

7、优先级队列PQ
优先级队列是一种抽象数据类型(ADT),其操作类似于普通队列,不同之处在于每个元素都具有特定的优先级。 优先级队列中元素的优先级决定了从PQ中删除元素的顺序。
注意:优先级队列仅支持可比较的数据,这意味着插入优先级队列的数据必须能够以某种方式(从最小到最大或从最大到最小)进行排序。 这样我们就可以为每个元素分配相对优先级。
为了实现优先级队列,我们必须使用到堆 Heap。
7.1、什么是堆
堆是基于树的非线性结构DS,它满足堆不变式:
- 堆中某个节点的值总是不大于或不小于其父节点的值;
二叉堆是一种特殊的堆,其满足:
- 是一颗完全二叉树[^2]。
将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
在同级兄弟或表亲之间没有隐含的顺序,对于有序遍历也没有隐含的顺序。
堆通常使用隐式堆数据结构实现,隐式堆数据结构是由数组(固定大小或动态数组)组成的隐式数据结构,其中每个元素代表一个树节点,其父/子关系由其索引隐式定义。将元素插入堆中或从堆中删除后,可能会违反堆属性,并且必须通过交换数组中的元素来平衡堆。
7.2、使用场景
- 在Dijkstra最短路径算法的某些实现中使用;
- 每当您需要动态获取“最佳”或“次佳”元素时;
- 用于霍夫曼编码(通常用于无损数据压缩);
- 最佳优先搜索(BFS)算法(例如A*)使用PQ连续获取下一个最有希望的节点;
- 由最小生成树(MST)算法使用。
7.3、最小堆转最大堆
问题:大多数编程语言的标准库通常只提供一个最小堆,但有时我们需要一个最大PQ。
解决方法:
- 由于优先级队列中的元素是可比较的,因此它们实现了某种可比较的接口,我们可以简单地取反以实现最大堆;
- 也可以先把所有数字取反,然后排序插入PQ,然后在取出数字的时候再次取反即可;
