


基于前面的消息队列文章,我们对消息队列发展历史有了一个比较全面的了解,并且最主流的两款消息队列:RabbotMQ和RocketMQ的用法,使用场景,常见问题以及解决方法,原理都有了比较深入的了解:
很高兴博客园把这两篇文章都首页置顶推荐了,看来大家对消息队列的知识还是比较感兴趣的。有网友提到RabbitMQ受限于开发语言,比较难以一探究竟,而RocketMQ对于Java开发人员来说更加触手可得。在发表了RocketMQ的文章之后,有几个网友反馈可否出一篇Kafka的文章,所以我就写了这篇文章。那么话不多说,我们开始吧。
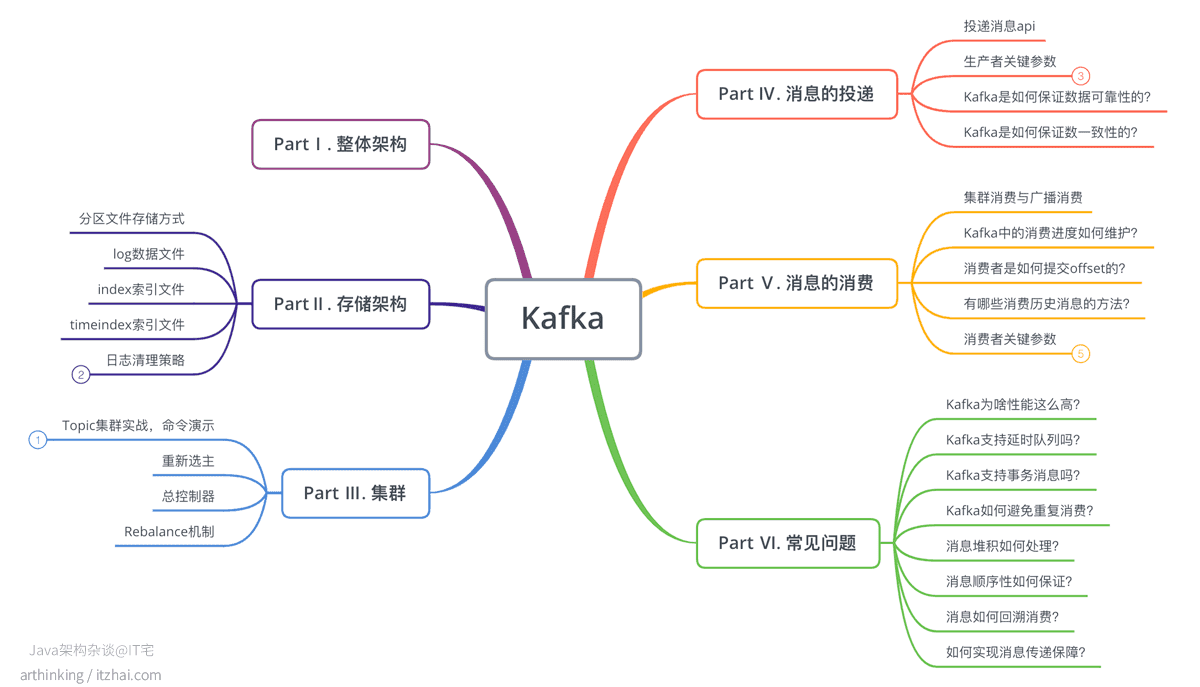
本文将带您了解以下问题:
- Kafka是如何存储和检索消息的?(log文件,index索引文件,timeindex索引文件)
- Kafka是如何基于offset查找消息的?
- Kafka有哪些日志清理策略?什么场景下会用到?
- ISR是干嘛的?
- Kafka总控制器是干嘛的?如何选举出来的?
- Topic的最优Leader副本是如何选举出来的?
- 什么时候会触发消费的Rebalace?Kafka中有哪些Rebalance策略?
- Rebalance是如何工作的?
- Kafka是如何保证数据可靠性的?
- Kafka是如何保证数据一致性的?
- 消费者是如何提交offset的?
- 有哪些消费历史消息的方法?
- Kafka为啥性能这么高?
- Kafka如何避免重复消费?
- Kafka如何处理消息堆积?
- 如何保证消息顺序性?
- Kafka如何实现消息传递保障?
- Kafka有哪些关键的生产者和消费者参数?
- …
本文主要内容:
Kafka是一个分布式实时事件流平台,主要提供了关键功能:
- 发布和订阅事件流,事件记录被存储起来,因此消费应用程序可以提取他们需要的信息,并跟踪历史保存的所有消息;
- 支持高吞吐量;
- 可以弹性和透明的扩容,无需停机;
- 将事件流存储在磁盘上,并在分布式集群中实现多副本存储,以实现容错,支持配置事件记录数据存储的时长;
- 基于Zookeeper的同步控制器,以保持主题、分区和元数据的高可用(不过在2.8版本之后,可以使用基于 Kafka Raft 的 Quorm 控制器取代基于Zookeeper的控制器)。
如果对Kafka不是很了解,看到上面功能列表,大家可能会比较茫然,不过没关系,接下来的文章保证给大家彻底讲明白,一看就懂,看不懂就当我没说。
下面看看Kafka的整体架构以及关键组件。

