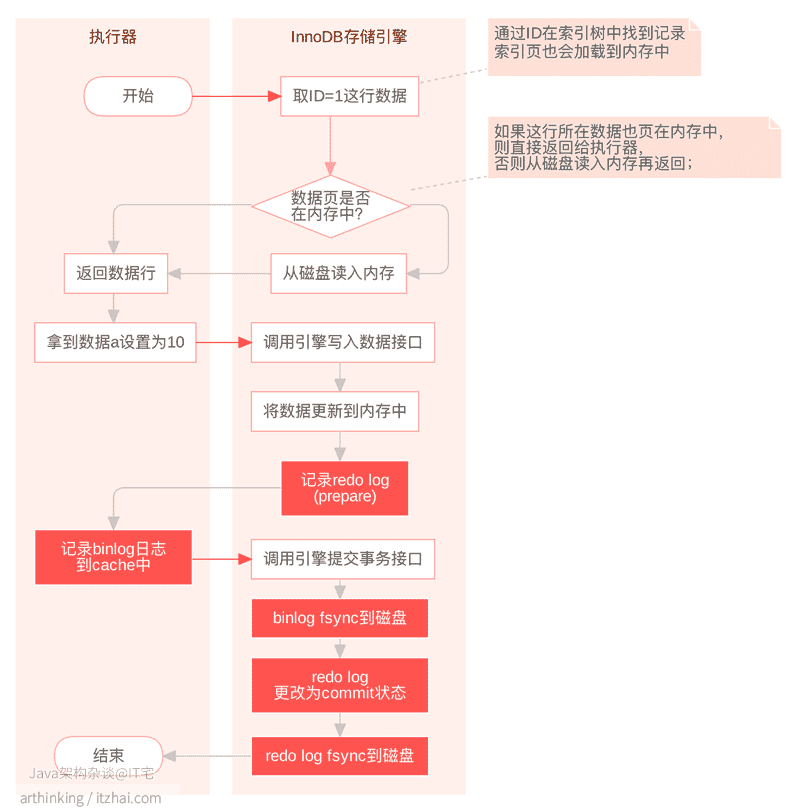
1.2、Redo Log在事务中的写入时机
简单的介绍完binlog,我们再来看看MySQL的Redo Log的写入流程。
假设我们这里执行一条sql
1 | update t20 set a=10 where id=1; |
执行流程如下:
2、如何保证数据不丢失
前面我们介绍Log Buffer的时候,提到过,为了保证数据不丢失,我们需要执行以下操作:
- 如果启用了binlog,则设置:sync_binlog=1;
- innodb_flush_log_at_trx_commit=1;
- sync_binlog=0:表示每次提交事务都只 write,不 fsync;
- sync_binlog=1:表示每次提交事务都会执行 fsync;
- sync_binlog=N(N>1) :表示每次提交事务都 write,但累积 N 个事务后才 fsync。
这两个的作用相当于在上面的流程最后一步,提交事务接口返回Server层之前,把binlog cache和log buffer都fsync到磁盘中了,这样就保证了数据的落盘,不会丢失,即使奔溃了,也可以通过MySQL的binlog和redo log恢复数据相关流程如下:
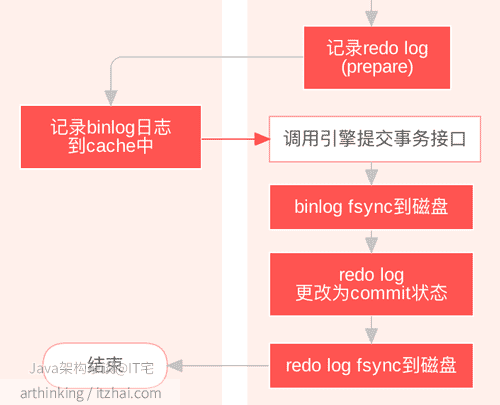
在磁盘和内存中的处理流程如下面编号所示:
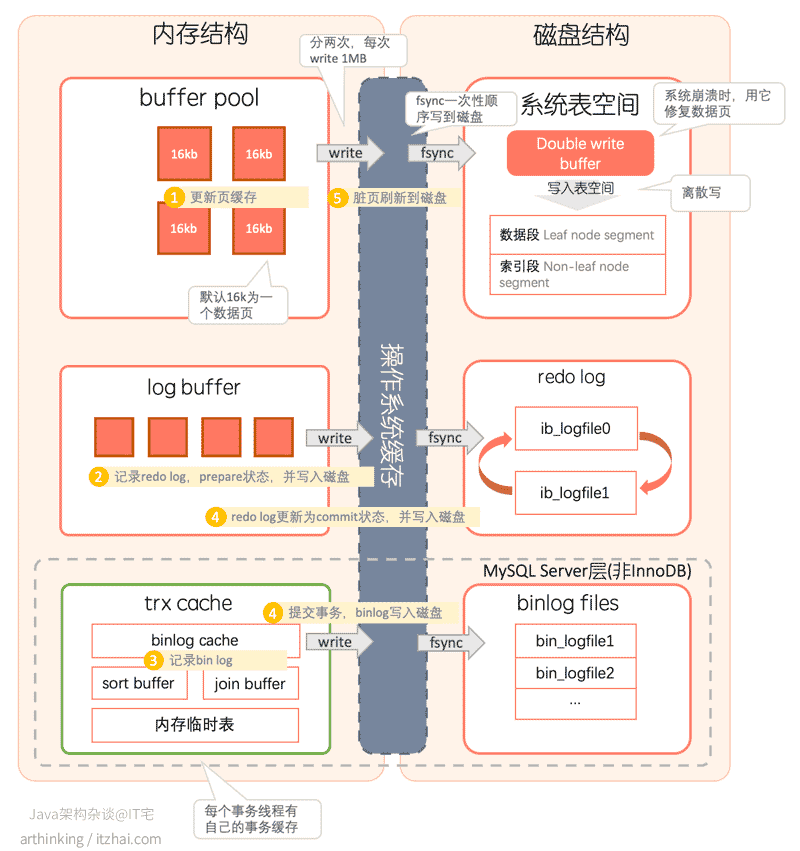
其中第四步log buffer持久化到磁盘的时机为:
- log buffer占用的空间即将达到
innodb_log_buffer_size一半的时候,后台线程主动写盘; - InnoDB后台有个线程,每隔1秒会把log buffer刷到磁盘;
- 由于log buffer是所有线程共享的,当其他事务线程提交时也会导致已写入log buffer但还未提交的事务的redo log一起刷新到磁盘
