

我们在broker.conf文件中配置了消息存储的根目录:
1 | # 消息存储根目录 |
进入这个目录,我们可以发现如下的目录结构:
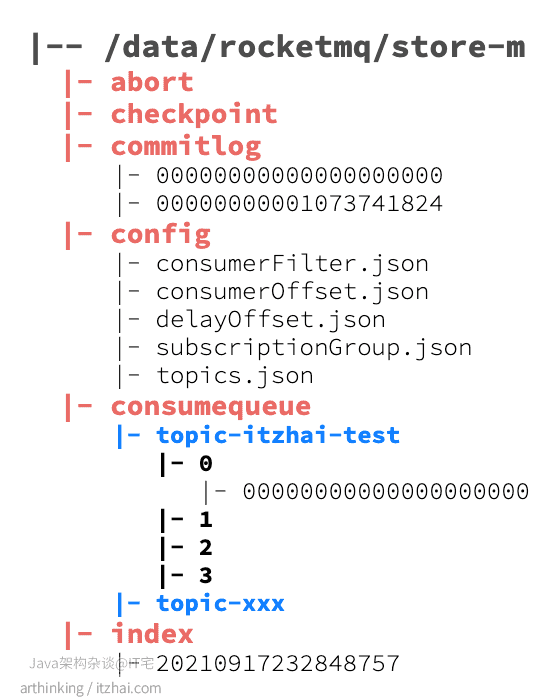
其中:
- abort:该文件在broker启动时创建,关闭时删除,如果broker异常退出,则文件会存在,在下次启动时会走修复流程;
- checkpoint:检查点,主要存放以下内容:
- physicMsgTimestamp:commitlog文件最后一次落盘时间;
- logicsMsgTimestamp:consumequeue最后一次落盘时间;
- indexMsgTimestamp:索引文件最后一次落盘时间;
- commitlog:存放消息的完整内容,所有的topic消息都会通过文件追加的形式写入到该文件中;
- config:消息队列的配置文件,包括了topic配置,消费的偏移量等信息。其中consumerOffset.json文件存放消息队列消费的进度;
- consumequeue:topic的逻辑队列,在消息存放到commitlog之后,会把消息的存放位置记录到这里,只有记录到这里的消息,才能被消费者消费;
- index:消息索引文件,通过Message Key查询消息时,是通过该文件进行检索查询的。
1 RocketMQ消息是如何存储的
下面我们来看看关键的commitlog以及consumequeue:
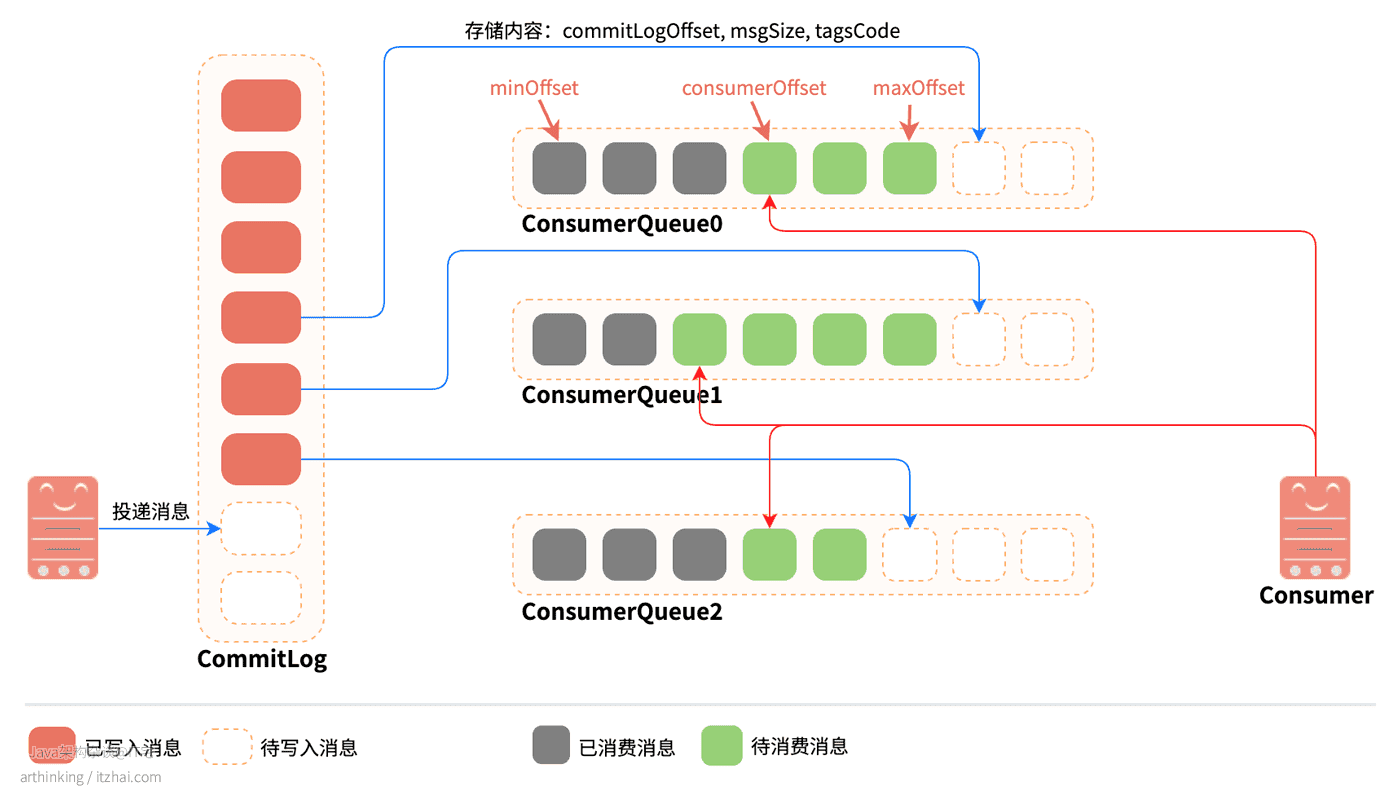
消息投递到Broker之后,是先把实际的消息内容存放到CommitLog中的,然后再把消息写入到对应主题的ConsumeQueue中。其中:
