

导读:
Java代码性能优化谁最在行,那一定是每天从事优化工作的人,目前来看就是Java编译器了。我们本章主要了解下这个性能优化高手平时是怎么工作的,怎么帮我们提高代码效率,以及讨论一下代码效率方面的问题。看文本文,你可以了解到:
1.javac做了什么优化
2.Java后端编译器的发展史
3.JIT是如何工作的
4.效率与质量的平衡
为了探索编译器的内幕,我们得首先了解下Java编译器里面做了什么事情,怎么进行代码优化的。
Java编译器优化包括编译期优化和运行期优化。我们先一起来了解下:
1、编译期优化
语法糖是个好东西,可以帮助我们进一步封装Java语言的使用方法,使用更方便。根据前面我们学习的 10分钟教你如何hack掉Java编译器 知道,在编译之后还是会进行解除语法糖,还原期原本的面貌。
虽然语法糖简化了Java语言的编写,但是却又给语言本身蒙上了一层面纱,要懂得底层原理,还是要需要知道解除语法糖后的代码。
java编译器在编译期所做的一个重要事情就是解除语法糖,下面我们列举一些常用的语法糖以及解除后的代码。
1.1、类型擦除
在 探索Java泛型的本质 这篇文章中,我们已经了解过了泛型的类型擦除,现在再以一个简单的例子来说明下:
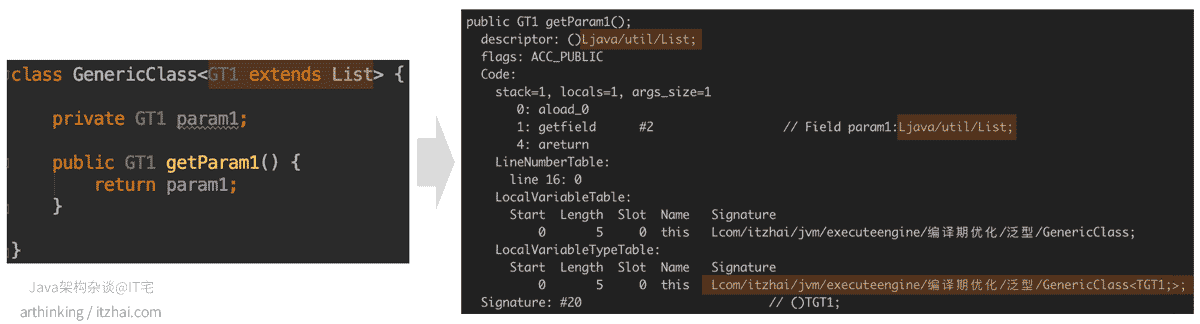
如上图,泛型指定了上限List,所以擦除后,操作的param1字段变成了List类型。
而this引用,即GenericClass类的实例由于并没有指定泛型的具体类型,所以最终Signature中的还是GenericClass<TGT1;>类型。
1.2、自动装箱、拆箱
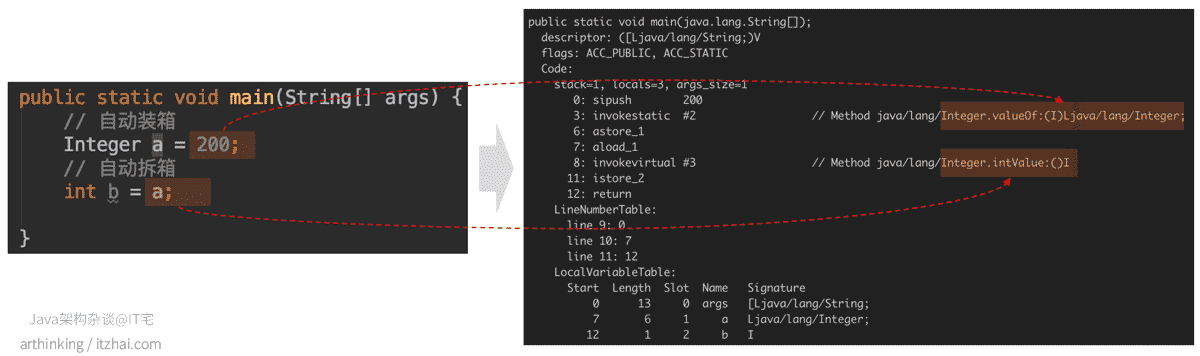
如上图,对于Integer类型,会自动使用Integer.valueOf()方法把数值转换为Interger类型,即自动装箱;
对于原始int类型,会自动使用Integer.intValue()方法把Interger类型转换为原生int类型,即拆箱。
以下是会做自动拆箱自动装箱的类型
| 原始类型 | 包装类型 | 装箱方法 | 拆箱方法 |
|---|---|---|---|
| byte 1字节 | Byte | Byte.valueOf() | Byte.byteValue() |
| char 2字节 | Charracter | Character.valueOf() | Character.charValue() |
