

1 消息ACK机制[1]
ACK (Acknowledge character),即是确认字符,消息的接收方需要告诉发送方已确认接收消息,这是实现可靠消息投递的必备特性。
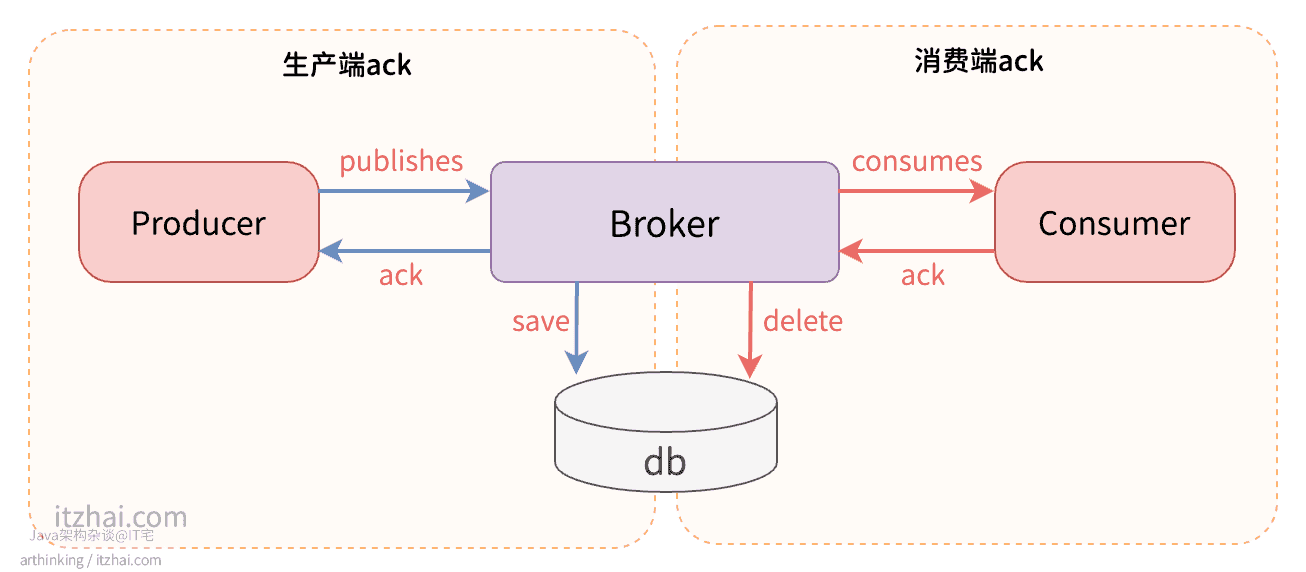
MQ系统中,涉及到ACK的流程如下图所示:
1.1 生产端ACK之Confirm消息机制
如上图所示:
Producer发布消息到Broker;Broker将消息落地;Broker发送ack给Producer。
如果Producer没有收到ack,那么可以重发消息,直到收到ack为止。为了避免无限的给Broker投递消息,应该设置一个重试上限,并记录下发送失败的消息。在这个过程中,MQ Server可能会收到重复消息。
在RabbitMQ中,生产端的ACK通过ConfirmListener机制来实现:
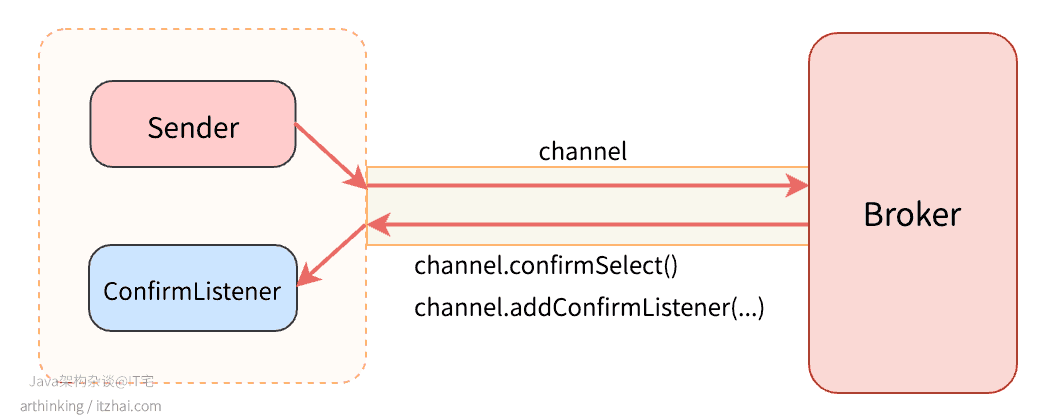
在channel中开启确认模式confirmSelect(),然后在channel中添加监听,用来监听Broker返回的应答。
Broker何时给生产端发送ACK?