CommitLog:消息的物理存储文件,存储实际的消息内容。每个Broker上面的CommitLog被该Broker上所有的ConsumeQueue共享。
单个文件大小默认为1G,文件名长度为20位,左边补零,剩余为起始偏移量。预分配好空间,消息顺序写入日志文件。当文件满了,则写入下一个文件,下一个文件的文件名基于文件第一条消息的偏移量进行命名;
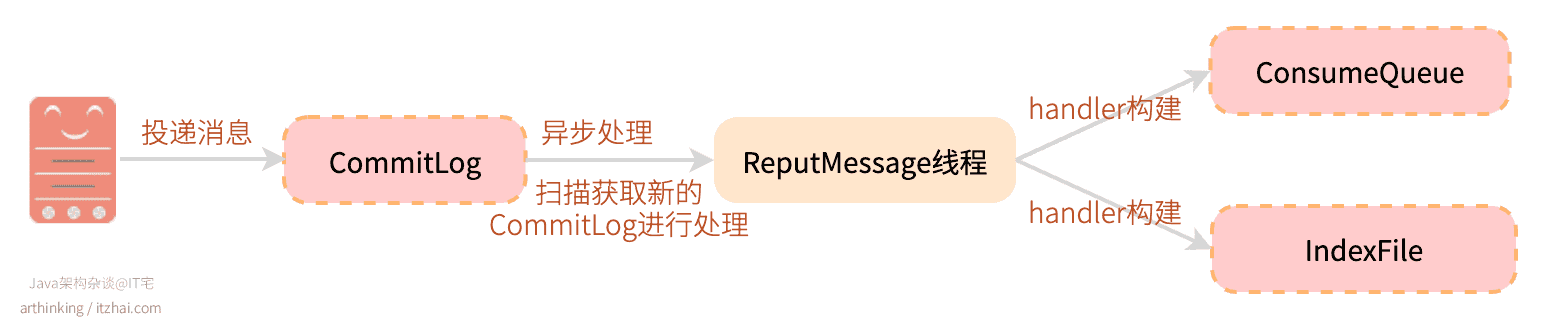
ConsumeQueue:消息的逻辑队列,相当于CommitLog的索引文件。RocketMQ是基于Topic主题订阅模式实现的,每个Topic下会创建若干个逻辑上的消息队列ConsumeQueue,在消息写入到CommitLog之后,通过Broker的后台服务线程(ReputMessageService)不停地分发请求并异步构建ConsumeQueue和IndexFile(索引文件,后面介绍),然后把每个ConsumeQueue需要的消息记录到各个ConsumeQueue中。
ConsumeQueue主要记录8个字节的commitLogOffset(消息在CommitLog中的物理偏移量), 4个字节的msgSize(消息大小), 8个字节的TagHashcode,每个元素固定20个字节。
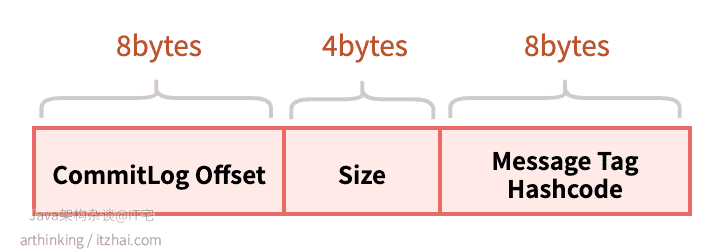
ConsumeQueue相当于CommitLog文件的索引,可以通过ConsumeQueue快速从很大的CommitLog文件中快速定位到需要的消息。
ConsumeQueue的存储结构