| short 2字节 | Short | Short.valueOf() | Short.shortValue |
| int 4字节 | Integer | Integer.valueOf() | Integer.intValue() |
| long 8字节 | Long | Long.valueOf() | Long.longValue() |
| double 8字节 | Double | Double.valueOf() | Double.doubleValue() |
| boolean | Boolean | Boolean.valueOf() | Boolean.booleanValue() |
猜猜以下分别输出什么:
1 | public static void main(String[] args) { |
提示:
- 原始类型与包装类型进行
==+-*/等运算时,会进行自动拆箱,对基础数据类型进行运算; - 相同的包装类型比较,会把原始类型自动装箱为包装类型比较,注意部分包装类型部分范围对象会缓存到一个cache数组中,每次从数组中取值,如下表所示:
| 类型 | 缓存对象范围 |
|---|---|
| Short | (-128, 128) |
| Integer | (-128, 128) |
| Long | (-128, 128) |
| Character | [0, 128) |
- 不同类型比较,只能使用equals方法,该方法会先比较类型信息,然后才是比较具体的值。
1.3、遍历循环和变长参数
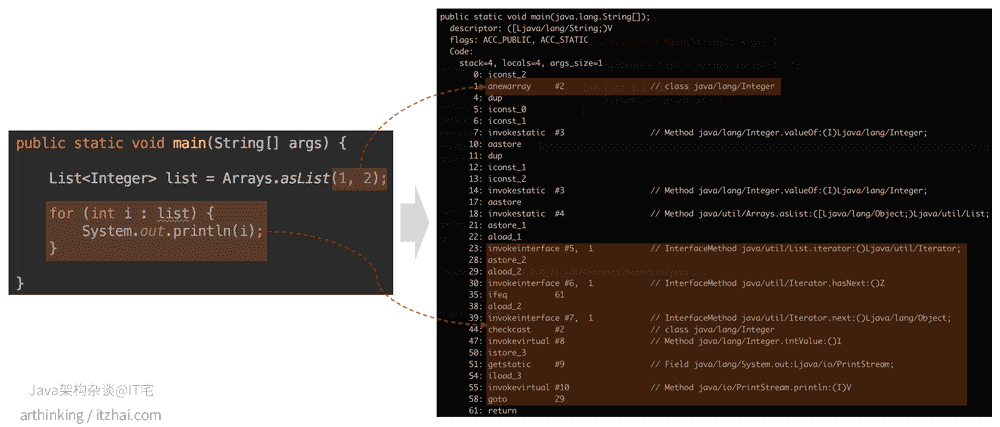
可以发现可变参数最终变为了创建一个固定大小的数组。
遍历循环变成了迭代器迭代,所以使用遍历循环语法的类需要实现Iterable接口。
1.4、条件编译
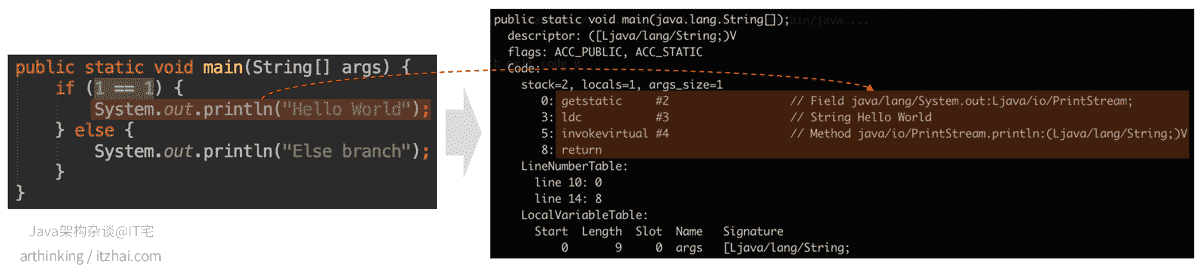
实现了类似C++中的条件编译(预处理器指示符 #ifdef)的功能,将分支中可以直接通过代码判断到不成立的代码块给消除掉。
2、运行期优化
在 10分钟教你如何hack掉Java编译器 这篇文章中,我们已经讲解过了Java程序编译执行的大致过程,再来回顾下,如下图:
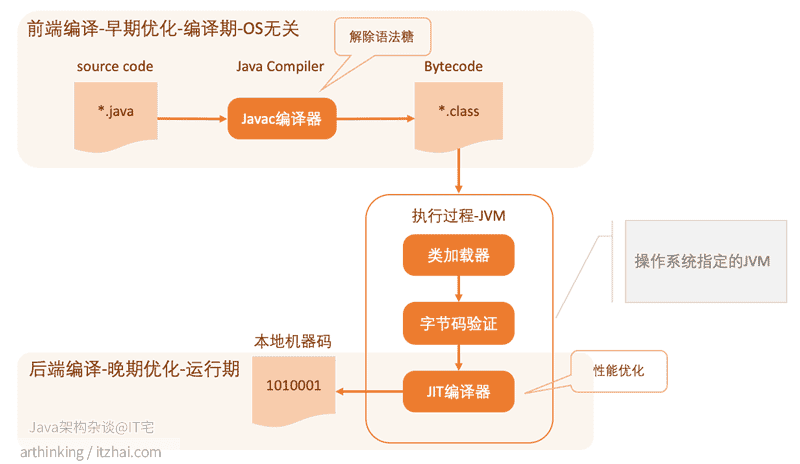