7.4、实现思路
优先级队列通常使用堆来实现,因为这使它们具有最佳的时间复杂性。
优先级队列是抽象数据类型,因此,堆并不是实现PQ的唯一方法。 例如,我们可以使用未排序的列表,但这不会给我们带来最佳的时间复杂度,以下数据结构都可以实现优先级队列:
- 二叉堆;
- 斐波那契堆;
- 二项式堆;
- 配对堆;
这里我们选取二叉堆来实现,二叉堆是一颗完全二叉树[^2]。
7.4.1、二叉堆排序映射到数组中
二叉堆索引与数组一一对应:
二叉堆排好序之后,即按照索引填充到数组中:
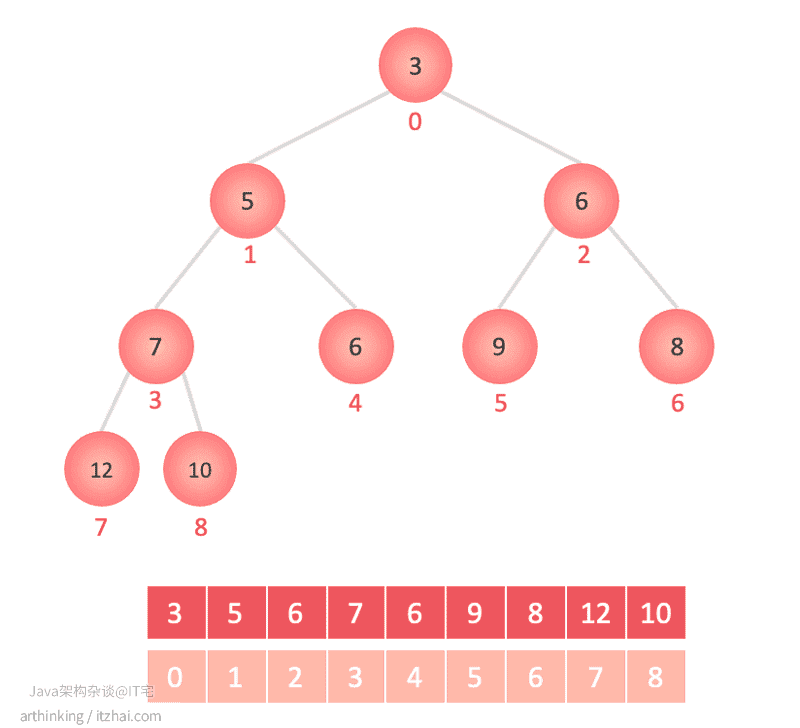
索引规则:
- i节点左叶子节点:2i + 1
- i节点右叶子节点:2i + 2
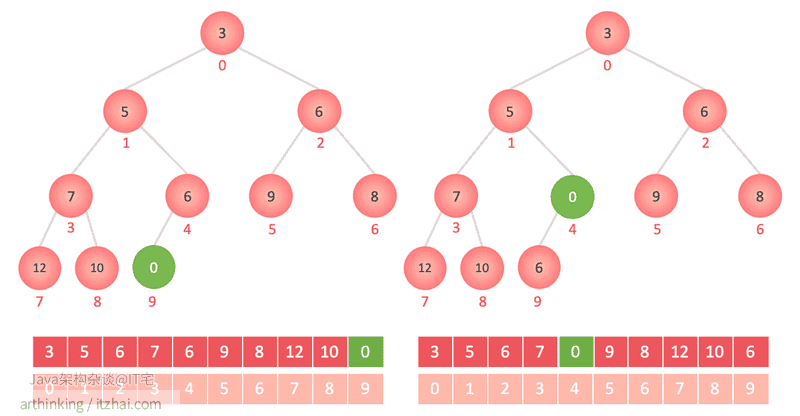
7.4.2、添加元素到二叉堆
insert(0)
如下图,首先追加到最后一个节点,然后一层一层的跟父节点比较,如果比父节点小,则与父节点交换位置。
7.4.3、从二叉堆移除元素
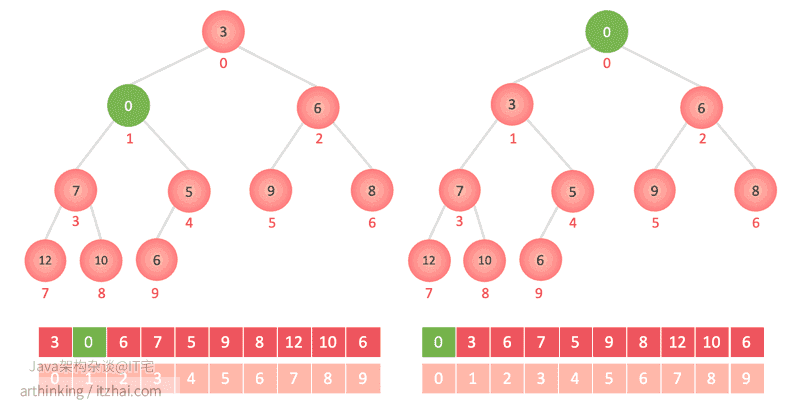
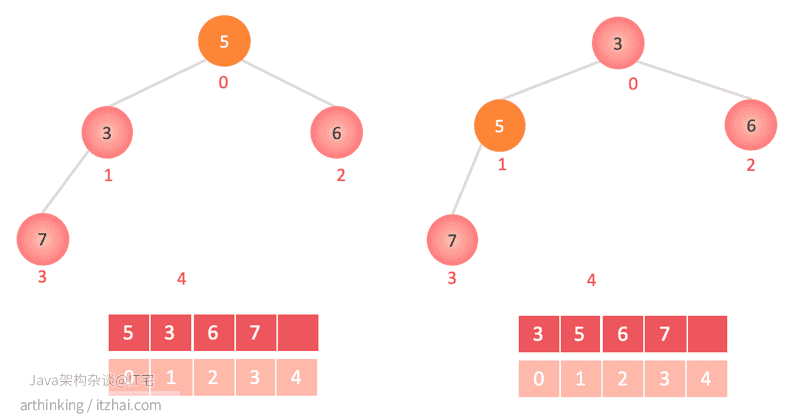
poll() 移除第一个元素
-
第一个元素与最后一个元素交换位置,然后删除掉最后一个元素;
-
第一个元素尝试sink 下沉操作:一直与子节点对比,如果大于任何一个子节点,则与该子节点对换位置;
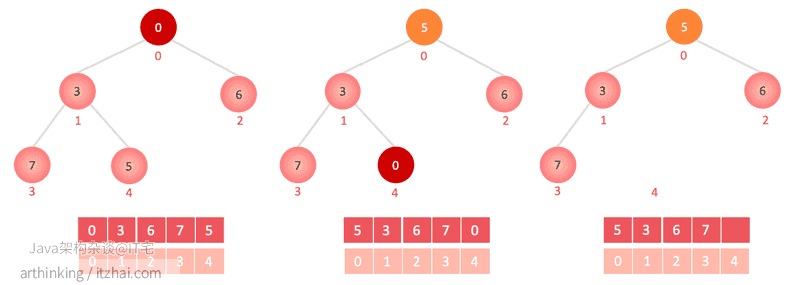
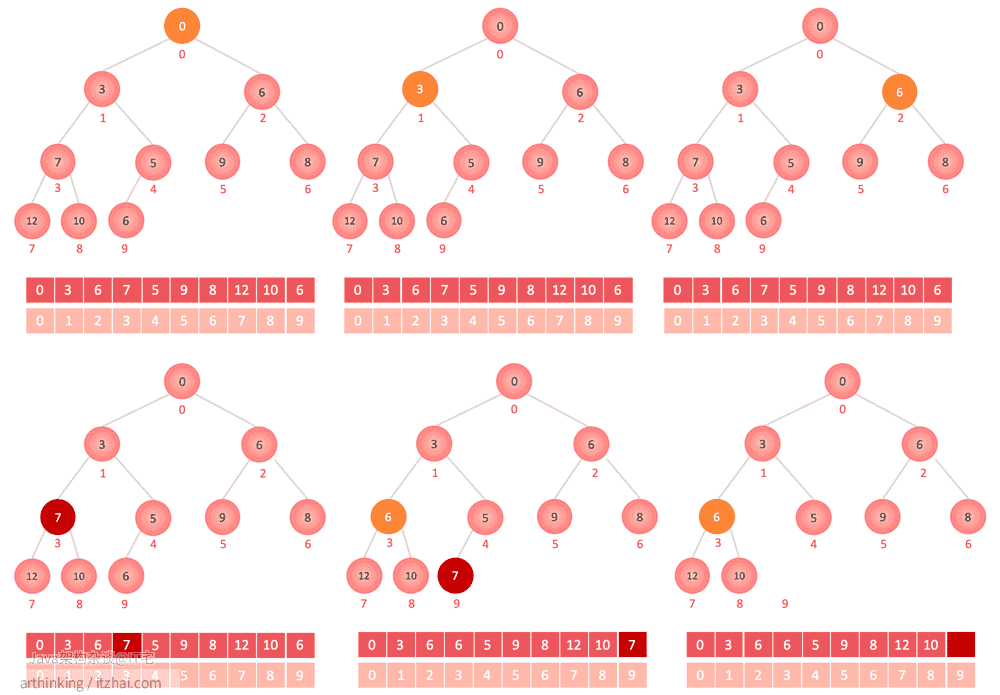
remove(7) 移除特定的元素
-
依次遍历数组,找到值为7的元素,让该元素与最后一个元素对换,然后删除掉最后一个元素;