主题消息队列:在consumequeue目录下,按照topic的维度存储消息队列。
重试消息队列:如果topic中的消息消费失败,则会把消息发到重试队列,重新队列按照消费端的GroupName来分组,命名规则:%RETRY%ConsumerGroupName
死信消息队列:如果topic中的消息消费失败,并且超过了指定重试次数之后,则会把消息发到死信队列,死信队列按照消费端的GroupName来分组,命名规则:%DLQ%ConsumerGroupName
假设我们现在有一个topic:itzhai-test,消费分组:itzhai_consumer_group,当消息消费失败之后,我们查看consumequeue目录,会发现多处了一个重试队列:

我们可以在RocketMQ的控制台看到这个重试消息队列的主题和消息:
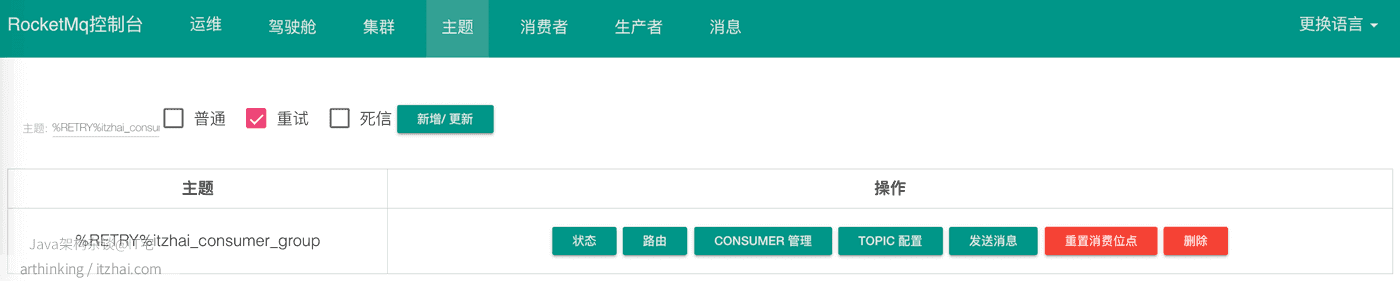
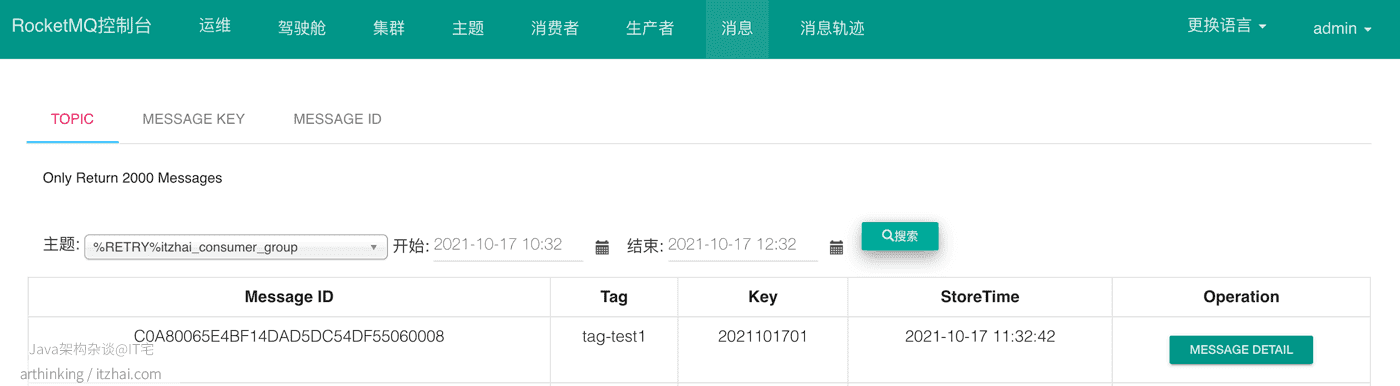
如果一直重试失败,达到一定次数之后(默认是16次,重试时间:1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h),就会把消息投递到死信队列:

2 RocketMQ是如何保证存取消息的效率的
2.1 如何保证高效写
每条消息的长度是不固定的,为了提高写入的效率,RocketMQ预先分配好1G空间的CommitLog文件,采用顺序写的方式写入消息,大大的提高写入的速度。
RocketMQ中消息刷盘主要可以分为同步刷盘和异步刷盘两种,通过flushDiskType参数进行配置。如果需要提高写消息的效率,降低延迟,提高MQ的性能和吞吐量,并且不要求消息数据存储的高可靠性,可以把刷盘策略设置为异步刷盘。