其中class文件加载到JVM之后,会由即时编译器(JIT)基于性能优化考虑,重新编译,生成本地机器码。
那么这个JIT编译器内部究竟是怎么工作的呢?什么时候会触发这个JIT编译器?接下来我们就逐步揭开这个面纱。
谈到字节码执行,我们先来说下这几个概念:
2.1、解释器(Interperter)
计算机尤其是CPU,只能执行相对较少的特定指令,这些指令成为汇编或者二进制指令。CPU执行的所有程序,最终都需要转换为这些指令。
不同的CPU指令集有所区别,如果直接把程序翻译为机器指令,那么在不同平台下面,都需要重新编译一次。Java语言为了能够实现“一次编译,到处运行”的效果,把源代码编译成了字节码这种中间表示形式。字节码中保存的是JVM特有的指令集。这样,我们只要为不同的平台分别编写JVM,那么就可以把同样的字节码分别在不同的平台运行了,从而达到了可移植的效果,这也是解释性语言的一个特点。
解释器就是用来在JVM中解释运行字节码的。
2.2、JIT
但是单单用解释器的话,每次都需要进行解释执行,效率比较低。JVM能够将字节码编译为平台二进制代码,该编译一般在程序执行的过程中发生,处理这种编译动作的编译器称为即时编译器,JIT(Just in time)。
HotSpot JVM中HotSpot的由来:来自于它用于编译代码的方法,在一般的程序中,有些代码会频繁执行,而这部分代码是影响程序性能的关键代码,这些代码称为热点,代码执行的越频繁,就越是热点代码。
JIT编译: 随着代码执行次数增多,JVM可以监控到执行次数越多的方法,对这些代码进行优化,JIT编译器目前主要有两类:Client Compiler(C1编译器),Server Compiler(C2编译器)。
2.2.1、C1编译器(Client Compiler)
C1编译器专用于任何类型的客户端应用程序。客户端编译器会尝试尽快优化和编译代码,从而缩短启动时间。
2.2.2、C2编译器(Server Compiler)
C2编译器则是为了长时间运行的服务端应用程序设计的,因为C2编译器会长时间观察和分析代码,并且通过分析结果对编译后端代码进行更好地优化。
一般在客户端程序,我们为了达到更快的启动程序,一般会使用C1编译器,而在服务端,为了从长远考虑提供更好的性能,一般会使用C2编译器。
2.3、JVM进化史
在收集了若干版本的JVM说明,之后汇总概括为如下几个进化阶段。