-
被删除索引对应节点尝试进行sink 下沉操作:与所有子节点比较,判断是否大于子节点,如果小于,那么就与对应的子节点交换位置,然后一层一层往下依次对比交换;
-
如果最终该元素并没有实际下沉,那么尝试进行swim 上浮操作:与父节点比较,判断是否小于父节点,如果是则与父节点对换位置,然后一层一层往上依次对比交换;
思考:请问如何构造一个小顶堆呢?
遍历数组,所有元素依次与子节点对比,如果大于子节点则交换。
7.5、尝试让删除操作时间复杂度变为O(log(n))
以上删除算法的效率低下是由于我们必须执行线性搜索**O(n)**以找出元素的索引位置。
**我们可以尝试使用哈希表进行查找以找出节点的索引位置。**如果同一个值在多个位置出现,那么我们可以维护一个特定节点值映射到的索引的Set或者Tree Set中。
数据结构如下:
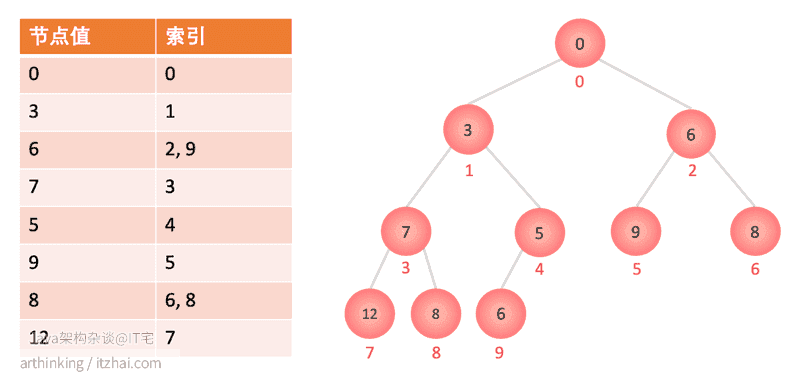
这样我们在删除的时候就可以通过HashTable定位到具体的元素了。
7.6、时间复杂度
| 操作 | 时间复杂度 |
|---|---|
| construction | O(n) |
| poll | O(log(n)) |
| peek | O(1) |
| add | O(log(n)) |
| remove | O(n) |
| remove with a hash table | O(log(n)) |
| contains | O(n) |
| contains with a hash table | O(1) |
7.7、编程实践
- JDK中的实现:
java.util.PriorityQueue - 基于最小堆实现的优先级队列 BinaryHeap
- 最小堆实现的优先级队列,优化了删除方法