2.2 如何保证高效读
**为了提高读取的效率,RocketMQ使用ConsumeQueue作为消费消息的索引,使用IndexFile作为基于消息key的查询的索引。**下面来详细介绍下。
2.2.1 ConsumeQueue
读取消息是随机读的,为此,RocketMQ专门建立了ConsumeQueue索引文件,每次先从ConsumeQueue中获取需要的消息的地址,消息大小,然后从CommitLog文件中根据地址直接读取消息内容。在读取消息内容的过程中,也尽量利用到了操作系统的页缓存机制,进一步加速读取速度。
ConsumeQueue由于每个元素大小是固定的,因此可以像访问数组一样访问每个消息元素。并且占用空间很小,大部分的ConsumeQueue能够被全部载入内存,所以这个索引查找的速度很快。每个ConsumeQueue文件由30w个元素组成,占用空间在6M以内。每个文件默认大小为600万个字节,当一个ConsumeQueue类型的文件写满之后,则写入下一个文件。
2.2.2 IndexFile为什么按照Message Key查询效率高?
我们在RocketMQ的store目录中可以发现有一个index目录,这个是一个用于辅助提高查询消息效率的索引文件。通过该索引文件实现基于消息key来查询消息的功能。
物理存储结构
IndexFile索引文件物理存储结构如下图所示:
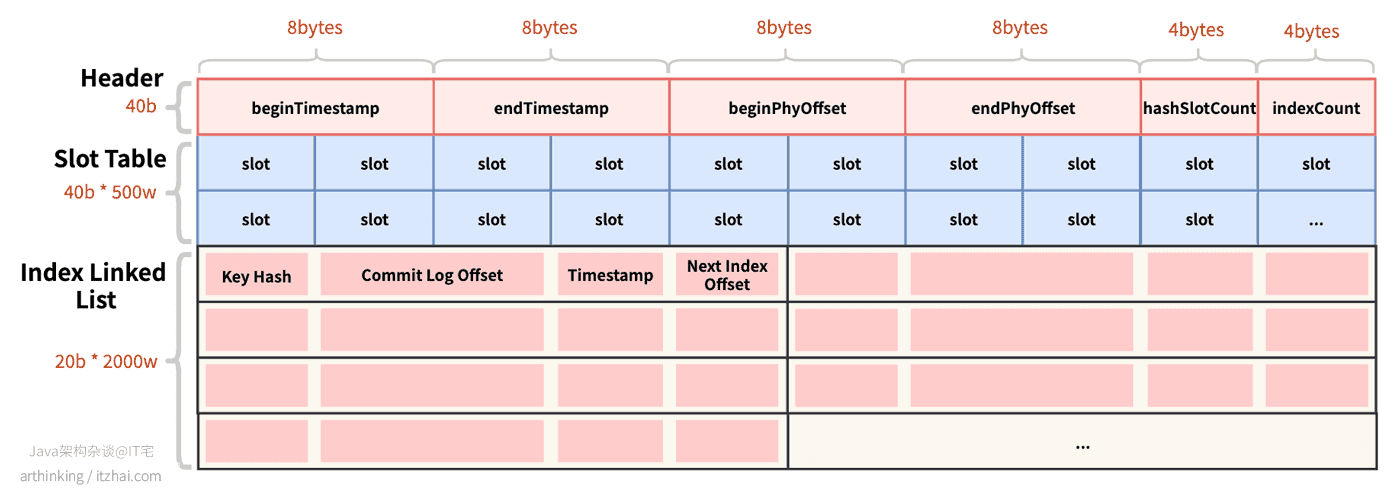
- Header:索引头文件,40 bytes,包含以下信息:
beginTimestamp:索引文件中第一个索引消息存入Broker的时间戳;endTimestamp:索引文件中最后一个索引消息存入Broker的时间戳beginPHYOffset:索引文件中第一个索引消息在CommitLog中的偏移量;endPhyOffset:索引文件中最后一个索引消息在CommitLog中的偏移量;hashSlotCount:构建索引使用的slot数量;indexCount:索引的总数;
- Slot Table:槽位表,类似于Redis的Slot,或者哈希表的key,使用消息的key的hashcode与slotNum取模可以得到具体的槽的位置。每个槽位占4 bytes,一个IndexFile可以存储500w个slot;
- Index Linked List:消息的索引内容,如果哈希取模后发生槽位碰撞,则构建成链表,一个IndexFile可以存储2000w个索引:
Key Hash:消息的哈希值;Commit Log Offset:消息在CommitLog中的偏移量;Timestamp:消息存储的时间戳;Next Index Offset:下一个索引的位置,如果消息取模后发生槽位槽位碰撞,则通过此字段把碰撞的消息构成链表。
每个IndexFile文件的大小:40b + 4b * 5000000 + 20b * 20000000 = 420000040b,约为400M。
逻辑存储结构
IndexFile索引文件的逻辑存储结构如下图所示:
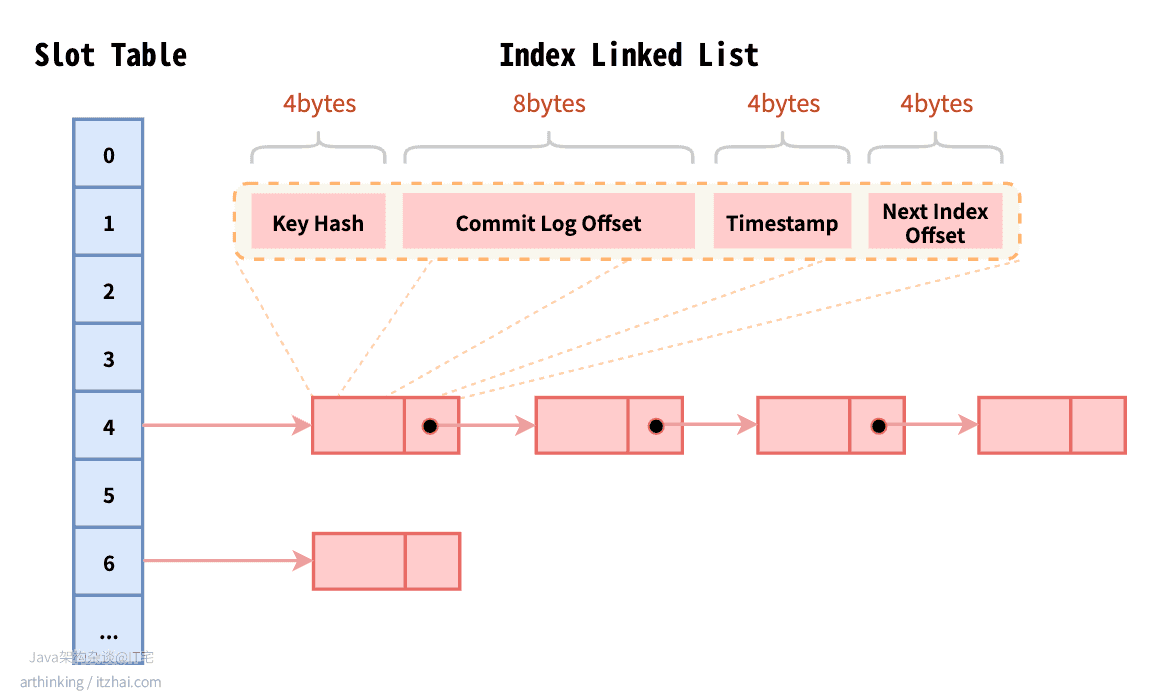
IndexFile逻辑上是基于哈希表来实现的,Slot Table为哈希键,Index Linked List中存储的为哈希值。
2.2.3 为什么按照MessageId查询效率高?