2.3.1、早期JVM
早期的JVM中,只包含解释器,并不会进行即时编译。The Java HotSpotTM Server Compiler#1. Introduction

2.3.2、支持JIT的JVM
随着对执行效率的要求,逐渐引入了Client Compiler以及Server Compiler,也就是C1和C2编译器,早期这两个编译器是不同的体系结构,所以JVM中会提供两个单独的实现程序,%JAVA_HOME%/jre/bin下面有server和client文件夹,里面分别对应是C2和C1的实现。一次只能使用其中一个编译器,通过-client和-server参数指定。这个时候引入了三种编译模式:
解释执行:该模式下表示全部代码均是解释执行,不做任何JIT编译,如果要开启这种模式,请使用-Xint参数;编译执行:该模式下不管是否热点代码,对所有的函数,都进行编译执行,如果要开启这种模式,请使用-Xcomp参数;混合执行:JVM默认的执行模式,部分函数会解释执行,部分会编译执行。如果函数调用频率高,被反复使用,就会认为是热点代码,该函数就会被编译执行。
至于具体具体的内部模块结构是怎样子的,HotSpot Client编译器的技术领导Tom Rodriguez在2002年的JavaOne大会上做过一次相关分享:Client Compiler for the Java HotSpot™ Virtual Machine ,根据这份PPT,我们梳理下引入了JIT之后的JVM结构图:
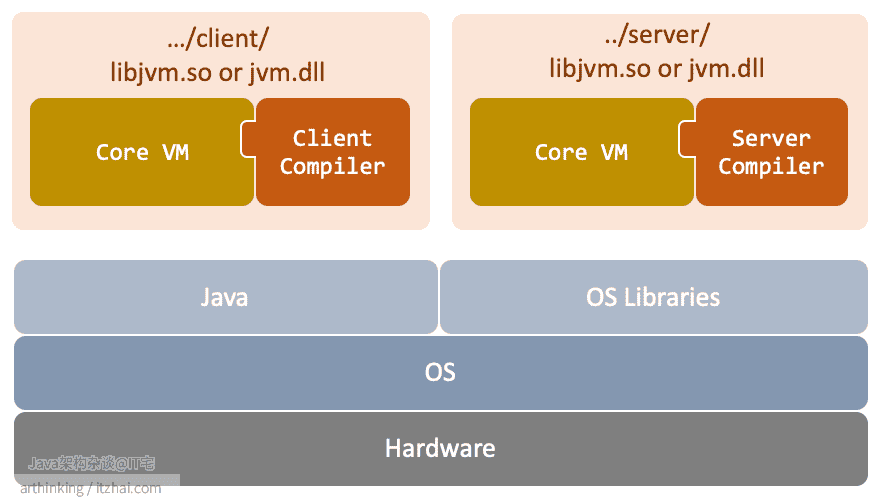
java可执行文件只是一个执行外壳,它会装载jvm.dll(dll为windows下面,Linux下面为so文件,Mac下面为dylib文件)文件,这个动态链接库才是JVM的关键实现。
注意:不同版本的JDK,jvm.so文件目录可能会有所不同。比如Mac系统下
1.8.0_71版本的JDK的server目录:/Contents/Home/jre/lib/server
其中解释器在Core VM中。为了简化模型,这里我们只关注解释器和编译器,如下图:
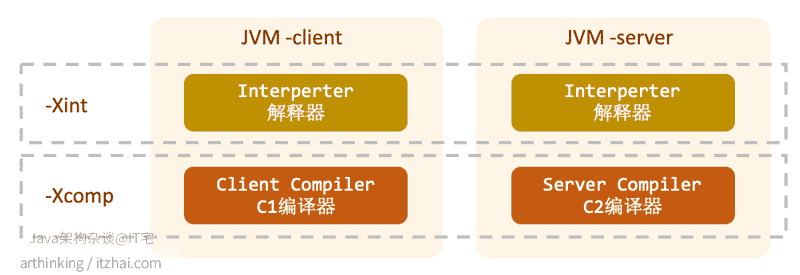
通过-client和-server参数指定运行模式之后,会选择对应的编译器。
为什么我电脑里面的-client参数不生效?