其中第五步:脏页刷新到磁盘的时机为:
- 系统内存不足,需要淘汰脏页的时候,要把脏页同步回磁盘;
- MySQL空闲的时候;
- MySQL正常关闭的时候,会把脏页flush到磁盘。
参数
innodb_max_dirty_pages_pct是脏页比例上限,默认值是 75%。
为什么第二步 redo log prepare状态也要写磁盘?
因为这里先写了,才能确保在把binlog写到磁盘后崩溃,能够恢复数据:如果判断到redo log是prepare状态,那么查看是否存XID对应的binlog,如果存在,则表示事务成功提交,需要用prepare状态的redo log进行恢复。
这样即使崩溃了,也可以通过redo log来进行恢复了,恢复流程如下:
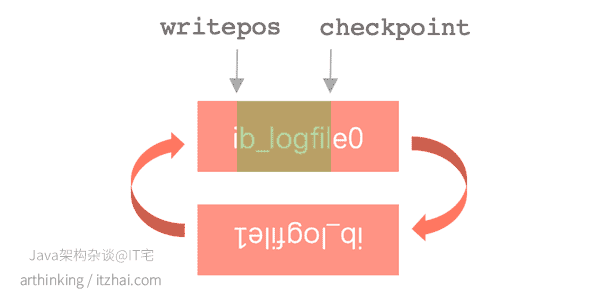
Redo Log是循环写的,如下图:
- writepos记录了当前写的位置,一边写位置一边往前推进,当writepos与checkpoint重叠的时候就表示logfile写满了,绿色部分表示是空闲的空间,红色部分是写了redo log的空间;
- checkpoint处标识了当前的
LSN,每当系统崩溃重启,都会从当前checkpoint这个位置执行重做日志,根据重做日志逐个确认数据页是否没问题,有问题就通过redo log进行修复。
LSN Log Sequence Number的缩写。代表日志序列号。在InnoDB中,LSN占用8个字节,单调递增,LSN的含义:
- 重做日志写入的总量;
- checkpoint的位置;
- 页的版本;
除了重做日志中有LSN,每个页的头部也是有存储了该页的LSN,我们前面介绍页面格式的时候有介绍过。
在页中LSN表示该页最后刷新时LSN的大小。[1]
References
姜承尧. MySQL技术内幕-InnoDB存储引擎第二版[M]. 机械工业出版社, 2013-5:302-303. ↩︎