RocketMQ中的MessageId的长度总共有16字节,其中包含了:消息存储主机地址(IP地址和端口),消息Commit Log offset。“
按照MessageId查询消息的流程:Client端从MessageId中解析出Broker的地址(IP地址和端口)和Commit Log的偏移地址后封装成一个RPC请求后通过Remoting通信层发送(业务请求码:VIEW_MESSAGE_BY_ID)。Broker端走的是QueryMessageProcessor,读取消息的过程用其中的 commitLog offset 和 size 去 commitLog 中找到真正的记录并解析成一个完整的消息返回。
3 RocketMQ集群是如何做数据分区的?
我们继续看看在集群模式下,RocketMQ的Topic数据是如何做分区的。IT宅(itzhai.com)提醒大家,实践出真知。这里我们部署两个Master节点:
3.1 RocketMQ的Topic在集群中是如何存储的
我们通过手动配置每个Broker中的Topic,以及ConsumeQueue数量,来实现Topic的数据分片,如,我们到集群中手动配置这样的Topic:
broker-a创建itzhai-com-test-1,4个队列;broker-b创建itzhai-com-test-1,2个队列。
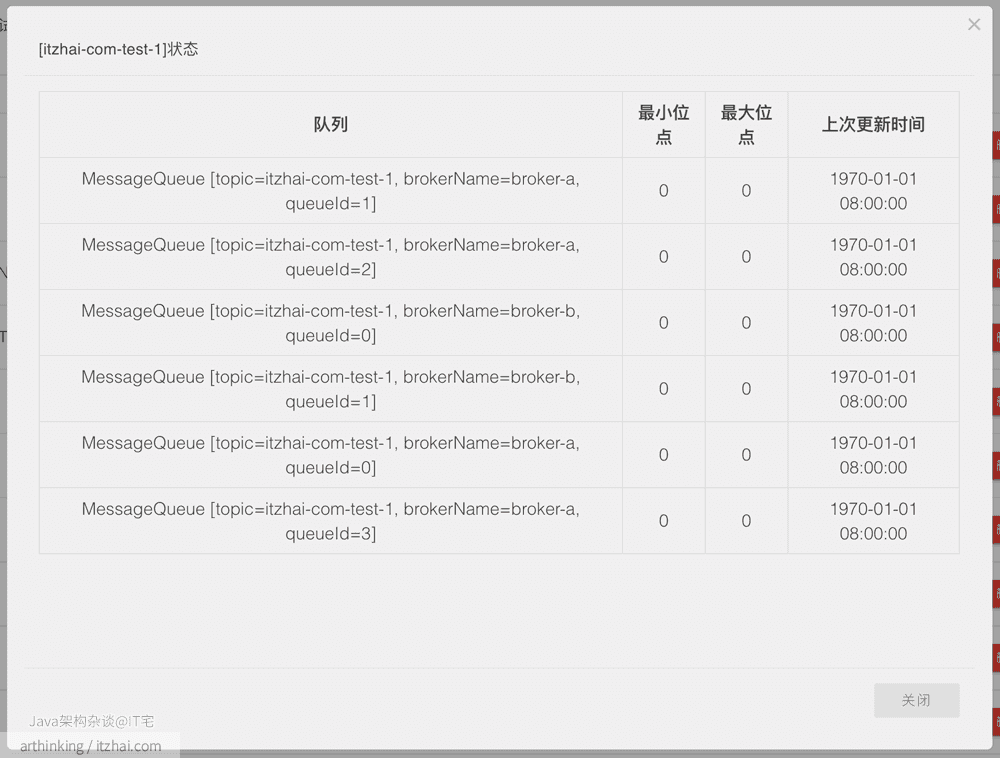
创建完成之后,Topic分片集群分布如下:
即:
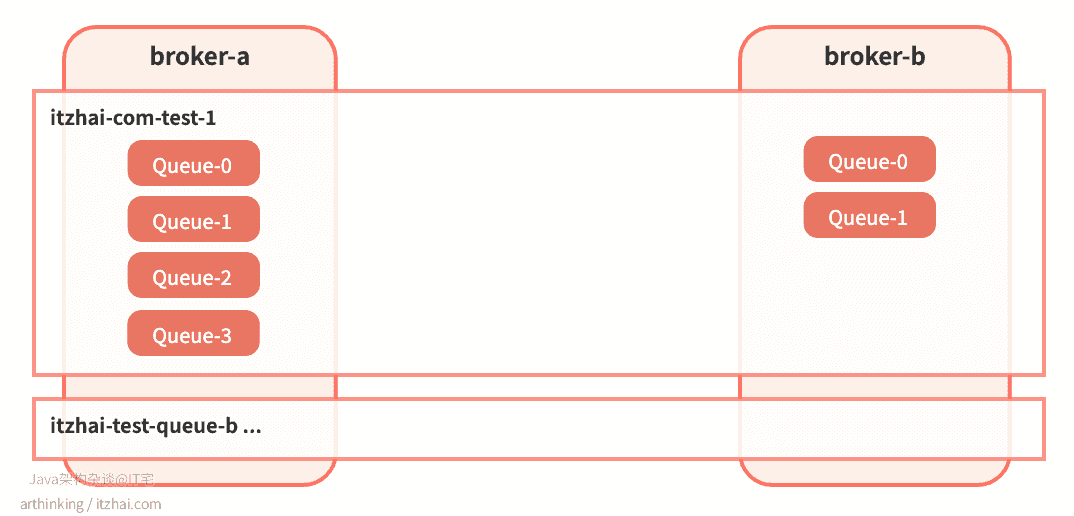
可以发现,RocketMQ是把Topic分片存储到各个Broker节点中,然后在把Broker节点中的Topic继续分片为若干等分的ConsumeQueue,从而提高消息的吞吐量。ConsumeQueue是作为负载均衡资源分配的基本单元。