关于默认的工作模式
从J2SE 5.0开始,应用程序启动的时候,会自动检测程序是否在“服务器级别”的计算机上运行,如果是,则默认开启server模式,如果不是,则开启client模式。为的就是提高性能。
一般的检测标准为:对于Java SE 6,服务器级 计算机的定义是至少具有2个CPU和至少2GB物理内存的计算机。
下面是一个具体的列表:
| 架构 | 操作系统 | 默认client | 如果是服务器级为server; 否则为client | 默认为server |
|---|---|---|---|---|
| SPARC 32位 | Solaris | √ | ||
| i586 | Solaris | √ | ||
| i586 | Linux | √ | ||
| i586 | Windows | √ | ||
| SPARC 64位 | Solaris | √ | ||
| AMD64 | Solaris | √ | ||
| AMD64 | Linux | √ | ||
| AMD64 | 微软视窗 | √ |
关于JIT编译器的版本
目前主要由以下三种格式:
- 32位客户端版本(
-client) - 32位服务器版本(
-server) - 64位服务器版本(
-d64)
如果您安装的JDK里面只有64位服务器版本的JIT,那么-client模式就不生效了。可以看看安装目录下面是否有client文件夹,比如MacOS下面64位1.8.0_71JDK,可以发现只有server文件夹:
➜ lib ll | grep -E ‘(server|client)’
drwxrwxr-x 5 root wheel 160 Dec 23 2015 server
所以是不支持32位的client编译器的。
问题:我究竟应该安装32位还是64位的JDK呢?
答案参考:Difference between 32-bit java vs. 64-bit java
2.3.3、支持分层编译的JVM
那么问题来了,是否可以将C1和C2编译器混合使用,以达到从长远来看既有快速启动又具有尽可能好的性能的目的呢?
答案是肯定的,从Java7开始这个功能就诞生了,即分层编译。
在Java8中,默认是启用分层编译的,要想禁用分层编译,可以使用XX:-TieredCompilation。如果要使用分层编译,请务必使用Server模式,Client模式不支持,会自动忽略掉。
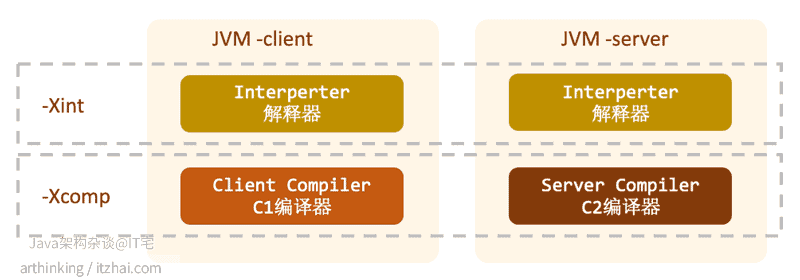
如上图,启动server模式之后,Server Compiler是包含了Client Compiler的功能。
分层编译诞生的小插曲:其实Java 7早期版本中就提供了分层编译的测试版本,但是发现存在许多技术问题,特别是原本两个编译器是在不同体型结构中的,要弄到一起配合工作难度可想而知,该版本性能不佳。不过从Java 7u4版本中得到了解决。这个时候分层编译已经能够为应用程序提供最佳的性能了。
分层编译运行机制
在分层编译中,一开始使用Client编译器来加快启动速度,然后代码变成热点并且启用监控收集运行数据,Server编译器就会根据运行状态重新编译它。
即使Java只有两个基本的编译器:C1,C2,加上解释器,这里也划分为了5个执行级别:

通常执行顺序是:0 -> 3 -> 4。首先进行解释执行代码,然后在代码变成称热点之后,由C1编译,并且启用监控功能。解释执行的时候不用再承担手机性能信息的工作了。最后,C2使用C1收集的监控数据进一步编译代码:
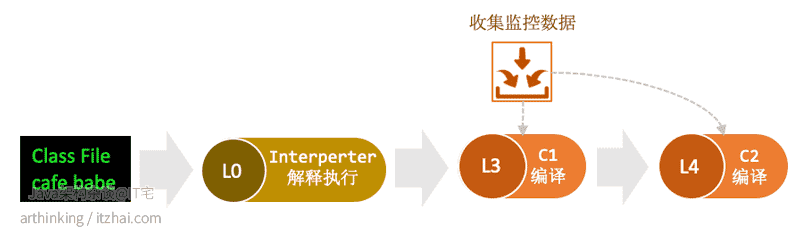
有三个例外:
- 方法太简单了:如果要编译的方法很简单,那么仅在1级别下进行编译,因为C2不会使其更快,这个时候进行大量概要分析找出如何使用代码是没有意义的,反而在1级别下面运行更快;
- C2繁忙中:如果某个时候,C2编译器队列已满,那么会把代码转到2级别进行编译(简单概要分析,可以更快速编译该方法),一段时间后在3级别下编译代码;最后,C2不繁忙的时候,才由C2再次编译;
- C1繁忙中,但是C2空闲:如果C1队列满了,但是C2未满,则可以有解释器概要分析(0级别),然后直接进入C2。
编译器队列不是标注的FIFO,而是优先级队列。
2.4、何时会逆向优化
编译器优化之后,如果后面运行发现优化优化不合理,主要表现为:某一次运行不会执行到之前编译好的本地代码了,或者出现了一些僵尸代码。这个时候会进行逆向优化,退回到解释状态继续执行。
2.5、何时触发编译
HotSpot虚拟机主要通过基于计数器的热点探测方法为每个方法准备两类计数器:方法调用计数器,回边计数器。统计计数器值。
当
方法调用计数器 + 回边计数器 > 方法调用计数器阈值(CompileThreshold,见 15-1 计数器相关参数 表格)
或者
方法调用计数器 + 回边计数器 > 回边计数器阈值
的时候,就分别触发即时编译或者OSR。
2.5.1、方法调用计数器
如果一个方法被反复调用,那么就有可能被认定为是热点代码,从而进行编译。
方法计数器主要用于统计方法调用次数
热度衰减:默认情况下,每次GC时会对调用计数器进行减半的操作,导致有些方法一直达不到触发C2编译的阀值。
2.5.2、回边计数器
如果一个循环体被反复执行,那么循环体所在的方法就有可能被认为是热点代码,从而触发编译。
可能在执行循环过程中就触发了编译,循环代码编译完成后,JVM会立刻替换掉正在执行的代码,下一次循环迭代执行速度更快的编译版本,所以称为栈上替换(On StackReplacement OSR,方法栈帧还在栈上,方法就被替换了),替换过程如下图(来源于Client Compiler for the Java HotSpot™ Virtual Machine):
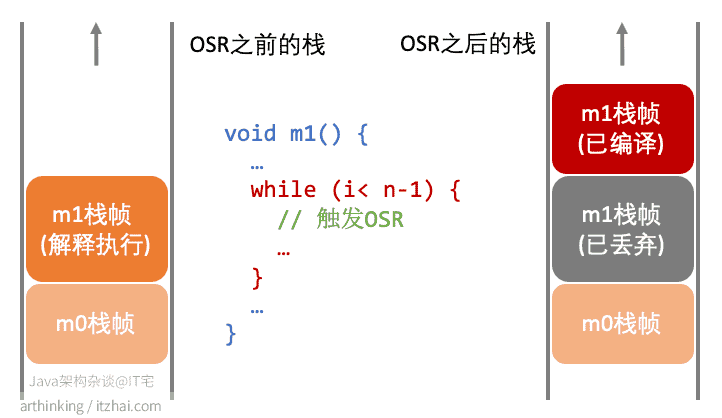
边计数器统计一个方法中执行循环体代码的次数。当一个循环执行到某位,或者执行到了continue语句的时候,就会触发一个回边指令,这个时候回边计数器值就+1。
回边计数器不会热度衰减。
回边计数器阈值计算公式
- client模式
CompileThreshold * (OnStackReplacePercentage / 100)
- server模式
CompileThreshold * ((OnStackReplacePercentage - InterpreterProfilePercentage)/100)
15-1 计数器相关参数
| 计数器 | 配置参数 | 作用 | 默认值 |
|---|---|---|---|
| 方法调用计数器 | -XX:CompileThreshold | 触发编译的方法调用计数器阈值, 方法调用计数器+回边计数器之和超过此值,则触发编译 |
client: 1500 server: 10000 |
| -XX:-UseCounterDecay | 关闭调用计数器的热度衰减 | ||
| -XX:CounterHalfLifeTime | 设定调用计数器的半衰期周期时间,单位秒 | ||
| 回边计数器 | -XX:OnStackReplacePercentage | OSR比例,用该比例可以计算回边计数器阈值 | client: 933 server: 140 |
| -XX:InterpreterProfilePercentage | 解释器监控比例 | 33 |
15-2 编译器相关参数