对于不可路由的消息,一旦交换机验证消息不会路由到任何队列,Broker将发出ack,如果开启了Return消息机制(下一小节讲解),那么Broker会先发送basic.return消息给客户端,再发送basic.ack消息。示例代码如下:
1 | String message = "Hello itzhai.com...."; |
执行以上代码,生产者将依次收到basic.return(Return消息),basic.ack(Confirm消息)。
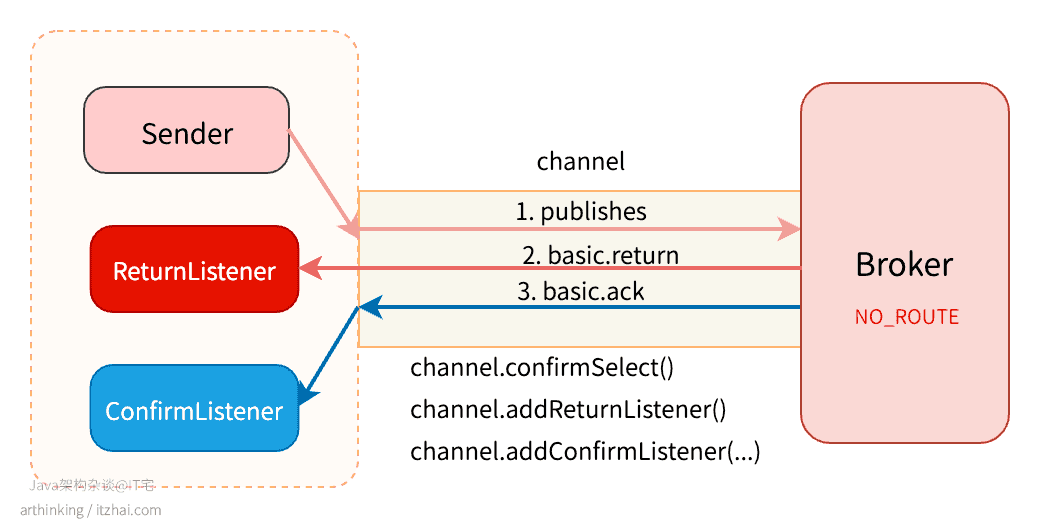
对于可路由的消息,当所有队列都接收到消息的之后,Broker向生产端发送ACK。如果路由到的是持久队列,并且是持久消息,那么这个ACK就意味着消息持久化到了磁盘。
也就是说,路由到持久队列的持久消息的ACK将在将消息持久化到磁盘后发送。
RabbitMQ消息持久化的性能如何?
RabbitMQ持久化消息的刷盘策略:为了尽可能减少fsync(2)的调用次数,RabbitMQ在间隔一段时间(几百毫秒)或者在队列空闲的时候将消息分批保存到磁盘中。
这就意味着,在正常的负载下,生产端接收Broker的ACK时延可达几百毫秒。为了提高吞吐量,强烈建议生产端应用程序异步处理ACK,或者批量发布消息,并等待ACK。
1.2 生产端ACK之Return消息机制
Return消息机制用于处理一些不可路由的消息。发送消息的时候,如果指定的routing_key路由不到队列,这个时候就可以通过ReturnListener监听这种异常情况。
1.3 消费端ACK
如上图所示:
- 消息服务器将消息投递给消费者;
- 消费者消费消息,并向消息服务器发送ack;
- 消息服务器收到消费者的ack之后,将已落地的消息删除掉。
当Broker一直没有收到消费端的ACK,则会重发消息,这个过程一般采用指数退避策略,时间间隔按指数增长。
Rabbit中的消费端ACK
在RabbitMQ中,消费端的ACK可以是自动的,或者手动的。
手动ACK签收
通过以下方法关闭自动ack签收(入参autoAck设置为false):
1 | Channel.java |
然后自定义一个支持ack的Consumer:
1 | public class TestAckConsumer extends DefaultConsumer { |
channel中有三种ack相关的方法:
- basic.ack:用于肯定确认,指示RabbitMQ消息已经
处理成功,可以丢弃消息了; - basic.nack:用于否定确认,指示RabbitMQ消息
未处理成功,可以通过参数指定是否需要丢弃消息还是重回队列。 - basic.reject:用于否定确认,指示RabbitMQ消息
未处理成功,可以通过参数指定是否需要丢弃消息还是重回队列。
basic.nack与basic.reject的区别就是,basic.nack支持批量手动确认,basic.nack是RabbitMQ对AMQP 0-9-1协议的扩展。
自动ACK签收
使用自动确认模式,消息在发送之后就立刻被标记为投递消费成功。如果消费者的TCP连接或者通道在真正投递成功之前就关闭了,那么Broker发送的消息将会丢失。自动确认模式是以降低消息投递的可靠性来换取更高的消费端吞吐量(只要消费端处理速度能够跟上)。
如何避免消费过载的问题(消费端限流)?