这样把Topic的消息分区到了不同的Broker上,从而增加了消息队列的数量,从而能够支持更块的并发消费速度(只要有足够的消费者)。
3.2 Broker自动创建Topic会有什么问题?
假设设置为通过Broker自动创建Topic(autoCreateTopicEnable=true),并且Producer端设置Topic消息队列数量设置为4,也就是默认值:
1 | producer.setDefaultTopicQueueNums(4); |
尝试往一个新的 topic itzhai-test-queue-1连续发送10条消息,发送完毕之后,查看Topic状态:
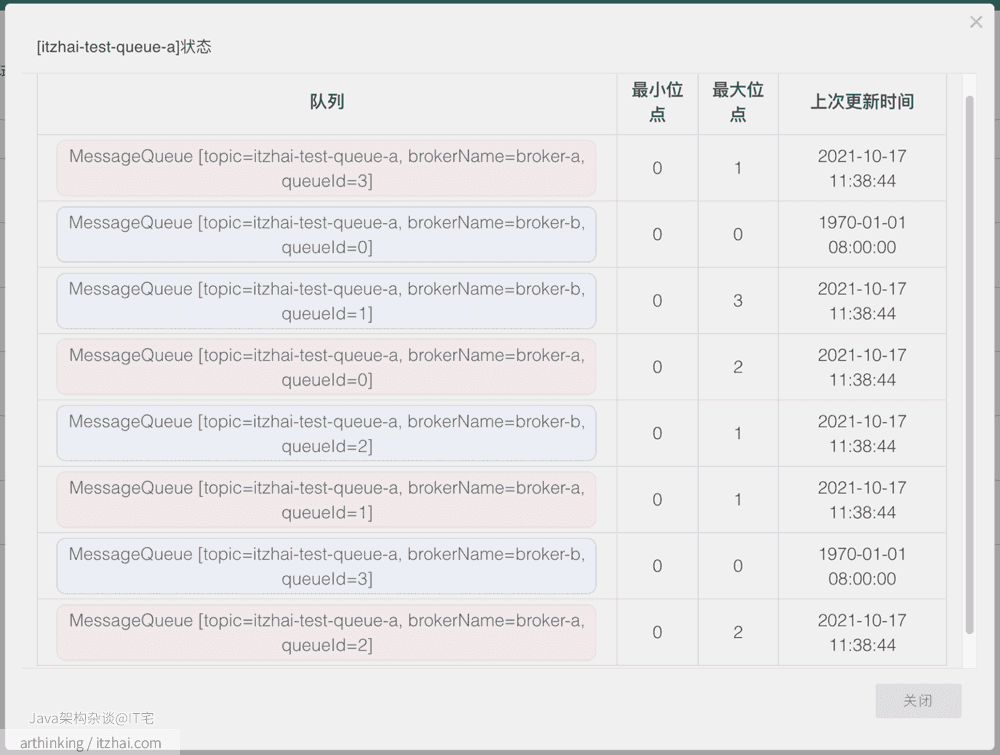
我们可以发现,在两个broker上面都创建了itzhai-test-queue-a,并且每个broker上的消息队列数量都为4。怎么回事,我配置的明明是期望创建4个队列,为什么加起来会变成了8个?如下图所示:
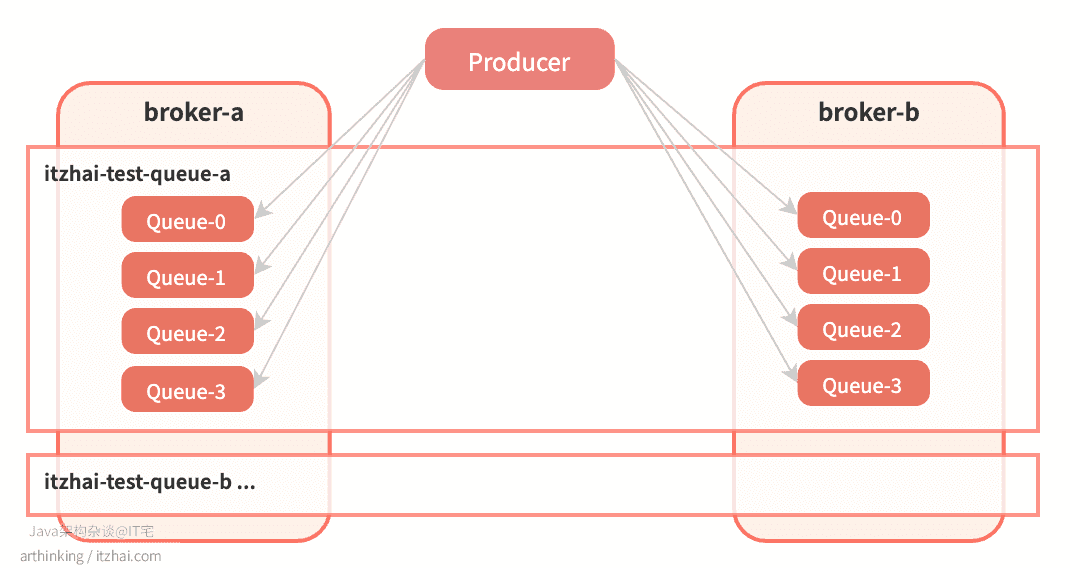