-
-XX:-TieredCompilation:
- 禁用中间编译层(1, 2, 3),使得方法要么解释执行,要么进行最大级别的优化(C2);
- 副作用是该参数会更改编译器线程数量,编译策略以及默认代码缓存大小。如果禁用了TieredCompilation:
- 编译器线程数将减少
- 将选择简单的编译策略(基于方法调用和后端计数器),而不是高级的编译策略;
- 默认的保留代码缓存大小将减小5倍
- 如果要禁用C2编译器,只保留C1编译器,请设置-XX:TieredStopAtLevel=1
- 要禁用所有的JIT编译器,只使用解释器运行程序,请使用 -Xint
- What exactly does -XX:-TieredCompilation do?
-
-XX:+PrintCompilation
- 打印即时编译信息,具体输出格式说明可以参考:JDK5u22_client.log 或 Working with the JIT Compiler#Inspecting the Compilation Process
- 格式:timestamp compilation_id attributes (tiered_level) method_name size deopt
2.5.3、触发即时编译优化的例子
有如下代码:
1 | public class MonitorCompilation1 { |
我们设置以下启动参数:
-server 启用Server模式
-XX:-TieredCompilation 不启用分层编译
-XX:+PrintCompilation 打印编译日志
-XX:+UnlockDiagnosticVMOptions
-XX:+PrintInlining 打印内联优化信息
-XX:-BackgroundCompilation 不启用后台编译,为了等待编译完成,打印编译日志,然后继续执行
-XX:CompileThreshold=10 触发编译的方法调用计数器阈值
-XX:-UseCounterDecay
以上参数配置,要想触发方法即时编译,方法至少需要被调用10次,但这里只循环调用了9次,并不会触发执行编译,大家可以尝试运行下。
现在我们调整循环次数到10次,执行可以发现打印如下日志:
1 | 7722 554 b com.itzhai.jvm.executeengine.字节码执行引擎.MonitorCompilation1::calcSum (13 bytes) |
可以发现由于calcSum方法被调用多次,其内部的addOne方法调用触发了内联优化。
3、一些关于编译优化的问题
关于JIT做的性能优化工作,可以参考这个wiki:PerformanceTacticIndex
3.1、我们能在 Switch 中使用 String 吗?
这个涉及到javac编译器的解除语法糖。
switch 语句中的变量类型可以是: byte、short、int 或者 char。从 Java SE 7 开始,switch 支持字符串 String 类型了,同时 case 标签必须为字符串常量或字面量。
从 Java 7 开始,我们可以在 switch case 中使用字符串,但这仅仅是一个语法糖。内部实现在 switch 中使用字符串的 hash code。
1 | String test = "abc"; |
1 | 63: invokevirtual #12 // Method java/lang/String.hashCode:()I |
3.2、提炼更多函数不会影响性能?
重构技巧中,最基本的一个就是对于太长的函数,进行提炼函数,但是我们知道,每提炼多一个函数,就多一个方法调用,意味着性能更差,事实真的如此吗?