使用自动模式可以提高吞吐量,但是前提是消费端要能够处理得过来,如果处理不过来,就会在消费端的内存中积压消息,直至把内存耗尽。因此,自动确认模式仅推荐用于能够以稳定的速度高效地处理消息的消费者。
为了避免消费过载问题,我们一般使用手动确认模式,配合通道预取限制一起使用:
1 | // 每条消息的大小限制,0表示不限制 |
如何提高手动ACK签收的效率
如果不需要严格控制发送消费端ACK的时间,即,只要消费者成功接收到消息,不管有没有消费成功,都允许进行ACK回复,那么就可以通过批量ACK签收的功能更来提高签收的消效率。做法如下:
1 | // 手动签收模式 |
这样执行basicAck,deliveryTag以及deliveryTag之前的所有消息都将会被签收。

什么时候需要让消息重回队列?
有时候消费者太繁忙导致无法立即处理接收到的消息,但是其他实例可能可以处理。这种情况,就可以拒绝消息,并且让消息重回队列。
另外,可以使用channel.basicNack方法一次拒绝或者重新排队多条消息:
1 | // 指定批量拒绝策略 |
极端情况下,如果所有消费者因为暂时无法处理接收的消息,会导致消息不断的循环重回入队,导致消耗网络带宽和CPU资源。为了避免这种情况,可以跟踪重回队列的消息数量,决定是否需要永久拒绝消息(丢弃消息)还是延迟重回队列的时间。
2 消息的顺序性能够得到保证吗?
一般情况下,在单个通道上发布的消息,Rabbit会按照消息发布的相通顺序向生产端发送ACK消息,但也不是绝对的。发布ACK的确切时刻取决于消息的传递模式(持久化或瞬时),以及消息路由到的队列的属性。也就是说,不同的消息在不同的时间准备好进行确认,确认消息可以以不同的顺序达到。所以,应用程序尽可能不要依赖于消息的顺序性。
3 消息处理的幂等性如何处理?
无论是生产端还是消费端的ACK,都有可能因为网络或者程序问题导致ACK消息没有及时送达,这个时候会导致重复的消息投递。如何保证消费同一条消息的情况下不影响业务,这就需要保证消息处理的幂等性。
也就是说,针对同一条消息,无论消费者消费多少次,产生的效果始终应该跟消费一次的保持一致,并且返回的ACK结果也是一致的。
常用的实现消息处理幂等性的方法:
- 每条消息生成唯一ID,消费端根据唯一ID判断是否已经消费过,如果消费过,则直接返回消费成功的ACK。
- 针对入库的业务操作可以通过数据库的唯一索引来实现避免重复业务数据入库;
- 针对修改数据类的操作,可以先判断数据是否已经是目标状态了,如果是目标状态,直接返回再进行更新。
- 针对并发的场景,我们需要给业务消费程序添加分布式锁,避免并发执行导致触发业务重复处理。
4 死信队列[2]
如果消息队列中的消息没有被正常消费掉,那么该消息就会成为一个死信(Dead Letter),这条消息可以被重新发送到另一个交换机上,后面这个交换机就是死信交换机(DLX),死信交换机绑定的队列就是死信队列。在以下情况下导致的消息未被正常消费,均会使消息变为死信:
- 消费者使用
basic.reject或者basic.nack来拒绝消息,同时设置requeue参数为false,表示消息不需要重回队列; - 消息设置了TTL,并且过期了,或者队列设置了消息的过期时间
x-message-ttl; - 由于消息队列超过了长度限制导致消息被丢弃了。
死信队列也是一个正常的交换机,它可以是任何常见的交换机类型,与常规交换机声明没有区别。
DLX可以有客户端使用队列参数(arguments)进行定义,或者在服务器中使用策略(policy)进行定义,在policy和arguments都定义了的情况下,arguments中指定的那个会否决policy中指定的那个。
通过policy启用死信队列:
1 | rabbitmqctl set_policy DLX ".*" '{"dead-letter-exchange":"my-dlx"}' --apply-to queues |
通过arguments启用死信队列:
1 | // 声明一个交换机,作为死信交换机 |