由于时间关系,本文我们不会带大家从源码方面去解读为啥会出现这种情况,接下来我们通过一种更加直观的方式来验证下这个问题:继续做实验。
我们继续尝试往一个新的 topic itzhai-test-queue-10发送1条消息,注意,这一次不做并发发送了,只发送一条,发送完毕之后,查看Topic状态:
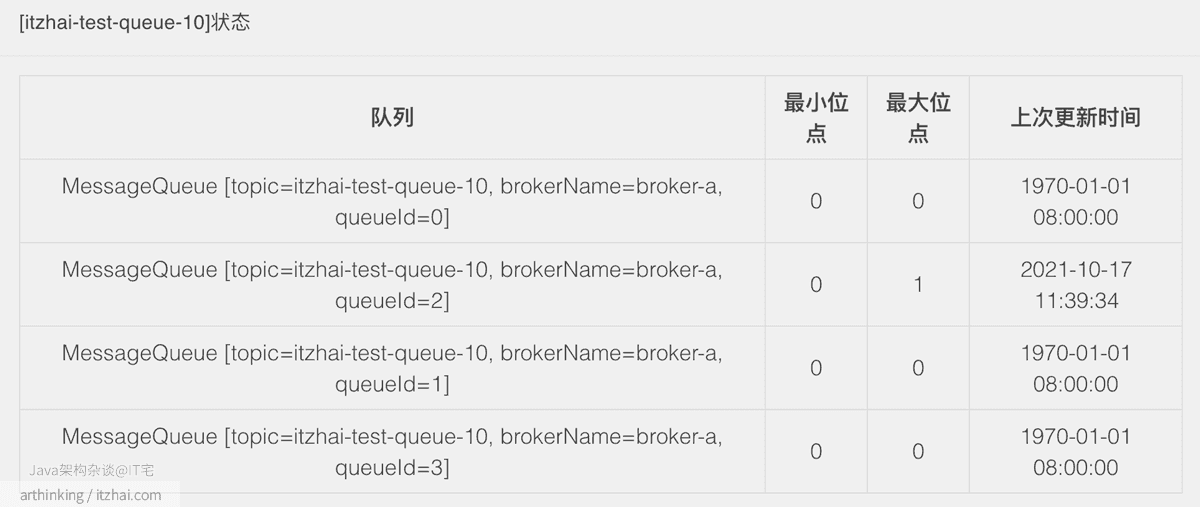
可以发现,这次创建的消息队列数量又是对的了,并且都是在broker-a上面创建的。接下来,无论怎么并发发送消息,消息队列的数量都不会继续增加了。
其实这也是并发请求Broker,触发自动创建Topic的bug。
为了更加严格的管理Topic的创建和分片配置,一般在生产环境都是配置为手动创建Topic,通过提交运维工单申请创建Topic以及Topic的数据分配。
接下来我们来看看RocketMQ的特性。更多其他技术的底层架构内幕分析,请访问我的博客IT宅(itzhai.com)或者关注Java架构杂谈公众号。