3.2.1、方法内联
针对非虚方法调用(参考JVM是如何进行方法调用的),JIT编译器会进行内联处理,去掉方法调用。如下例子:
1 | public static void innerTest() { |
执行之后,查看输出的编译优化日志,可以看到:
1 | 8901 594 % b com.itzhai.jvm.executeengine.字节码执行引擎.MethodInlineOptimization::execute @ 2 (19 bytes) |
可以发现,innerTest方法做了内联优化。
3.2.2、虚方法的内联优化
针对虚方法,由于是动态分派,只有运行时才知道究竟会调用哪个方法,所以不好做内联优化,但是JVM的编译器还是会做一些优化:
- 如果检查到实际的实现目标版本只有一个,那么就会进行内联优化;后续如果发现执行到了一个新的实现目标版本,那么就取消内联优化,退回解释状态执行;
- 如果存在多个实现版本,JVM也会尝试做内联优化,主要是通过内存缓存实现的。先记录方法接收者缓存,并做内联优化,下次调用的方法接收者变了,那么就取消内联,通过虚方法表进行分派调用。
如下例子:
1 | public interface OperatingSystem { |
编译优化结果,注意注释说明中的编译变化:
1 | // 执行第一个循环,这里对innerTest方法进行了内联优化,内联了Windows::startUp |
关于
made not entrant,参考:PrintCompilation JVM flag
所以说,在代码里面那些getter,setter方法以及非虚方法调用,编译器是会进行内联处理的,针对虚方法,也会根据实际监控的运行数据做最大程度的优化,总体上还是做了很多性能优化,大家还是要重构方法,提高代码质量:
- 保证方法尽可能简单,单一职责;为下一步抽象优化做好准备;
- 抽取的方法越小,越容易被JVM做内联优化。
不能因为这个借口而写出糟糕的长方法。
3.3、不用的Java对象究竟需不需要设置为null
大家知道,在JVM中,为了尽可能节省栈帧的空间,本地变量表中的Slot是可以复用的,也就是说,即使离开了方法的作用域,如果Slot没有重新进行写操作,GC Roots会继续保持着对它的关联,就回收不了对应的内存了。
为此,你需要在作用域之后初始化一个新的变量,或者把原来的变量设为null,以去掉GC Roots,方便进行垃圾回收,例子如下:
1 | public class StackFrame { |
执行打印日志发现确实如此:
1 | [GC (System.gc()) 11599K->726K(125952K), 0.0003654 secs] |
回收之后,占用的内存变为了几百k。
但是假如我们这样设置下启动参数,并且把int a = 1注释掉:
1 | -server |
因为这里方法调用计数器阈值为10,而我们代码中是循环调用了10次test方法,执行发现,这样也正常回收了内存。其实这里是JIT帮我们做了优化。
其实并不用太依赖set null,而是通过严格的作用域来控制对象的回收,其他的交给编译器即可。
3.4、怎么写出更快的Java代码?
关于这个问题,我想说,其实大家把更多精力花费在如何写出可扩展性的代码,调代码质量上来会更好。至于代码知道执行效率,让编译器帮我们去优化。
当然常见的优化技巧大家还是要懂的,阿里技术公众号也发过一篇文章介绍如何写出高效:Java工程师该如何编写高效代码?。但是在业务迭代快速发展时期,代码质量比代码效率要求会更高些。
大部分优化技巧还是值得关注的,但是基于代码质量上考虑,其实也不一定要严格按照里面的要求来做,部分优化工作编译器会帮我们实现,比如:
- 3.8、尽量指定方法的final修饰符:这个按照实际情况来即可,如果将来可能会扩展,则没必要限制太死,毕竟对于虚方法编译器也会做最大努力的内联优化,您首先要确保使用final是基于清晰的设计以及可读性考虑。
Java本身为了提升开发效率,就从性能上做了一些妥协:
动态扩展:Java支持动态扩展,导致编译器即使做了优化,也可能会因为后期动态扩展导致执行目标发生变化,从而导致逆优化;动态安全:虚拟机需要频繁的进行动态检查,即使经过了JIT编译,也会消耗不少时间;虚方法:Java语言提倡使用面向对象编程,多态会导致很多的虚方法,不可避免的增加了编译器的优化难度。
开发效率与执行效率之间的权衡,需要根据实际业务场景来做。
更多关于如何写出更快的Java代码的建议,欢迎大家多讨论交流。
References
《深入理解Java虚拟机-JVM高级特性与最佳实践》
《Java Performance: The Definitive Guide》
What exactly does -XX:-TieredCompilation do?
Client, Server, and Tiered Compilation
Chapter 4. Working with the JIT Compiler
The Java HotSpotTM Server Compiler
虚拟机随谈(一):解释器,树遍历解释器,基于栈与基于寄存器,大杂烩
Client Compiler for the Java HotSpot™ Virtual Machine

